Clear Sky Science · pt
Um método de proteção de privacidade de dados para modelos de previsão de doenças infecciosas com equilíbrio entre velocidade de treinamento e precisão
Por que proteger dados de saúde ainda importa
Hospitais e agências de saúde agora dependem da inteligência artificial para prever surtos de gripe, COVID-19 e outras infecções dias ou semanas antes. Essas previsões podem orientar campanhas de vacinação, dimensionamento de pessoal e planejamento de emergência. Ainda assim, os mesmos prontuários detalhados que tornam as previsões precisas também são extremamente sensíveis. Leis e preocupações públicas frequentemente impedem que os dados sejam reunidos entre instituições, o que enfraquece o poder desses modelos. Este artigo apresenta uma forma de treinar sistemas de previsão de doenças infecciosas de alta qualidade mantendo os dados de cada hospital armazenados com segurança no próprio local.
Aprendendo com muitos hospitais sem compartilhar prontuários
Os autores se baseiam em uma técnica chamada aprendizado federado, na qual vários hospitais treinam um modelo de previsão compartilhado em conjunto. Em vez de copiar registros brutos de pacientes para um servidor central, cada local treina o modelo localmente e envia apenas atualizações numéricas das configurações internas do modelo. Um servidor central combina essas atualizações e envia o modelo aprimorado de volta. Esse ciclo se repete muitas vezes. Em teoria, o aprendizado federado protege a privacidade porque informações pessoais nunca saem da instituição. Na prática, porém, atacantes engenhosos podem às vezes inferir detalhes sobre os dados subjacentes a partir das atualizações compartilhadas, por isso é necessário proteção adicional. 
Trancando os números com criptografia inteligente
Para reforçar a segurança, a equipe usa criptografia homomórfica — uma forma de trava digital que permite realizar cálculos diretamente sobre números criptografados, sem jamais vê‑los em forma simples. Esquemas tradicionais desse tipo são muito seguros, mas notoriamente lentos e exigentes em dados, o que os torna difíceis de usar com modelos grandes e complexos, como aqueles baseados em redes Long Short-Term Memory (LSTM). Os pesquisadores projetam um esquema híbrido que trata diferentes partes do modelo de forma distinta. Os componentes mais reveladores são protegidos com uma forma forte, porém pesada, de criptografia, enquanto partes menos sensíveis usam um bloqueio mais leve e rápido. Além disso, um cronograma aleatório pré‑planejado decide em quais rodadas de treinamento os sites realmente enviam atualizações criptografadas, permitindo que pulem comunicações redundantes. Testes mostram que essa combinação acelera o treinamento em cerca de 25% em comparação com o uso da criptografia pesada em todos os lugares, mantendo os dados protegidos sob fortes suposições criptográficas.
Enviando apenas as atualizações que realmente importam
Mesmo com travamento mais inteligente, enviar cada pequena mudança do modelo entre as instituições consome tempo e largura de banda de rede. Os autores propõem, portanto, uma nova regra de treinamento chamada Seleção de Dados–Gradiente Estocástico Distribuído de Seleção (DS‑DSSGD). Durante o treinamento, o algoritmo mede quanto cada parte do modelo muda de um passo para o outro. Apenas as atualizações que ultrapassam um limite predefinido são transmitidas; mudanças pequenas e de baixo impacto são simplesmente ignoradas. Ao mesmo tempo, o algoritmo rastreia quais pontos de dados são responsáveis pelas maiores mudanças mais informativas. Esses registros influentes são coletados em um conjunto de dados refinado usado para uma rodada final de treinamento. Experimentos com três anos de relatórios reais de infecção da cidade de Yichang, combinados com tendências de buscas locais na web, mostram que o DS‑DSSGD reduz o tempo de treinamento em aproximadamente 10% em comparação com vários métodos padrão, sem perda significativa na precisão preditiva.
