Clear Sky Science · pt
Avaliação do desempenho de grandes modelos de linguagem em provas de reumatologia em persa: exatidão e raciocínio clínico do GPT-4o vs. GPT-5.1
Por que isso importa para médicos e pacientes
A inteligência artificial está entrando rapidamente em salas de aula e clínicas médicas, mas a maioria dos testes dessas ferramentas foca no inglês. Este estudo faz uma pergunta que interessa a milhões de falantes de persa: quão bem chatbots avançados de IA, especificamente GPT‑4o e GPT‑5.1, lidam com questões complexas de reumatologia escritas em persa? A resposta ajuda educadores, residentes e pacientes a entender onde essas ferramentas podem auxiliar o aprendizado com segurança e onde a expertise humana continua sendo essencial.
Colocando a IA à prova
Os pesquisadores reuniram 204 questões de múltipla escolha dos exames oficiais do Conselho Iraniano de Reumatologia de 2023 e 2024, os mesmos exames que os especialistas precisam passar para obter certificação. Após remover sete questões com falhas, foram usadas 197 questões válidas. Cada pergunta, incluindo quaisquer imagens ou gráficos acompanhantes, foi inserida em persa no GPT‑4o e no GPT‑5.1 em chats separados e novos. Os modelos foram solicitados a escolher a melhor resposta e explicar seu raciocínio, espelhando como um residente poderia consultar uma ferramenta de IA enquanto estuda.
Avaliar respostas e raciocínio
O desempenho foi avaliado de duas formas. Primeiro, as opções escolhidas pelos modelos foram comparadas com o gabarito oficial, produzindo uma medida simples de acerto ou erro. Segundo, seis reumatologistas certificados avaliaram independentemente a qualidade de cada explicação em uma escala de cinco pontos, desde raciocínio claramente errado até raciocínio completo e clinicamente sólido. As respostas de cada modelo foram pontuadas por dois reumatologistas diferentes, que desconheciam as avaliações um do outro e o gabarito oficial. Isso permitiu aos pesquisadores verificar não apenas se a IA “acertou por acaso”, mas se sua lógica se assemelhava à maneira de pensar dos especialistas.
Como o modelo mais novo se saiu
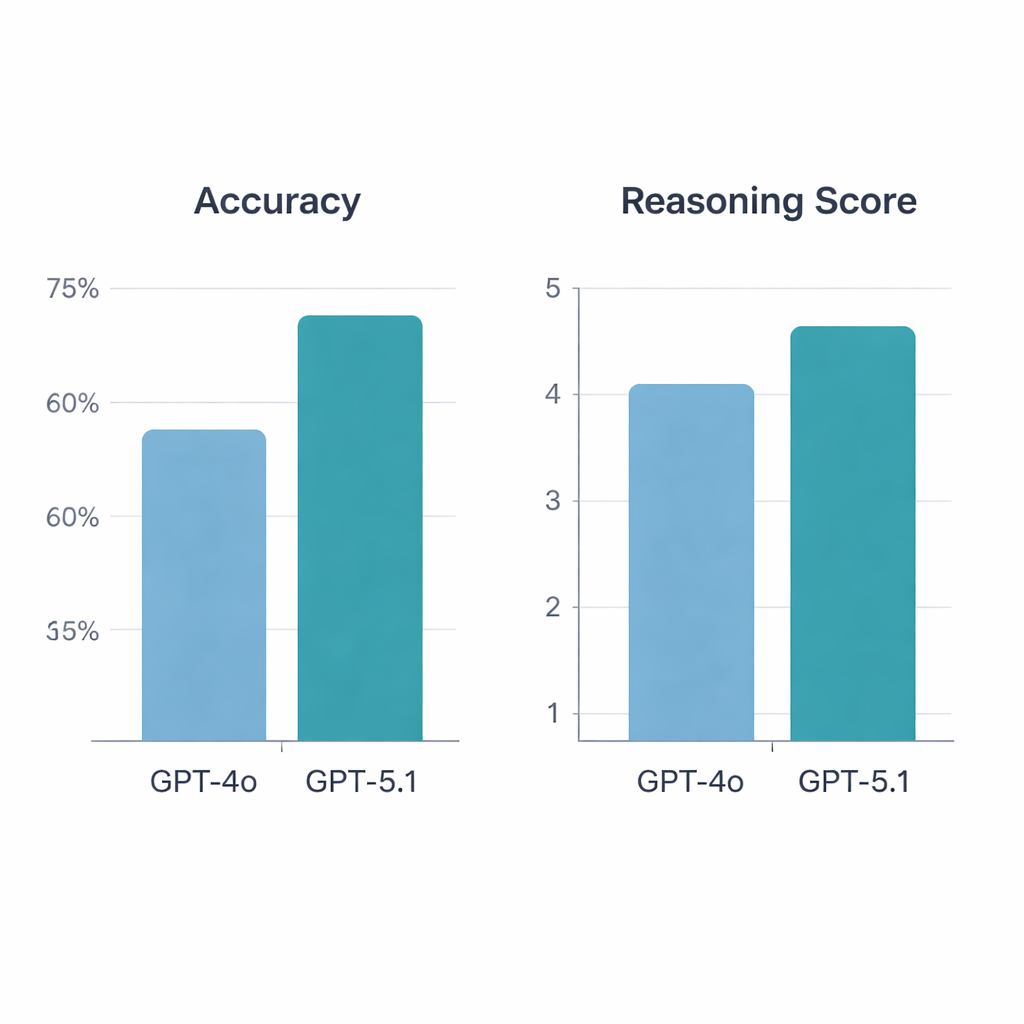
