Clear Sky Science · pt
Classificação de texto de letras com redes profundas híbridas adaptativas em cascata serial usando abordagem de otimização
Por que filtros musicais mais inteligentes importam
A música entra em nossas vidas quase sem interrupção, e grande parte do que ouvimos é selecionado por algoritmos. No entanto, muitos desses sistemas ainda têm dificuldade com uma questão simples: o que exatamente as palavras de uma canção dizem, e para quem elas são apropriadas? Este artigo enfrenta esse problema construindo um modelo avançado de inteligência artificial (IA) que lê automaticamente letras de músicas e as classifica por humor, gênero, sentimento e até tipo de intérprete. O objetivo é ajudar a criar playlists mais seguras para crianças, recomendações por humor mais precisas e melhores ferramentas para pesquisadores da música.
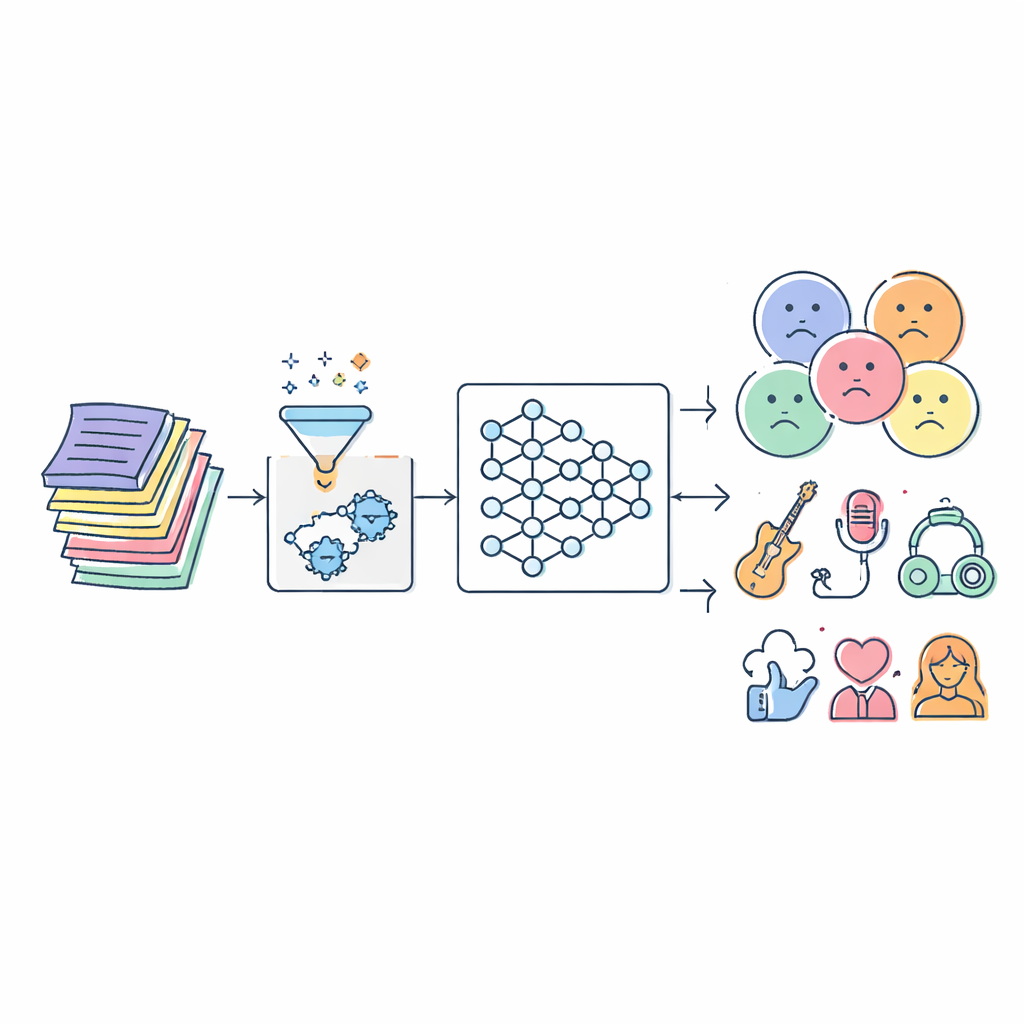
O desafio escondido nas palavras das canções
As letras são bem mais complexas do que uma lista de palavras boas ou ruins. A mesma frase pode soar terna em uma música e ameaçadora em outra, e os ouvintes trazem suas próprias experiências ao interpretar o que escutam. Filtros tradicionais geralmente dependem de listas estáticas de termos ofensivos ou de técnicas estatísticas simples. Essas abordagens perdem o contexto, não acompanham a gíria em evolução e muitas vezes rotulam músicas de forma equivocada. Ao mesmo tempo, a explosão da música digital significa que há milhões de faixas a analisar, em vários idiomas e estilos, o que sobrecarrega a rotulagem manual e algoritmos mais antigos.
