Clear Sky Science · pt
Rede de fusão de características em múltiplos níveis guiada por entropia para recuperação de imagens baseada em conteúdo com alta precisão
Encontrando a Imagem Certa, Rápido
Todo dia, geramos e armazenamos um número impressionante de fotos — de exames médicos e imagens de satélite a filmagens de segurança e fotos pessoais. Marcar e buscar essas imagens manualmente é lento e pouco confiável. Este artigo apresenta uma forma mais inteligente de os computadores “olharem” diretamente para as imagens e encontrarem as que queremos com alta precisão, mesmo em coleções muito grandes e heterogêneas.
Por Que Olhar Apenas os Pixels Não Basta
A busca tradicional por imagens costuma se apoiar em nomes de arquivos ou tags simples como “gato” ou “edifício”. Mas as pessoas nem sempre rotulam imagens com cuidado, e os computadores veem apenas pixels brutos, não o significado rico que os humanos inferem. Sistemas anteriores baseados em conteúdo tentaram reduzir essa lacuna usando pistas visuais simples como cor, textura e forma. Essas pistas ajudaram, mas geralmente eram combinadas com níveis fixos de importância. Isso significa que o sistema tratava algumas características como sempre mais importantes do que outras, mesmo quando uma busca específica se beneficiaria de uma mistura diferente. Como resultado, a acurácia caía quando tipos de imagem, iluminação ou cenas mudavam.
Misturando Várias Maneiras de Ver
Os autores propõem um novo quadro de recuperação que funde dois tipos principais de evidência visual. Primeiro, usa modelos de aprendizado profundo — redes conhecidas como ResNet50 e VGG16 — que aprenderam a reconhecer padrões complexos nas imagens. Em segundo lugar, adiciona descritores “manuais” clássicos que capturam distribuições