Clear Sky Science · pt
Uma estrutura de aprendizado profundo de fluxo duplo para reconhecimento contínuo de linguagem de sinais para ampliar a acessibilidade à comunicação na região de Ha’il
Superando a lacuna de comunicação
Para muitas pessoas surdas, a linguagem de sinais é o principal meio de comunicação, porém a maioria dos computadores, telefones e serviços públicos ainda não a compreende. Este artigo apresenta um novo sistema de inteligência artificial capaz de observar a assinatura contínua em vídeo e convertê‑la em palavras escritas com maior precisão. Ao prestar atenção não apenas aos movimentos das mãos, mas também à posição da cabeça e aos sinais faciais, o sistema visa tornar a comunicação tecnológica mais natural e acessível—especialmente para as comunidades surdas na região de Ha’il, na Arábia Saudita, onde o suporte digital ainda é limitado. 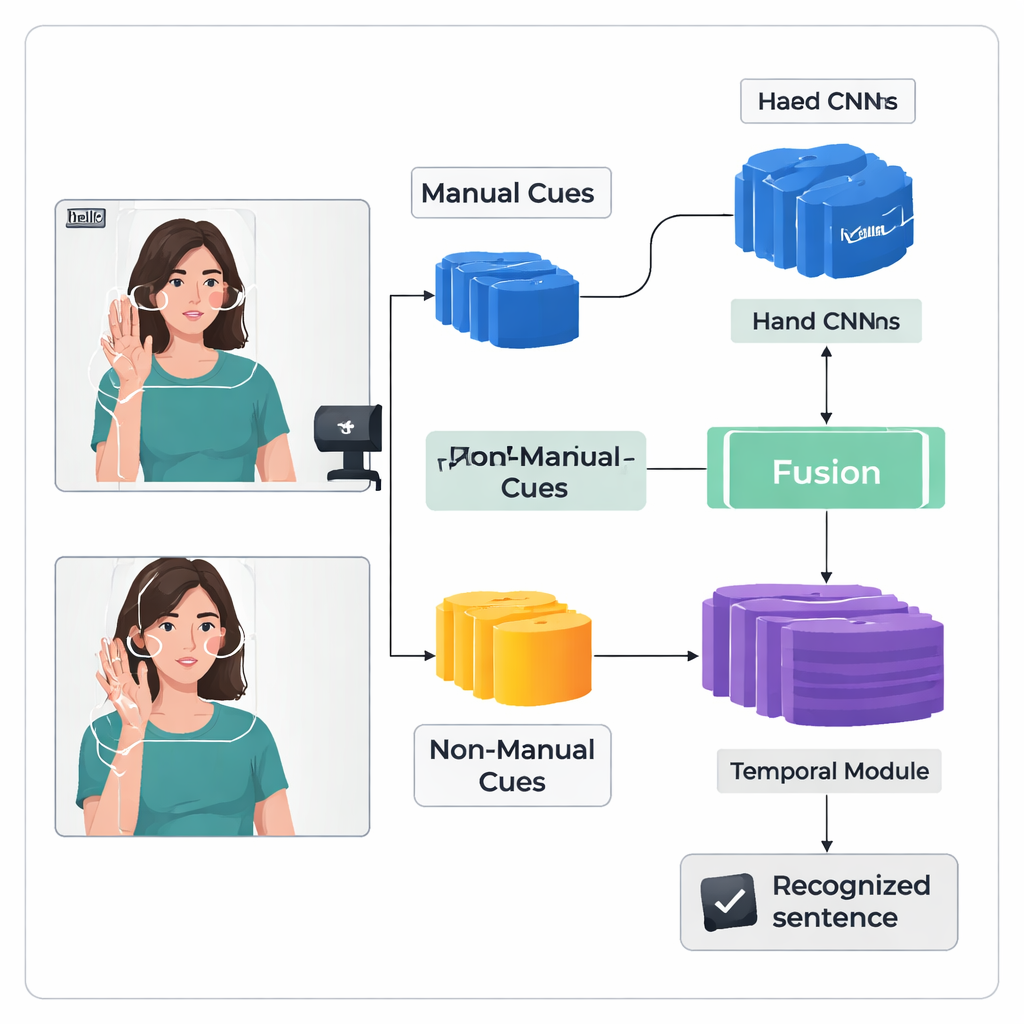
Por que as mãos não bastam
As linguagens de sinais são sistemas ricos e complexos que utilizam toda a parte superior do corpo. O significado não vem apenas de como as mãos se movem, mas também das expressões faciais, da direção do olhar e de como a cabeça inclina ou faz acenos. Esses sinais não manuais podem indicar perguntas, negações, ênfase ou emoção. Os humanos interpretam tudo isso de forma quase automática, mas a maioria dos sistemas computacionais para reconhecimento de linguagem de sinais concentra‑se quase exclusivamente nas mãos. Esse atalho facilita o treinamento, mas faz com que pistas importantes se percam, especialmente quando os sinais fluem juntos em frases contínuas rápidas, e não em palavras isoladas.