Limpeza das letras brutas
Os autores começam reunindo grandes coleções de letras a partir de três conjuntos de dados públicos que, juntos, cobrem centenas de milhares de músicas em múltiplos gêneros e idiomas. Antes que qualquer IA possa aprender com o texto, as letras precisam ser limpas. O sistema remove pontuação, símbolos especiais e fragmentos repetidos ou irrelevantes, e então reduz formas relacionadas de palavras a uma raiz comum (por exemplo, “cantando”, “canta” e “cantou” tornam-se “cantar”). Essa etapa de pré-processamento elimina ruído mantendo o significado, para que as fases posteriores possam focar no tom emocional e no tema em vez de peculiaridades de formatação ou variações ortográficas.
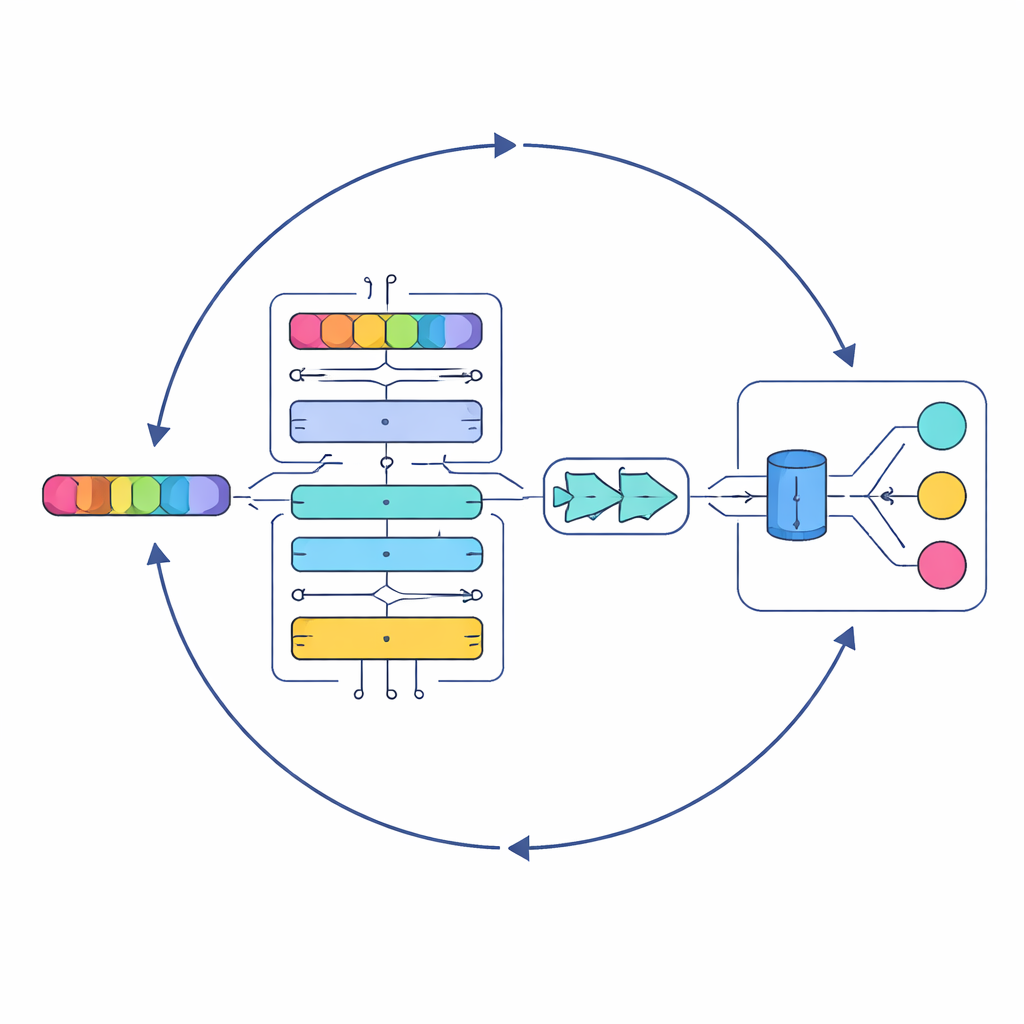
Uma IA em camadas que lê como um ouvinte atento
No cerne do estudo está um novo modelo chamado Serial Cascaded Hybrid Adaptive Deep Network, ou SCHADNet. Ele combina três ideias poderosas da IA de linguagem moderna. Primeiro, um codificador baseado em transformer captura como palavras se relacionam ao longo de toda a letra, não apenas com vizinhos imediatos. Segundo, uma camada bidirecional de Long Short-Term Memory lê a letra tanto para frente quanto para trás no tempo, ajudando o sistema a entender como versos anteriores coloram o significado dos posteriores. Terceiro, uma camada Gated Recurrent Unit refina essas informações em um resumo compacto adequado para decisões finais. Juntos, esses componentes atuam como um coro de leitores especializados, cada um focando em diferentes aspectos do texto da música.
Tomando emprestada uma estratégia do mar
Simplesmente empilhar camadas de aprendizado profundo não é suficiente; suas configurações internas — como quantos neurônios contêm e por quanto tempo treinam — afetam fortemente o desempenho. Em vez de ajustar manualmente essas escolhas, os autores recorrem a uma abordagem de otimização inspirada pelos padrões de caça de predadores marinhos. Seu Algoritmo de Predadores Marinhos Aprimorado (IMPA) explora muitas combinações possíveis de parâmetros, aproximando-se progressivamente daquelas que trazem os melhores resultados. Ao eliminar partes do algoritmo original que não ajudavam neste contexto, eles melhoram a convergência, ou seja, o sistema alcança boas soluções mais rápido e com mais confiabilidade.
