Clear Sky Science · pt
Uma estratégia de controle humanoide baseada em aprendizado por reforço profundo para maior conforto em robôs de reabilitação de membros inferiores
Robôs que ajudam as pessoas a caminhar novamente
Quando alguém tem dificuldade para andar após um AVC ou uma lesão medular, a terapia pode ser lenta, cansativa e desconfortável. Robôs de reabilitação de membros inferiores são projetados para apoiar e guiar as pernas do paciente durante a prática, mas as máquinas atuais frequentemente parecem rígidas e “robóticas”. Este estudo investiga como dotar esses robôs de um cérebro mais humano — usando algoritmos avançados de aprendizado — pode tornar o treinamento mais suave, mais natural e, em última instância, mais eficaz para os pacientes.
Por que a prática de andar precisa parecer natural
À medida que as populações envelhecem, mais pessoas vivem com problemas sérios de locomoção, e muitas recorrem à reabilitação assistida por robôs. Robôs tradicionais seguem trajetórias preprogramadas para as pernas e usam regras de controle simples para mover as juntas. Embora confiáveis, esses métodos têm dificuldade com a realidade complexa do movimento humano: a marcha de cada pessoa é um pouco diferente, e um robô rígido pode puxar ou empurrar de maneiras que parecem estranhas ou até dolorosas. Os autores argumentam que, para a reabilitação funcionar bem, o robô deve não apenas manter o paciente ereto e em movimento, mas também adaptar-se aos padrões naturais de caminhada e minimizar as forças que exerce sobre o corpo.
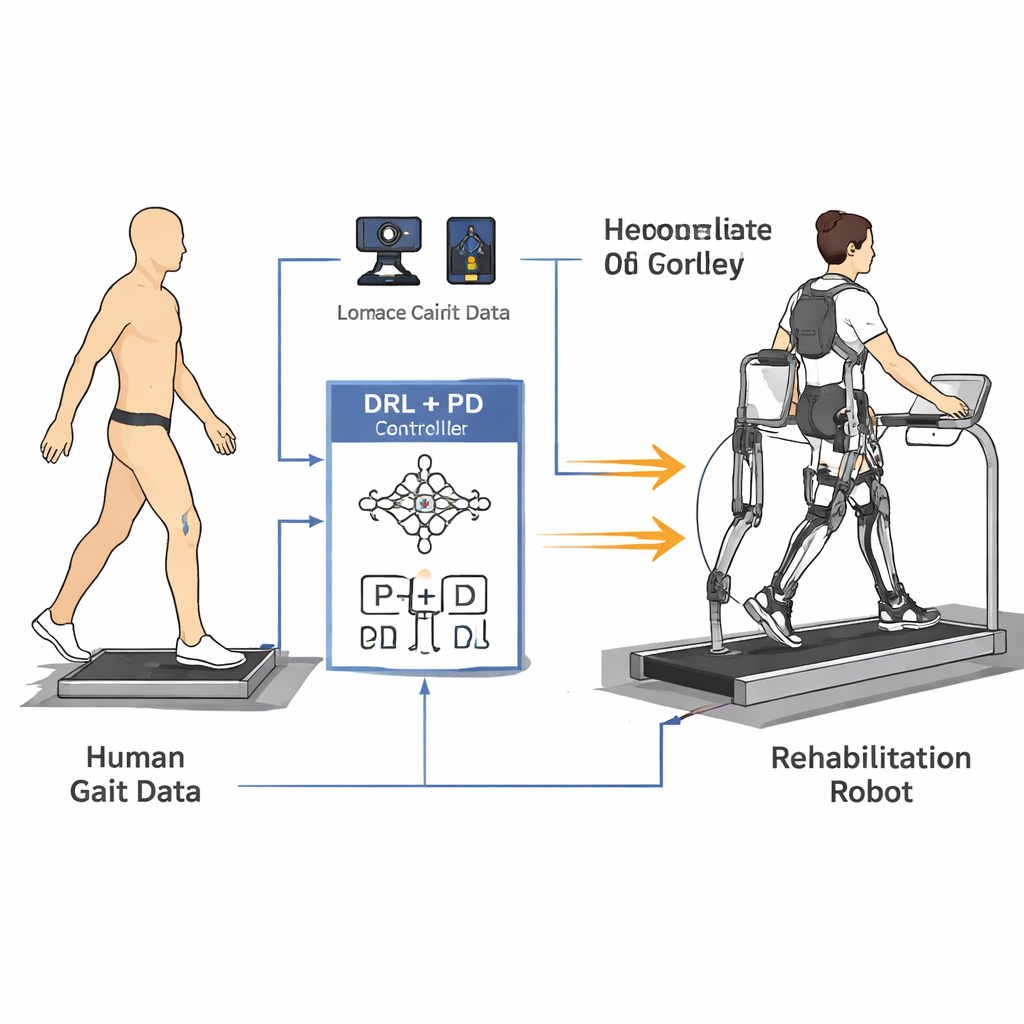
Aprendendo com passos humanos reais
Para ensinar o robô a forma como as pessoas realmente caminham, os pesquisadores primeiro construíram um modelo matemático simplificado das pernas e do tronco. Em seguida, registraram dados de marcha de cinco voluntários saudáveis usando um sistema de captura de movimento 3D de alta precisão e plataformas