Clear Sky Science · pt
Previsão precisa e interpretável da demanda química de oxigênio usando algoritmos de reforço explicáveis com análise SHAP
Por que observar o oxigênio de um rio importa
Rios são a veia vital de cidades e fazendas, mas quando se enchem de resíduos orgânicos de fábricas, esgotos ou campos, a água pode ficar privada de oxigênio e insegura para pessoas e ecossistemas. Um exame comum da saúde de um rio é a “demanda química de oxigênio” (DQO), uma medida de quanto oxigênio é necessário para decompor a poluição. Medir a DQO em laboratório é lento e caro, portanto este estudo investiga se ferramentas avançadas, porém explicáveis, de aprendizado de máquina podem prever de forma confiável a DQO a partir de dados rotineiros de sensores — e mostrar claramente o que está impulsionando a poluição. 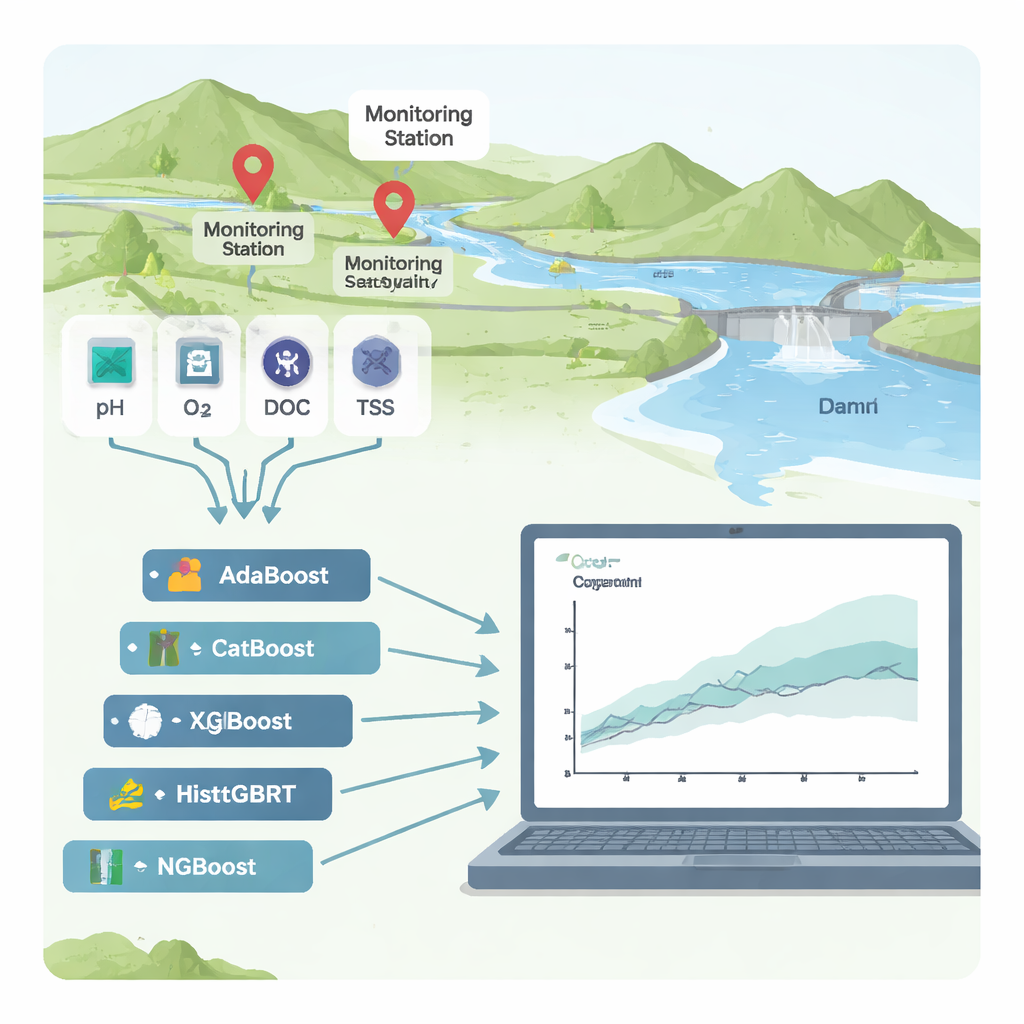
Modelos inteligentes para um mundo poluído
Os pesquisadores focalizaram duas estações de monitoramento de rios na Coreia do Sul, Hwangji e Toilchun, logo a montante da barragem multipropósito de Yeongju. Nessas estações existem décadas de registros de indicadores comuns de qualidade da água: acidez (pH), oxigênio dissolvido, sólidos suspensos (partículas finas na água), nutrientes como nitrogênio e fósforo, carbono orgânico total (COT), demanda bioquímica de oxigênio (DBO₅), temperatura da água, condutividade elétrica e vazão do rio. Em vez de construir um modelo tradicional baseado em física — que pode ser difícil de transferir de um rio para outro — eles testaram seis algoritmos de “boosting”, uma poderosa família de métodos de aprendizado de máquina que combinam muitas árvores de decisão simples em um preditor robusto.
