Clear Sky Science · pt
Grandes modelos de linguagem exibem efeitos semelhantes ao Dunning-Kruger na checagem de fatos multilíngue
Por que a checagem de fatos inteligente importa para todos
A desinformação agora se espalha mais rápido do que nunca, moldando o que as pessoas acreditam sobre saúde, política, ciência e a vida cotidiana. Muitas plataformas e redações estão começando a recorrer à inteligência artificial — especialmente grandes modelos de linguagem, ou LLMs — para ajudar a verificar se afirmações virais são verdadeiras ou falsas. Este estudo faz uma pergunta aparentemente simples, porém crucial: quando deixamos esses sistemas julgarem fatos, com que frequência eles estão certos, com que segurança agem e isso muda entre diferentes línguas e regiões do mundo?
Como os pesquisadores testaram a IA contra boatos do mundo real
Em vez de inventar exemplos artificiais, os autores construíram seus testes a partir de 5.000 alegações genuínas que organizações profissionais de checagem de fatos ao redor do mundo já haviam investigado. Essas alegações cobriam 47 idiomas e vieram tanto do Norte Global quanto do Sul Global, refletindo a realidade multicultural e desordenada dos boatos online. Só foram incluídas declarações com vereditos claros de "verdadeiro" ou "falso" — concordados por múltiplos checadores de fatos — criando um sólido padrão de referência para comparação.
Em seguida, eles executaram nove modelos de linguagem amplamente usados, desde sistemas open-source menores até modelos comerciais avançados, em cada alegação. Para espelhar como as pessoas realmente conversam com chatbots, a maioria dos prompts eram perguntas simples como “Isso é verdade?” ou “Isso é falso?”, escritas no mesmo idioma da alegação. Uma quarta configuração, mais profissional, usou uma instrução detalhada em inglês que transformava o modelo em um verificador virtual de fatos e pedia saídas estruturadas. Anotadores humanos leram cuidadosamente as respostas dos modelos e as rotularam como afirmando que a alegação era verdadeira, falsa ou recusando-se a dar um veredicto claro.
Medindo não apenas certo ou errado, mas também quando dizer “não sei”
A equipe fez mais do que contar acertos e erros. Eles usaram três medidas-chave para capturar o comportamento dos modelos. Primeiro, a “precisão seletiva” analisou com que frequência um modelo estava correto quando realmente tomava posição e declarava uma alegação verdadeira ou falsa. Segundo, a “precisão favorável à abstenção” considerou aceitável — e até desejável — que o modelo admita incerteza em vez de chutar, algo vital em áreas sensíveis como medicina ou eleições. Terceiro, a “taxa de certeza” acompanhou com que frequência um modelo dava uma resposta definitiva, servindo como um indicador aproximado de quão confiante ele se comportava.
O prompt de estilo profissional, com sua orientação passo a passo, elevou consistentemente a precisão em todos os modelos. Mas também expôs um trade-off: modelos menores frequentemente se tornaram mais decisivos sem se tornarem mais confiáveis, enquanto modelos maiores usaram a estrutura para dar menos respostas, porém melhores. Prompts cotidianos, no estilo de bate-papo, produziram um comportamento mais cauteloso, especialmente em modelos mais fracos, mas também reduziram um pouco sua precisão.
