Clear Sky Science · pt
Estimando a comumidade e a prevalência de espécies por métodos não supervisionados
Por que contar espécies comuns e raras importa
Quando imaginamos a natureza em risco, muitas vezes pensamos em animais raros à beira da extinção. No entanto, a maior parte do tecido vivo ao nosso redor é formada por criaturas muito comuns ou que estão desaparecendo silenciosamente antes que alguém perceba. Saber quão difundida uma espécie realmente é em um determinado local é essencial para prever como os ecossistemas responderão à poluição, ao uso do solo ou às mudanças climáticas. Este artigo apresenta uma maneira de estimar, ao mesmo tempo, quão comum ou rara é uma grande quantidade de espécies, usando apenas registros de avistamentos já existentes e técnicas modernas de análise de dados. O objetivo é fornecer entradas mais objetivas para modelos computacionais que preveem onde as espécies podem viver agora e no futuro.
De registros simples a grandes questões ecológicas
Ecólogos costumam usar modelos computacionais, chamados modelos de nicho ecológico, para determinar quais ambientes são adequados para uma espécie. Esses modelos ajudam a prever onde uma espécie pode aparecer diante de mudanças climáticas ou em novas regiões. Um ingrediente crucial é a “prevalência” – grosso modo, a proporção de locais amostrados onde a espécie está presente. Ela registra se uma espécie deve ser comum ou rara antes de qualquer nova investigação. Essa expectativa a priori molda fortemente como os modelos convertem pontuações de adequação bruta em probabilidades de presença e como traçam limites entre “presente” e “ausente” no mapa. Se a prevalência for estimada de forma inadequada, especialmente para espécies raras, as previsões podem ser enganosas e os planos de conservação podem focar nos lugares errados.
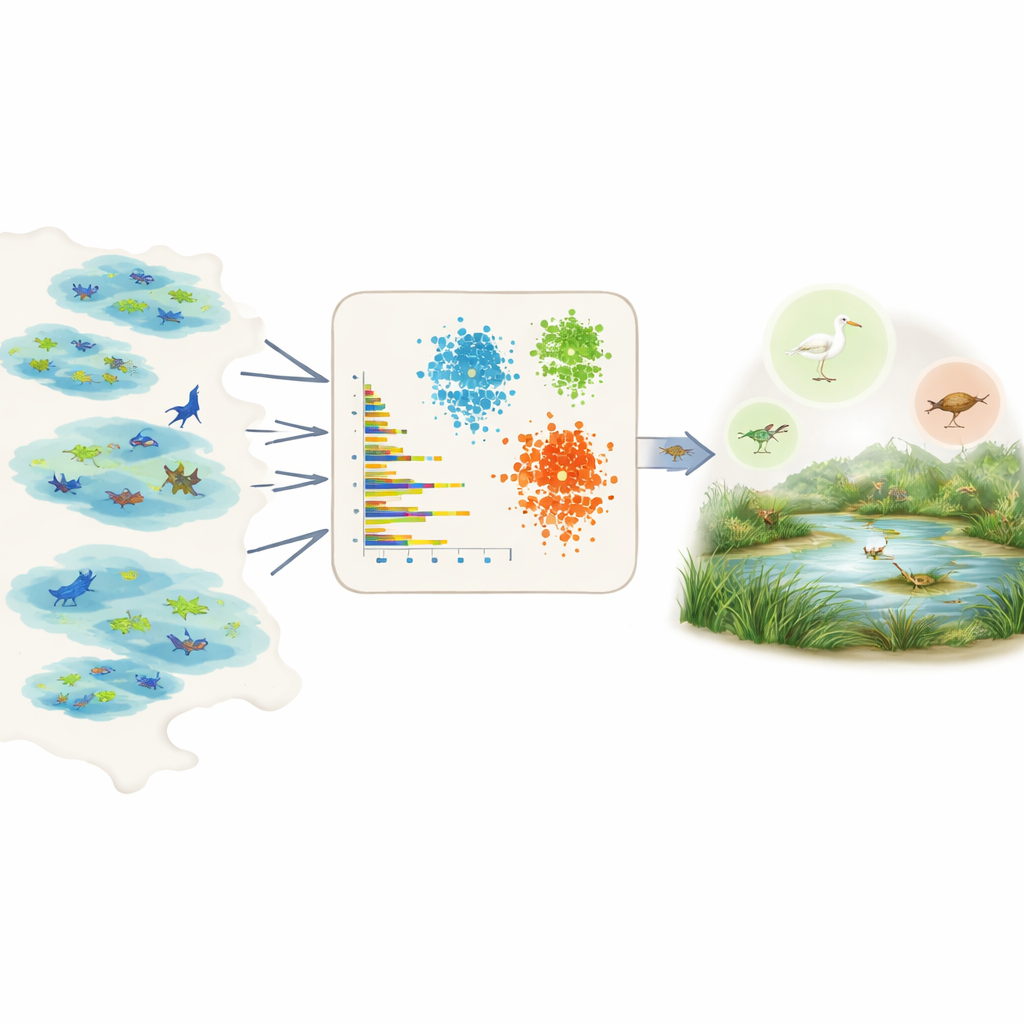
Deixar os dados falarem por centenas de espécies