Encontrando o melhor “previsores” do rio
Para comparar os seis métodos de boosting (AdaBoost, CatBoost, XGBoost, LightGBM, HistGBRT e NGBoost), a equipe treinou os modelos em cerca de 70% dos dados históricos e avaliou o desempenho nos 30% restantes. Avaliaram a acurácia usando várias estatísticas que capturam quão próximas as previsões estão das medições reais de DQO e quão bem os modelos generalizam para condições não vistas. Na estação Toilchun, o modelo NGBoost — que prevê não apenas um valor único, mas uma distribuição probabilística completa para a DQO — foi o claro vencedor, capturando quase toda a variação da DQO com erros muito baixos. Em Hwangji, que é um sítio mais complexo, o CatBoost ofereceu o melhor equilíbrio entre precisão e estabilidade. Alguns modelos, especialmente o XGBoost, pareceram quase perfeitos nos dados de treinamento mas tiveram desempenho ruim nos dados de teste, um sinal clássico de “overfitting”, onde um modelo memoriza ruído em vez de aprender padrões reais.
Abrindo a caixa-preta da IA
Um objetivo central do estudo foi não apenas prever a DQO, mas também explicar por que os modelos fizeram suas previsões. Para isso, os autores usaram SHAP (Shapley Additive Explanations), uma técnica que atribui a cada variável de entrada uma contribuição — positiva ou negativa — para cada previsão individual. Em ambos os rios e na maioria dos algoritmos, três variáveis emergiram consistentemente como os principais determinantes da DQO: carbono orgânico total (COT), demanda bioquímica de oxigênio (DBO₅) e sólidos suspensos (SS). Em termos simples, quanto mais material orgânico e partículas finas na água, maior a demanda por oxigênio. Os modelos