Clear Sky Science · pt
RFGLNet para segmentação semântica generalizada por domínio em clima adverso com aprimoramento de baixa posto na frequência
Enxergando a estrada quando o tempo piora
Carros autônomos e robôs de entrega prometem ruas mais seguras e eficientes — mas somente se conseguirem “ver” o mundo ao redor de forma confiável. Chuva, neblina, neve e noites escuras tornam essa visão extremamente difícil, apagando contrastes, adicionando pontos de ruído e borrando as bordas de pessoas, carros e meios-fio. Este artigo apresenta o RFGLNet, um novo sistema de visão computacional projetado para manter o entendimento da máquina sobre a estrada preciso mesmo quando o clima está no seu pior.

Por que o mau tempo cega as máquinas
Os sistemas de direção autônoma de hoje frequentemente dependem de um processo chamado segmentação semântica, no qual um algoritmo atribui uma classe — como estrada, carro, pedestre ou prédio — a cada pixel de uma imagem. Em dia claro, redes neurais modernas fazem isso de forma notável. Em chuva forte ou neblina densa, contudo, as imagens perdem brilho, ganham ruído e desenvolvem contornos borrados entre objetos. Coletar e rotular conjuntos massivos de dados para cada condição meteorológica adversa é proibitivamente caro, então a maioria dos sistemas é treinada principalmente em imagens normais e ensolaradas. Quando enfrentam tempestades ou neve não vistas antes, o desempenho cai acentuadamente. Correções anteriores tentaram limpar as imagens primeiro e depois segmentá-las, ou adaptar modelos a condições-alvo específicas. Ambas as abordagens tendem a ser frágeis, lentas ou dependentes demais de dados rotulados em mau tempo.
Uma nova rede construída para condições difíceis
O RFGLNet aborda esse problema com uma estratégia diferente: aprende apenas a partir de cenas urbanas diurnas padrão, mas generaliza para uma ampla gama de condições adversas. Os autores partem do DINOv2, um grande modelo visual pré-treinado conhecido por capturar estrutura rica das cenas. Em vez de retreinar esse backbone pesado do zero, eles congelam seus parâmetros e adicionam um conjunto leve de módulos por cima. Esses módulos funcionam como adaptadores inteligentes, remodelando as representações internas do backbone para que fiquem menos confusas com a desordem visual causada por flocos de neve, gotas de chuva ou escuridão. O resultado é um sistema que usa apenas 4,32 milhões de parâmetros treináveis — pequeno em comparação com modelos típicos de visão — enquanto ainda aprende a lidar com climas nunca vistos durante o treinamento.
Como a rede aprende a filtrar o clima
A primeira inovação do RFGLNet é um módulo de baixa posto que se integra a cada camada do backbone congelado. Antes do treinamento, esse módulo executa um procedimento matemático conhecido como decomposição em valores singulares em uma matriz de características simulada. Isso fornece um conjunto de componentes compactos que combinam aproximadamente com a estrutura das características internas do DINOv2 desde o início, em vez de começar a partir de ruído aleatório. Durante o treinamento, esses componentes são ajustados, permitindo que o módulo corrija suavemente as características do backbone para a nova tarefa sem perturbar seu conhecimento central. A rede então aplica um bloco de atenção baseado em Fourier que transfere as características para o domínio da frequência. Nesse domínio, estruturas largas e de variação lenta tendem a representar objetos significativos, enquanto padrões agudos e erráticos frequentemente correspondem ao ruído meteorológico. Suprimindo a desordem de alta frequência e amplificando componentes mais suaves, o sistema fortalece a compreensão global da cena enquanto reduz interferências.
Afiando detalhes sem se distrair
Mesmo com características globais mais limpas, detalhes pequenos como marcações de faixas, trilhos de cercas e o contorno de um pedestre distante permanecem vulneráveis ao desfoque em clima adverso. Para isso, os autores introduzem um módulo de atenção espacial agrupada na parte do decodificador da rede. Em vez de tratar todos os canais de característica juntos, ele os divide em grupos e aprende mapas de pesos espaciais separados para cada grupo. Canais que carregam estrutura importante, como bordas, podem então ser enfatizados, enquanto canais dominados por ruído são atenuados. Esses mapas específicos de grupo são fundidos em uma ponderação espacial global que realça detalhes finos e acentua limites de objetos em múltiplas resoluções. Na prática, o RFGLNet aprende onde olhar de perto e onde ignorar pontos distrativos de névoa ou chuva.