O GPT‑5.1 superou claramente o GPT‑4o. Nas 197 questões válidas, o GPT‑4o acertou 64,5%, enquanto o GPT‑5.1 alcançou 76% de acurácia — um salto estatisticamente significativo. Ambos os modelos acertaram 113 questões e erraram 34, mas o GPT‑5.1 respondeu corretamente 36 questões adicionais que o GPT‑4o não acertou; o GPT‑4o esteve correto exclusivamente em apenas 13 questões. Quando os reumatologistas avaliaram as explicações, o GPT‑5.1 também ficou à frente, com uma pontuação média de raciocínio de 4,47 em 5, comparado a 4,13 do GPT‑4o, e recebeu mais avaliações de pontuação máxima. Ao contrário do GPT‑4o, cuja qualidade de raciocínio variou conforme a questão focava em ciências básicas, vinhetas clínicas, diagnóstico ou tratamento, o GPT‑5.1 manteve desempenho mais uniforme entre todas as categorias.
Forças, lacunas e discordâncias humanas
O estudo revelou nuances importantes. Mesmo quando a resposta final de um modelo estava errada, especialistas por vezes julgaram seu raciocínio como relativamente coerente, evidenciando uma lacuna entre a pontuação de exame e o pensamento clínico do mundo real. Ao mesmo tempo, a concordância entre os avaliadores reumatologistas foi apenas moderada, ressaltando que os próprios clínicos divergem sobre o que conta como “bom raciocínio”. A língua também pareceu importar: trabalhos anteriores em inglês e espanhol relataram pontuações mais altas para modelos semelhantes, sugerindo que a IA ainda lida melhor com grandes idiomas globais do que com o persa. Os autores enfatizam que esses chatbots podem gerar explicações convincentes que ocultam erros factuais, e que seu desempenho pode mudar conforme os sistemas são atualizados.
O que isso significa daqui para frente
Para leitores leigos, a mensagem é que a geração mais recente de chatbots de IA está melhorando na resolução de exames médicos especializados em persa, mas não está pronta para substituir treinamento rigoroso ou julgamento de especialistas. O GPT‑5.1 pode ser um parceiro de estudo útil para residentes em reumatologia — resumindo tópicos, analisando casos e oferecendo explicações estruturadas —, mas não deve ser considerado a palavra final em decisões de alto impacto sobre diagnóstico ou tratamento. Os autores pedem estudos maiores e multilíngues, testes repetidos ao longo do tempo e simulações clínicas realistas para determinar como essas ferramentas podem ser integradas com segurança à educação médica e, eventualmente, ao cuidado diário dos pacientes.
Citação: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Palavras-chave: reumatologia, educação médica persa, grandes modelos de linguagem, raciocínio clínico, exames de certificação