de cor, bordas e texturas de forma mais controlada. Em vez de presumir antecipadamente quanto cada tipo de característica deve pesar, o sistema deixa que os dados decidam. Ele mede quão informativa é cada característica para uma determinada busca e ajusta sua influência dinamicamente. Essa fusão multinível de pistas de alto e baixo nível ajuda o computador a formar uma compreensão mais rica e flexível do que há em uma imagem.
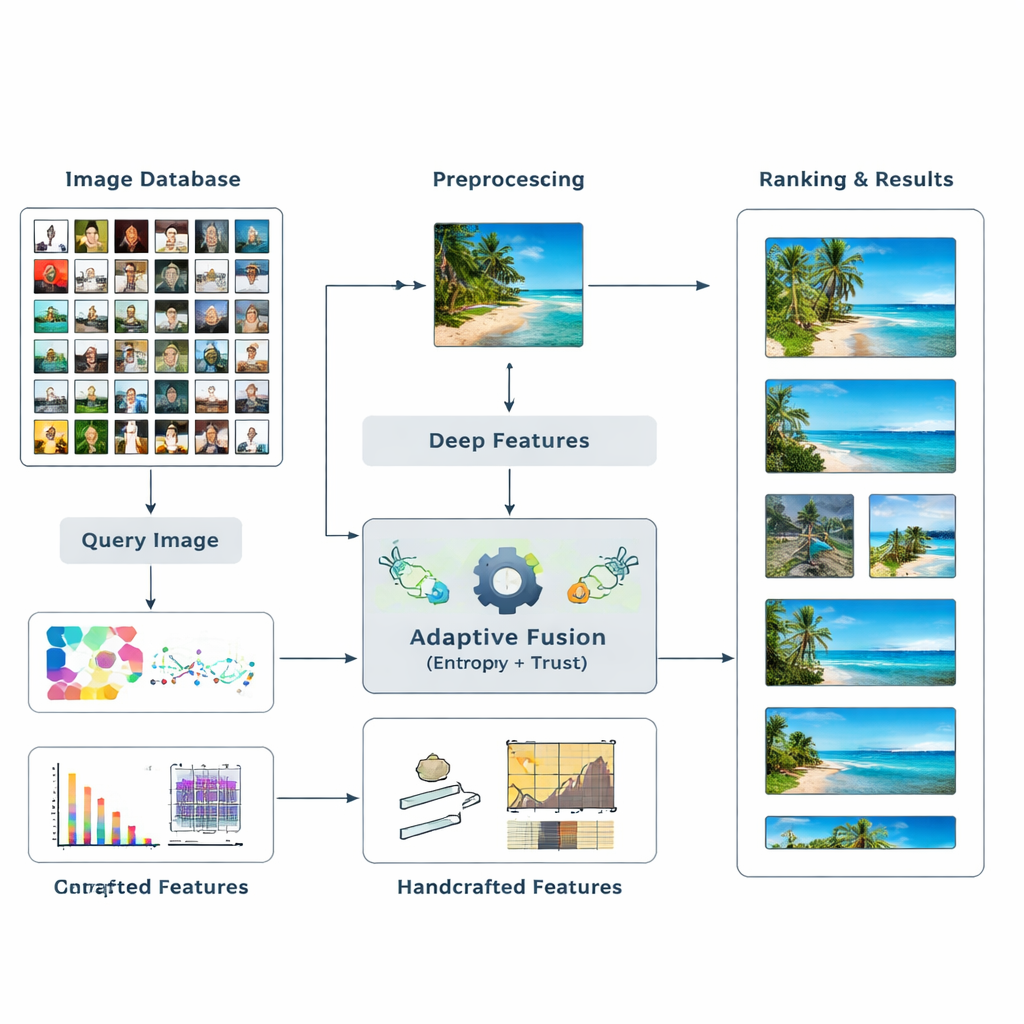
Deixando Informação e Confiança Definirem os Pesos
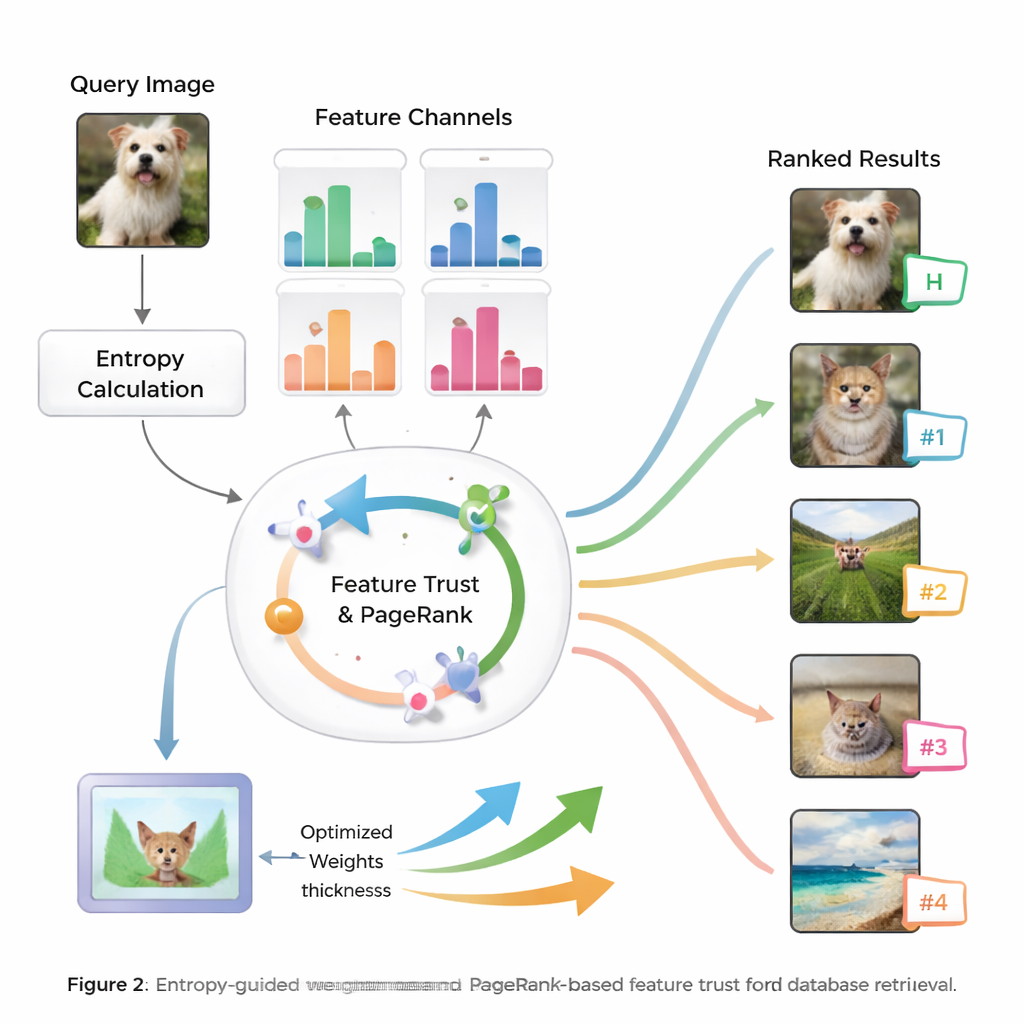
No cerne do método está a ideia de entropia, uma medida de quão incerta ou dispersa é a informação. Características que consistentemente separam imagens relevantes das irrelevantes têm entropia menor e são tratadas como mais “discriminativas”. Para uma nova consulta, o sistema avalia como cada característica se comporta ao longo do banco de dados e atribui a ela uma pontuação inicial de importância. Em seguida, examina quão confiáveis são os resultados de busca de cada característica — se as melhores correspondências realmente se parecem com a consulta — construindo uma noção de “confiança” para cada tipo de pista. Essas pontuações de confiança são alimentadas em um processo semelhante ao PageRank, análogo ao modo como os primeiros motores de busca da web decidiram quais páginas eram mais importantes, para refinar os pesos das características por meio de uma rede de transferência probabilística.
De Pesos Inteligentes a Rankings Melhores