também revelaram diferenças específicas de cada local: em Toilchun, a vazão (discharge) e o fósforo total tiveram papel mais forte, sugerindo maior influência de fontes difusas como escoamento agrícola; em Hwangji, padrões na condutividade e nos sólidos suspensos indicaram fontes mais localizadas ou industriais. 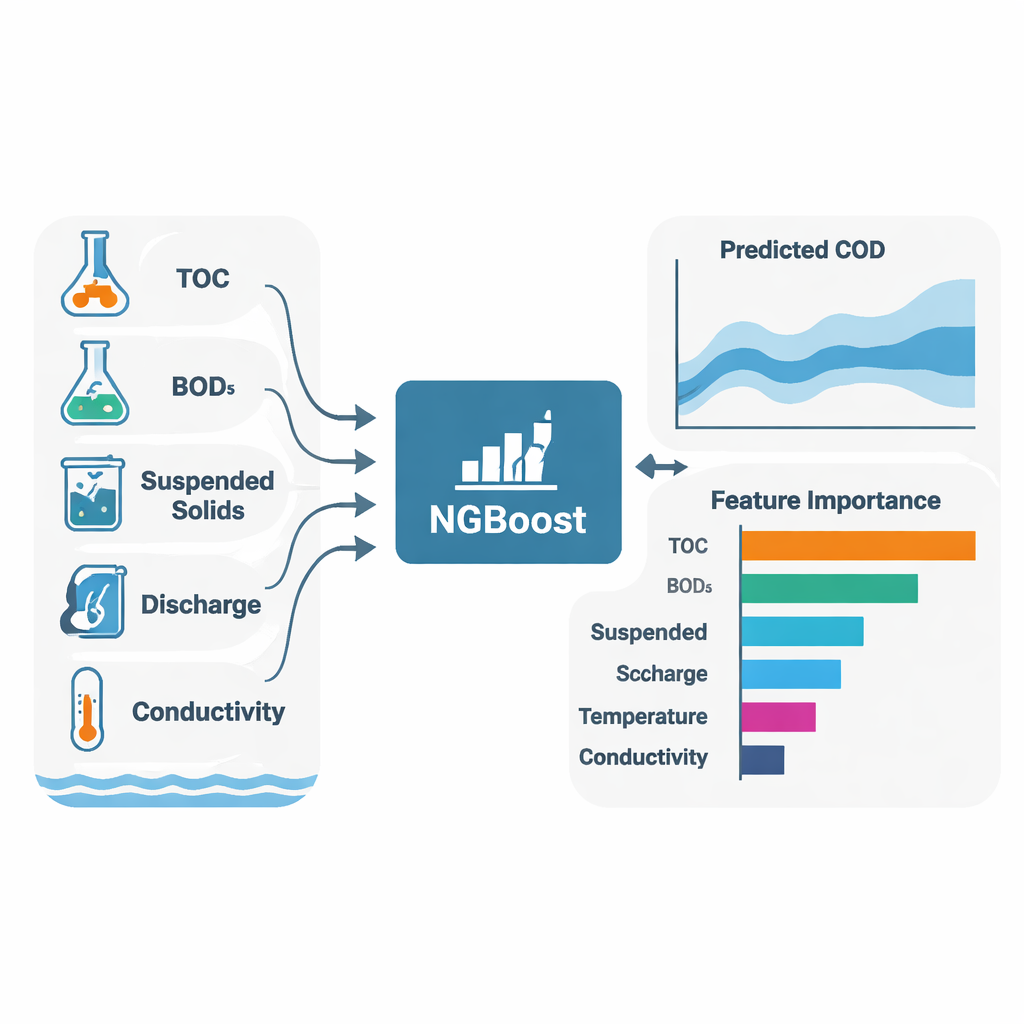
O que os resultados significam para rios reais
Esses insights mostram que modelos de boosting, quando emparelhados com SHAP, podem ir além de serem caixas-pretas opacas. Eles fornecem tanto previsões precisas da demanda de oxigênio quanto uma explicação fisicamente coerente sobre o que está impulsionando a poluição em cada local. Isso é importante para gestores de barragens e bacias hidrográficas que precisam priorizar o que monitorar e onde intervir: se COT e DBO₅ são as alavancas mais fortes, controlar entradas de resíduos orgânicos pode gerar a maior melhoria na qualidade da água. As previsões probabilísticas do NGBoost também trazem uma noção de incerteza, crucial para sistemas de alerta precoce e decisões baseadas em risco. Em suma, o estudo demonstra que uma IA explicável e bem projetada pode ajudar a proteger reservatórios de água potável e a vida aquática ao transformar leituras rotineiras de sensores em previsões confiáveis e transparentes da saúde dos rios.
Citação: Merabet, K., Kim, S., Heddam, S. et al. Accurate and interpretable prediction of chemical oxygen demand using explainable boosting algorithms with SHAP analysis. Sci Rep 16, 6359 (2026). https://doi.org/10.1038/s41598-026-38757-4
Palavras-chave: qualidade da água, demanda química de oxigênio, aprendizado de máquina, poluição de rios, IA explicável