Medir diretamente a prevalência é difícil porque os dados de campo são irregulares e viesados. Algumas áreas são muito amostradas, algumas espécies são mais fáceis de observar e muitos registros vêm de projetos de ciência cidadã com esforço desigual. Em vez de depender da opinião de especialistas ou de conhecimento detalhado para cada espécie, os autores exploram o Global Biodiversity Information Facility, um enorme banco de dados aberto de observações de espécies. Para cada espécie em uma região escolhida, eles resumem os registros brutos em alguns números simples e comparáveis: quantos indivíduos são normalmente relatados por avistamento, em quantos conjuntos de dados ou zonas úmidas a espécie aparece, quão difundida ela é dentro dessas zonas úmidas e com que frequência é observada ao longo do tempo, incluindo a ocorrência de picos de muitas observações.
Ensinar máquinas a separar espécies comuns e raras
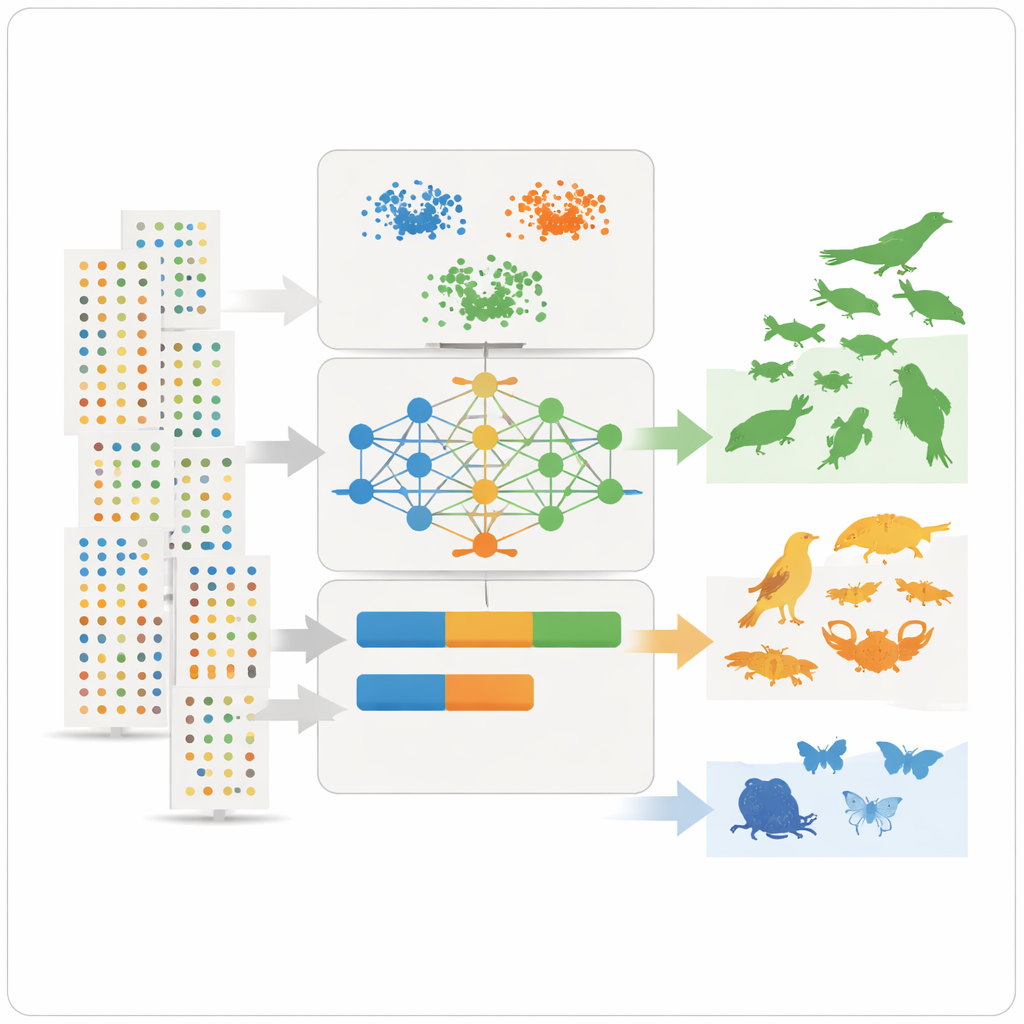
Com essas características resumidas em mãos, a equipe aplica três ferramentas de aprendizado não supervisionado – dois métodos de agrupamento e um modelo de aprendizado profundo conhecido como autoencoder variacional – que procuram padrões sem que lhes seja dito de antemão quais espécies são comuns ou raras. Os métodos de agrupamento juntam espécies que compartilham similaridades em abundância, dispersão e frequência de observação. O autoencoder aprende como é um registro de espécie “típico” e sinaliza padrões incomuns como anomalias, que frequentemente correspondem a espécies raras ou mal observadas. Os modelos então atribuem a cada espécie três classes intuitivas – muito comum, relativamente comum ou rara – e convertem essas classes em valores numéricos de prevalência que podem ser inseridos diretamente em modelos de nicho ecológico como probabilidades a priori.
Testando a abordagem em uma zona úmida vulnerável
Para verificar quão bem esse arcabouço funciona na prática, os autores concentram-se na bacia do Lago Massaciuccoli, na Toscana, Itália, um trecho de planície úmida rico em aves, peixes, insetos e outros animais. Essa paisagem é tanto um refúgio de biodiversidade quanto um atrativo turístico, mas também é vulnerável às mudanças climáticas, à escassez de água e à poluição. Para 161 espécies animais associadas ao lago, os modelos foram treinados usando registros de outras zonas úmidas italianas e então solicitados a inferir quão comum cada espécie deveria ser em Massaciuccoli. Dois especialistas locais, com ampla experiência de campo na área, avaliaram as mesmas espécies de forma independente. Comparando as duas abordagens, o modelo de aprendizado profundo concordou com a avaliação combinada dos especialistas em cerca de 81–90% das espécies, enquanto os métodos de agrupamento e um conjunto (ensemble) dos três também apresentaram bom desempenho.