Uma vez que o sistema aprendeu quanto confiar em cada característica para a consulta atual, ele combina suas pontuações de similaridade em uma medida global para cada imagem do banco de dados. As imagens são então ranqueadas por essa pontuação abrangente, de modo que aquelas que correspondem à consulta nas formas mais significativas sobem ao topo. Os autores testam sua abordagem em benchmarks de imagens amplamente usados e a comparam com vários métodos existentes. Relatam ganhos de até 8,6% em média de precisão (mean average precision) e melhorias notáveis na qualidade dos dez melhores resultados, tanto em precisão quanto em relevância da ordenação. Testes estatísticos mostram que essas melhorias dificilmente se devem ao acaso, sugerindo que o sistema é ao mesmo tempo preciso e estável em muitos tipos de imagem.
O Que Isso Significa para a Busca Cotidiana de Imagens
Em termos simples, esta pesquisa mostra como construir motores de busca de imagens que se adaptam a cada consulta em vez de depender de regras rígidas. Ao permitir que o conteúdo informacional e a confiança conquistada decidam quais pistas visuais importam mais, o sistema pode encontrar as imagens certas com maior frequência — seja identificando uma impressão digital em um vasto banco de dados de crimes, localizando um prédio específico em fotografias de satélite ou recuperando o exame médico correto. Os autores reconhecem que o método é computacionalmente mais pesado do que sistemas mais simples, mas argumentam que sua maior confiabilidade e precisão o tornam adequado para repositórios de imagens grandes e críticos, onde obter a imagem correta realmente importa.
Citação: Lavanya, M., Vennira Selvi, G., Gopi, R. et al. Entropy guided multi level feature fusion network for high precision content based image retrieval. Sci Rep 16, 7449 (2026). https://doi.org/10.1038/s41598-026-38699-x
Palavras-chave: recuperação de imagens baseada em conteúdo, aprendizado profundo, fusão de características, busca de imagens, ponderação por entropia