Quão bem o sistema performa
Os pesquisadores testam o SCHADNet com IMPA em três conjuntos de letras diferentes e o comparam com uma série de métodos estabelecidos, incluindo classificadores clássicos de aprendizado de máquina e vários modelos populares de aprendizado profundo, como LSTM simples, sistemas apenas com transformer e redes híbridas. Em métricas como acurácia, recall (quantas músicas realmente relevantes são encontradas) e outras medidas de qualidade, a nova abordagem consistentemente se destaca. Em um grande conjunto de dados multilíngue, ela classifica corretamente cerca de 93% das músicas e alcança um valor preditivo negativo especialmente alto, o que significa que é muito boa em reconhecer letras que não pertencem a uma categoria marcada — crucial para evitar bloqueios ou rotulações excessivas.
O que isso significa para ouvintes e criadores
Para o público em geral, a mensagem é direta: os autores construíram um leitor de letras mais nuançado e confiável. Em vez de depender de listas grosseiras de palavras, seu sistema analisa frases inteiras, contexto e padrões em grandes coleções de música, e então atribui automaticamente rótulos como humor, estilo ou adequação para público mais jovem. Embora o modelo seja complexo e demandante em termos computacionais, ele abre caminho para controles parentais mais inteligentes, playlists por humor mais ricas e novas formas de estudar tendências na música popular. Trabalhos futuros visam reduzir sua dependência de dados e acelerar o treinamento, mas mesmo em sua forma atual, o SCHADNet aponta para um futuro em que plataformas musicais compreendem letras quase tão atentamente quanto um ouvinte humano atento.
Citação: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
Palavras-chave: recomendação musical, análise de letras, classificação de texto, aprendizado profundo, moderação de conteúdo