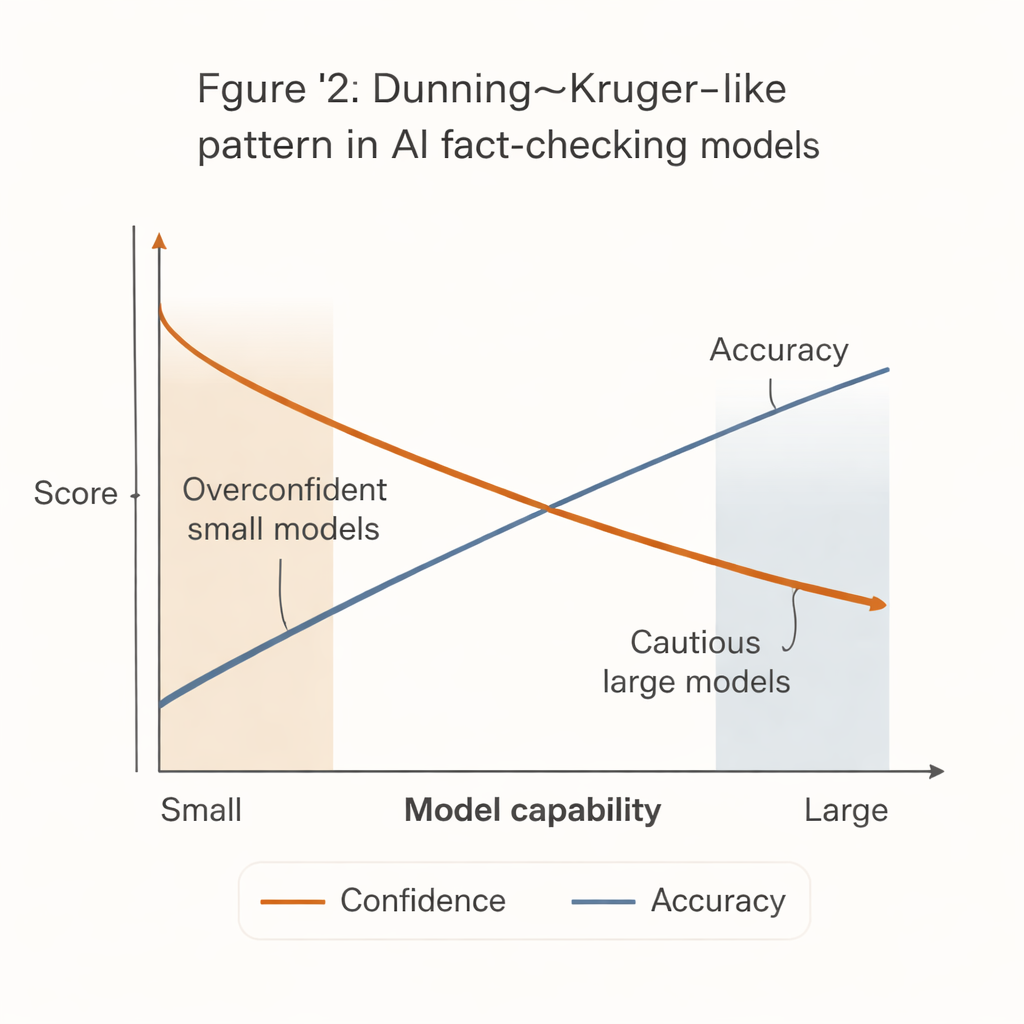
Quando sistemas menos capazes agem com maior convicção
Surgiu um padrão marcante que espelha o conhecido efeito Dunning–Kruger na psicologia humana: os sistemas menos capazes agiam com mais confiança. Modelos pequenos e baratos tendiam a emitir vereditos firmes na grande maioria das alegações, mas com precisão visivelmente menor. Em contraste, os modelos mais potentes — como versões avançadas do GPT — foram muito mais precisos quando se comprometiam, mas muito mais propensos a se absterem, especialmente em afirmações difíceis ou ambíguas.
Essa “lacuna confiança–competência” tem consequências no mundo real. Muitas redações com orçamento apertado, grupos da sociedade civil e centros locais de checagem de fatos não podem pagar os sistemas de IA mais potentes. Eles têm maior probabilidade de adotar modelos menores e mais baratos que parecem decisivos, mas erram com mais frequência. Se essas ferramentas forem integradas a fluxos de trabalho ou sistemas de moderação comunitária sem salvaguardas cuidadosas, elas podem, de fato, ampliar a desinformação ao produzir checagens de fatos confiantes, porém incorretas.
Desempenho desigual entre línguas e regiões
O estudo também revela que esses sistemas não têm desempenho igual para todos. Em várias línguas principais, os modelos geralmente se saíram melhor em alegações em inglês e um pouco pior em português e hindi. Modelos maiores tendiam a responder com mais cautela em línguas não inglesas, mas ainda assim superaram os menores em precisão. Quando os autores compararam alegações ligadas ao Norte Global e ao Sul Global, a maioria dos modelos teve mais dificuldade com estas últimas. Sistemas menores frequentemente permaneciam confiantes enquanto perdiam precisão, ao passo que modelos grandes mostraram quedas maiores na certeza, mas quedas menores na correção, sugerindo que percebiam sua própria incerteza e se continham.
O que isso significa para o futuro de ferramentas de IA confiáveis
Para um não-especialista, a mensagem central é clara: os verificadores de fatos por IA de hoje estão longe de ser iguais, e os mais acessíveis podem ser os mais enganosos. Modelos poderosos podem ser cautelosos e precisos, mas são caros e às vezes excessivamente hesitantes. Modelos mais fracos são ousados, mas têm maior probabilidade de erro, especialmente fora do inglês e em histórias do Sul Global. Os autores argumentam que a IA deve apoiar, e não substituir, checadores humanos de fatos, e que escolhas de política e de design precisam promover melhor calibração — ensinar os sistemas quando permanecer em silêncio — e acesso mais justo a ferramentas de alta qualidade. Caso contrário, a mesma tecnologia construída para combater a desinformação pode aprofundar as desigualdades informacionais que pretende resolver.
Citação: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Palavras-chave: desinformação, checagem de fatos, grandes modelos de linguagem, confiança em IA, viés multilíngue