Uma plataforma prática para colaboração segura
Avanços técnicos importam apenas se hospitais e laboratórios puderem realmente usá‑los. Para fechar essa lacuna, a equipe integra seus métodos em um ambiente computacional real chamado Plataforma de Computação de Segurança e Privacidade Yi Shu Fang XDP. O XDP gerencia toda a jornada dos dados de saúde, desde a coleta e limpeza até a análise criptografada e o compartilhamento de resultados. Ele oferece suporte às ferramentas familiares usadas por estatísticos, bioinformatas e clínicos, e permite que pesquisadores de diferentes instituições colaborem dentro de um espaço de trabalho controlado sem jamais baixar dados brutos. Dentro dessa plataforma, o esquema de criptografia híbrida e o algoritmo DS‑DSSGD funcionam como componentes plugáveis, transformando o arcabouço teórico em um sistema operacional. 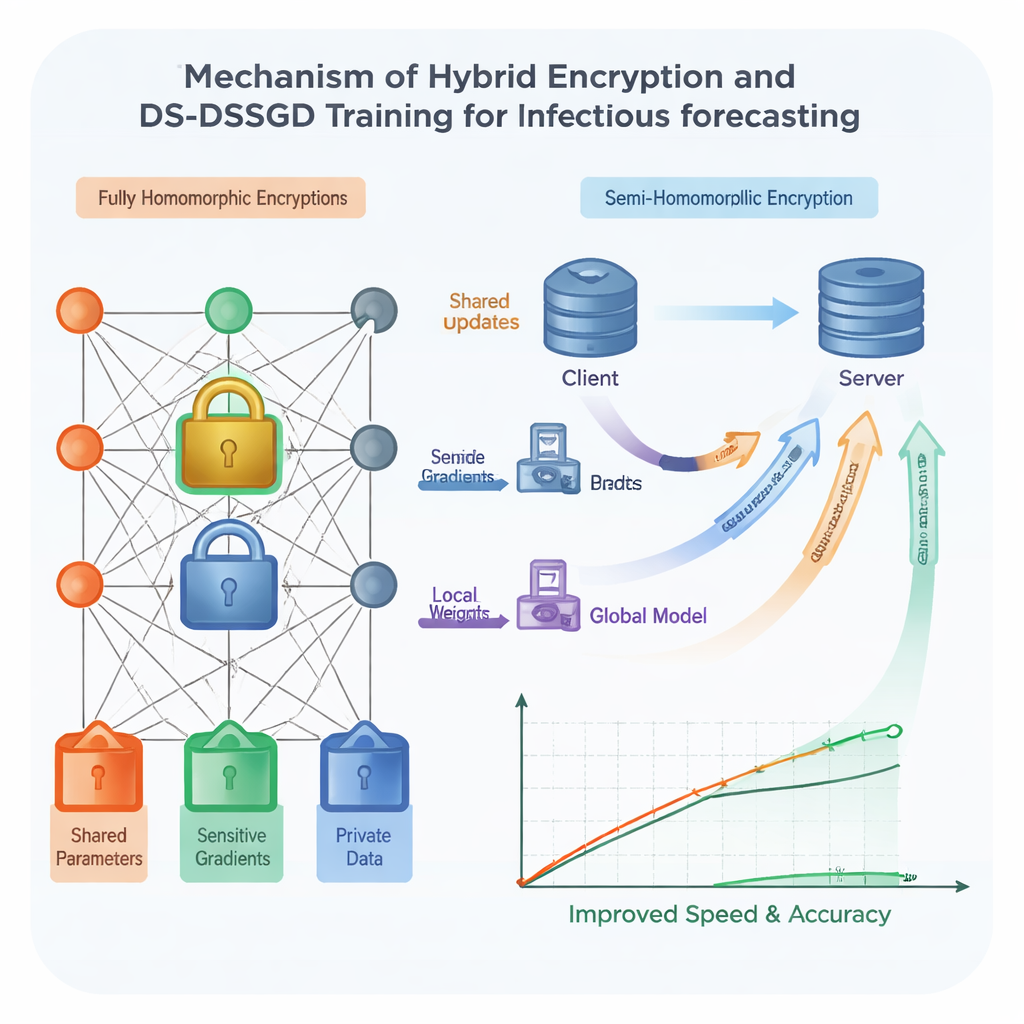
O que isso significa para previsões de surtos no futuro
Em termos práticos, este estudo mostra que é possível “ter os dois” na previsão de doenças infecciosas: proteger a privacidade dos pacientes e, ao mesmo tempo, treinar modelos rápidos e precisos com dados provenientes de muitas instituições. Ao criptografar diferentes partes do modelo com o nível certo de força, enviar atualizações apenas quando necessário e envolver tudo dentro de uma plataforma de colaboração segura, os autores reduzem o custo da privacidade de um ônus paralisante para uma sobrecarga administrável. Se adotadas em larga escala, abordagens desse tipo poderiam permitir que hospitais e agências de saúde pública combinassem seu conhecimento contra a próxima epidemia sem nunca expor registros médicos individuais.
Citação: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
Palavras-chave: previsão de doenças infecciosas, privacidade de dados de saúde, aprendizado federado, criptografia homomórfica, aprendizado profundo