Aprendendo com desacordos e vieses ocultos
Nem todos os casos bateram perfeitamente. Algumas espécies bem conhecidas pelos especialistas como abundantes ao redor do lago apareceram como raras nos dados, muitas vezes porque são elusivas, subnotificadas ou observadas com mais intensidade em algumas zonas úmidas do que em outras. Isso destacou uma limitação-chave: grandes bases de dados refletem onde e como as pessoas procuram a natureza, não apenas onde as espécies realmente ocorrem. Uma análise de sensibilidade mostrou quais características foram mais importantes para as classificações, com a média de registros por conjunto de dados, a abundância por avistamento e a consistência das observações ao longo dos anos emergindo como especialmente informativas. Apesar dos vieses remanescentes, o método produziu estimativas de prevalência claras e reprodutíveis e pode ser ajustado para usar classes mais finas ou mais amplas, conforme as necessidades de modelagem.
O que isso significa para previsões futuras da natureza
Para não especialistas, a mensagem principal é que agora podemos usar dados de biodiversidade existentes de forma mais inteligente para avaliar quais espécies provavelmente serão comuns, medianas ou raras em um determinado contexto, sem afinar manualmente cada caso. Ao transformar registros de observação ruidosos em estimativas de prevalência transparentes e orientadas por dados, o quadro ajuda modelos ecológicos a fazer previsões mais realistas sobre adequação de habitat e tendências futuras da biodiversidade. Isso, por sua vez, pode apoiar um planejamento melhor para zonas úmidas como Massaciuccoli e muitos outros ecossistemas no mundo, mesmo quando os dados de campo são incompletos e o tempo de especialistas é limitado.
Citação: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Palavras-chave: prevalência de espécies, modelagem da biodiversidade, ecossistemas de zonas úmidas, aprendizado de máquina em ecologia, comumidade de espécies