de força no chão. Marcadores refletivos nos quadris, joelhos, tornozelos e tronco permitiram calcular como cada articulação se movia ao longo de um passo completo, enquanto sensores sob os pés mediam a pressão de cada perna contra o solo. A partir dessas medições, criaram curvas de referência suaves para os ângulos do quadril e do joelho e acompanharam como as forças nas articulações variavam ao longo do tempo, capturando tanto a forma quanto o ritmo da caminhada normal.
Um controlador mais inteligente que ainda preserva a segurança
O cerne do artigo é uma nova estratégia de controle “humanoide” que combina aprendizado por reforço profundo (DRL) com um controlador proporcional-derivativo (PD) clássico. DRL é um tipo de inteligência artificial no qual um agente virtual testa ações, observa os resultados e gradualmente descobre o que funciona melhor ao maximizar um sinal de recompensa. Neste caso, o agente atua sobre o controlador PD: ele observa os ângulos e velocidades das articulações do robô e decide quais torques aplicar, enquanto a camada PD garante que as articulações não se desviem muito de ângulos-alvo seguros e semelhantes aos humanos. A função de recompensa é cuidadosamente elaborada para incentivar uma marcha estável para frente ao passo que penaliza qualquer coisa que pudesse ser desconfortável para um paciente — como movimentos bruscos, forças elevadas nas articulações ou posturas inseguras, como inclinação excessiva ou baixa elevação dos pés.
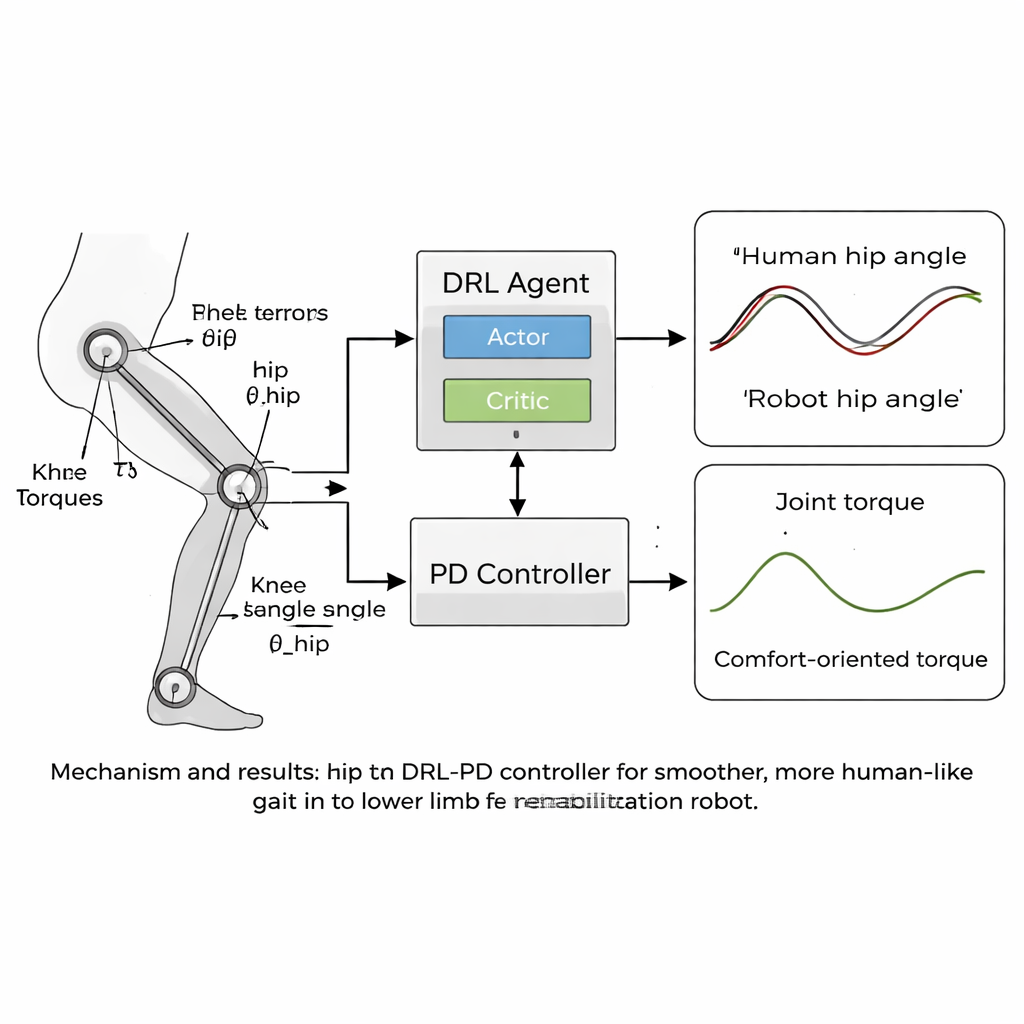
Movimento mais suave, mais próximo de uma marcha humana
A equipe testou sua abordagem em simulações computacionais usando um modelo de robô de reabilitação de membros inferiores com articulações do quadril e do joelho compatíveis com seus dados de marcha. Ao longo de milhares de episódios de treinamento, o controlador DRL-PD aprendeu a produzir um ciclo de caminhada repetitivo no qual os ângulos das articulações