Dois fluxos trabalhando em paralelo
Os autores introduzem uma estrutura de aprendizado profundo de “fluxo duplo” chamada TS‑CNN que processa as mãos e a cabeça separadamente e depois as integra. Um fluxo foca em imagens recortadas das mãos do sinalizador, aprendendo padrões de forma, movimento e posição. O outro fluxo recebe um mapa compacto do rosto e da cabeça, derivado de pontos de referência e estimativas de pose da cabeça. Ambos os fluxos usam um tipo padrão de rede de visão para transformar cada quadro de vídeo em características numéricas. O sistema então funde essas características quadro a quadro, respeitando o fato de que as pistas manuais e de cabeça ocorrem ao mesmo tempo na assinatura real. Um módulo temporal posterior analisa muitos quadros para entender como os sinais se desenrolam ao longo do tempo, e uma camada recorrente produz uma sequência de unidades de sinal previstas, ou glossas.
Refinando a memória do sistema sobre os sinais
Reconhecer a assinatura contínua é difícil porque os dados de treinamento são limitados e os sinais se misturam sem rótulos claros quadro a quadro. Para enfrentar isso, os autores adicionam um Módulo de Aprimoramento de Características que fornece orientação extra à rede durante o treinamento. Uma técnica amplamente usada alinha a sequência de glossas previstas com o vídeo, produzindo posições prováveis para cada glossa no tempo. O novo módulo utiliza essas sugestões de alinhamento como supervisão direta para refinar a representação interna das características das glossas. Em termos simples, o sistema aprende não apenas a emitir a sequência correta, mas também a construir “memórias” internas mais claras e consistentes sobre como cada sinal aparece em vídeos diferentes.
Colocando a abordagem à prova