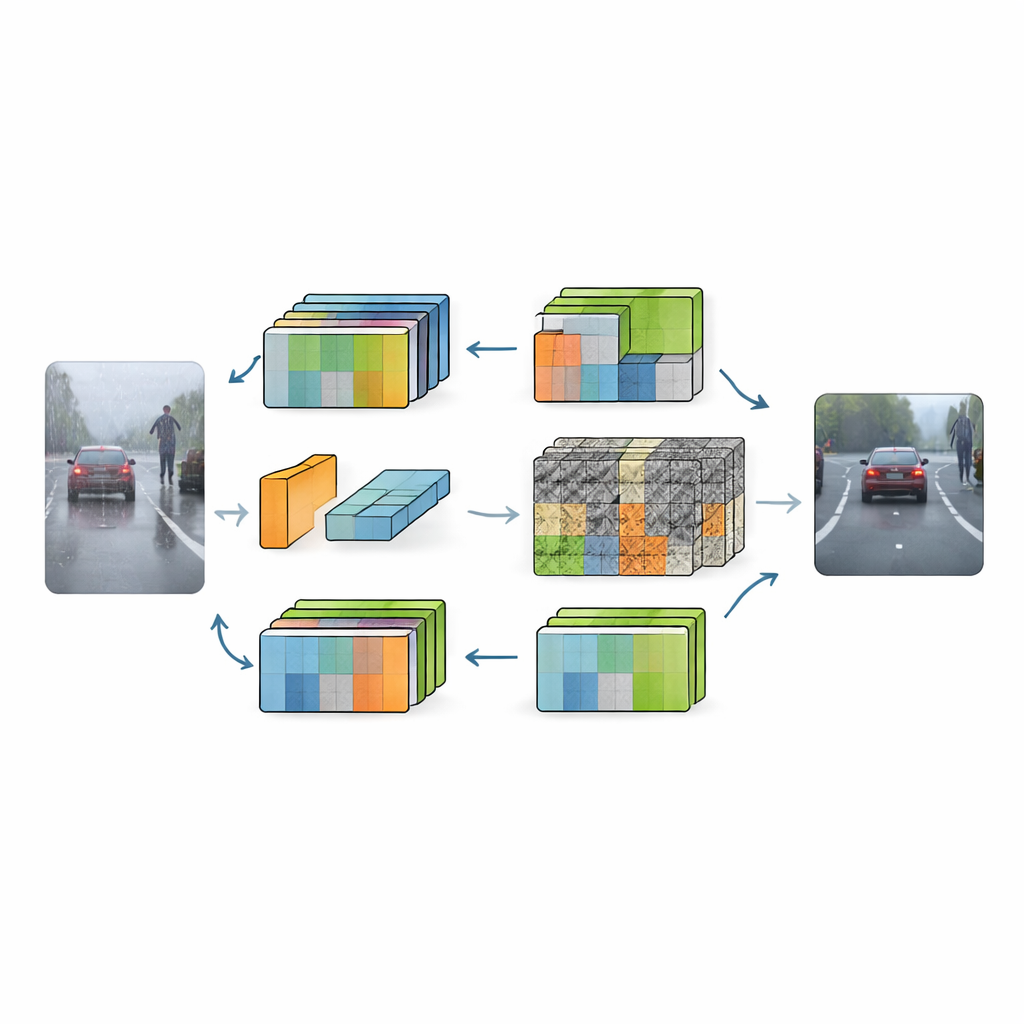
Resultados concretos em cenas rodoviárias desafiadoras
Para testar a abordagem, os pesquisadores treinaram o RFGLNet no conhecido conjunto Cityscapes de cenas urbanas diurnas claras e depois o avaliaram no conjunto ACDC, que foca em condução na chuva, neve, neblina e à noite. Sem nunca ver rótulos do ACDC durante o treinamento, o RFGLNet atingiu uma média de intersection over union de 78,3% — superando vários métodos de generalização de domínio e adaptação líderes, muitos dos quais são maiores e mais exigentes computacionalmente. Foi especialmente eficaz em segmentar classes difíceis como muros e cercas, cujas bordas se perdem facilmente em tempo adverso. Ao mesmo tempo, o modelo rodou de forma eficiente em uma GPU de consumo, processando dezenas de imagens por segundo, um requisito chave para sistemas de direção em tempo real.
Visão mais clara para uma autonomia mais segura
Para não especialistas, a conclusão é que o RFGLNet demonstra como atualizar backbones de visão existentes para autonomia mais segura sem retreinamentos intermináveis para cada tempestade possível. Ao combinar ajuste compacto de baixa posto, filtragem de ruído baseada em frequência e atenção espacial agrupada, o sistema aprende a preservar a estrutura essencial da cena enquanto varre a desordem relacionada ao clima. À medida que esses métodos amadurecem e são treinados em coleções mais amplas de condições do mundo real, eles podem ajudar carros e robôs autônomos a manter uma percepção situacional confiável quando o céu escurece e a estrada à frente está longe de ser clara.
Citação: Ye, X., Shi, X. & Li, Y. RFGLNet for adverse weather domain-generalized semantic segmentation with frequency low-rank enhancement. Sci Rep 16, 8253 (2026). https://doi.org/10.1038/s41598-026-39052-y
Palavras-chave: condução autônoma, percepção em clima adverso, segmentação semântica, robustez em visão computacional, generalização de domínio