seguiam de perto os padrões de referência humanos. Os quadris e joelhos do robô moveram-se em laços regulares e estáveis, sinal de uma marcha confiável e repetível. De forma crucial, os torques necessários para acionar as articulações tornaram-se mais suaves e menores em comparação com um controlador PD padrão. Medidas quantitativas mostraram que os erros de rastreamento caíram para apenas alguns centésimos de radiano, e a taxa de variação dos torques nas articulações — um indicativo de quão “bruscas” as forças seriam para um paciente — foi reduzida em mais da metade. O controlador também permaneceu estável mesmo quando as massas das pernas do modelo foram variadas em alguns por cento, sugerindo que ele poderia tolerar diferenças do mundo real entre usuários.
O que isso significa para os futuros robôs de reabilitação
Para não especialistas, a mensagem principal é direta: ao permitir que um robô aprenda os ritmos e limites da marcha humana a partir de dados reais, e ao recompensá-lo por ser suave e gentil, podemos projetar máquinas que ajudam as pessoas a praticarem a caminhada de forma mais natural e menos estressante. Os pacientes podem ficar mais dispostos a participar de sessões mais longas e mais frequentes se o robô se mover junto com eles em vez de contra eles. Embora os resultados atuais venham de simulações e exijam computadores potentes para o treinamento, uma vez concluído o aprendizado o controlador pode rodar de forma eficiente em dispositivos reais. Os autores veem este trabalho como um passo rumo a robôs de reabilitação personalizados e adaptativos que se ajustem à marcha e às necessidades de conforto de cada paciente, potencialmente melhorando tanto a recuperação quanto a qualidade de vida.
Citação: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Palavras-chave: robôs de reabilitação, treinamento da marcha, aprendizado por reforço profundo, exoesqueleto, conforto do paciente