A equipe avalia o TS‑CNN em dois conjuntos de dados conhecidos de linguagem de sinais: RWTH‑PHOENIX‑Weather 2014 para a Língua de Sinais Alemã e CSL Split II para a Língua de Sinais Chinesa. Eles medem o desempenho usando a taxa de erro por palavra, uma métrica padrão semelhante à usada no reconhecimento de fala. Em comparação com uma linha‑base que observa apenas os movimentos das mãos, a adição de informação sobre a pose da cabeça reduz os erros em cerca de 4 pontos percentuais nos dados alemães e 3–4 pontos nos dados chineses. A inclusão do módulo de aprimoramento de características traz ganhos ainda maiores, reduzindo os erros em aproximadamente 10–14% no total em ambos os conjuntos. O sistema também opera de forma eficiente, alcançando velocidades em tempo real em uma placa gráfica moderna, o que é crucial se for usado em interpretação ao vivo ou em ferramentas móveis. 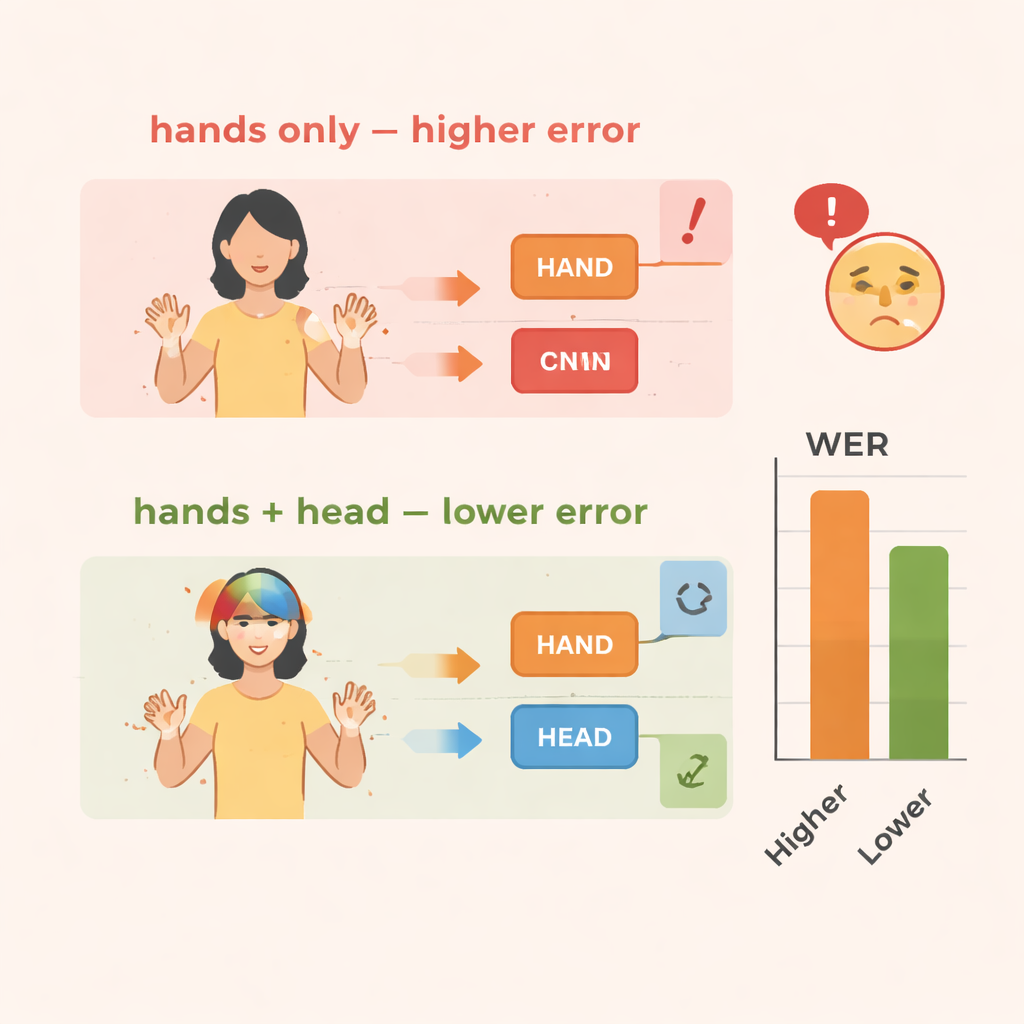
O que isso significa para a vida cotidiana
Em termos práticos, esta pesquisa mostra que os computadores podem compreender a linguagem de sinais de forma mais confiável quando observam o sinalizador inteiro, e não apenas as mãos. Ao modelar movimentos da cabeça e sinais faciais junto com os movimentos das mãos, e ao refinar cuidadosamente o aprendizado com dados de treinamento limitados, a estrutura TS‑CNN aproxima‑se de sistemas práticos que poderiam auxiliar pessoas surdas em salas de aula, hospitais e repartições públicas. Para regiões como Ha’il, onde intérpretes humanos são escassos e projetos tecnológicos ainda estão surgindo, tal sistema poderia, eventualmente, apoiar uma comunicação mais inclusiva—ajudando a reduzir a lacuna entre sinalizadores e ouvintes sem substituir a experiência rica e humana da própria linguagem de sinais.
Citação: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Palavras-chave: reconhecimento de linguagem de sinais, aprendizado profundo, acessibilidade, visão computacional, interação humano–computador