Clear Sky Science · pt
Pré-treinamento no ImageNet e aprendizado por transferência em duas etapas na classificação de imagens de cromossomos
Visões mais nítidas dos nossos cromossomos
Nossos cromossomos carregam as instruções para construir e operar nossos corpos, e os médicos estudam suas formas para detectar distúrbios genéticos e alguns cânceres. Hoje, computadores podem ajudar a interpretar imagens de cromossomos, mas ensiná-los a fazer isso bem é difícil porque imagens médicas são escassas e muito diferentes de fotos do dia a dia. Este estudo faz uma pergunta simples com grande impacto prático: computadores aprendem melhor a partir de imagens médicas relacionadas, e não apenas de enormes coleções de fotos de gatos, cachorros e carros?
Por que imagens de cromossomos importam
Nos hospitais, especialistas organizam os 46 cromossomos de uma pessoa em um gráfico chamado cariótipo, agrupados em 24 tipos (22 pares numerados mais X e Y). Faixas sutis claras e escuras ao longo de cada cromossomo ajudam a revelar peças faltantes ou extras associadas a condições como síndrome de Down ou certas leucemias. Tradicionalmente, os especialistas classificam essas faixas a olho, o que é lento e subjetivo. Deep learning oferece uma forma de automatizar esse trabalho, mas esses sistemas geralmente começam a partir de modelos treinados no ImageNet, um conjunto massivo de fotos cotidianas. Essa transição — de fotos de férias para vistas ao microscópio de cromossomos — é enorme, e não está claro o quanto essa experiência realmente transfere.
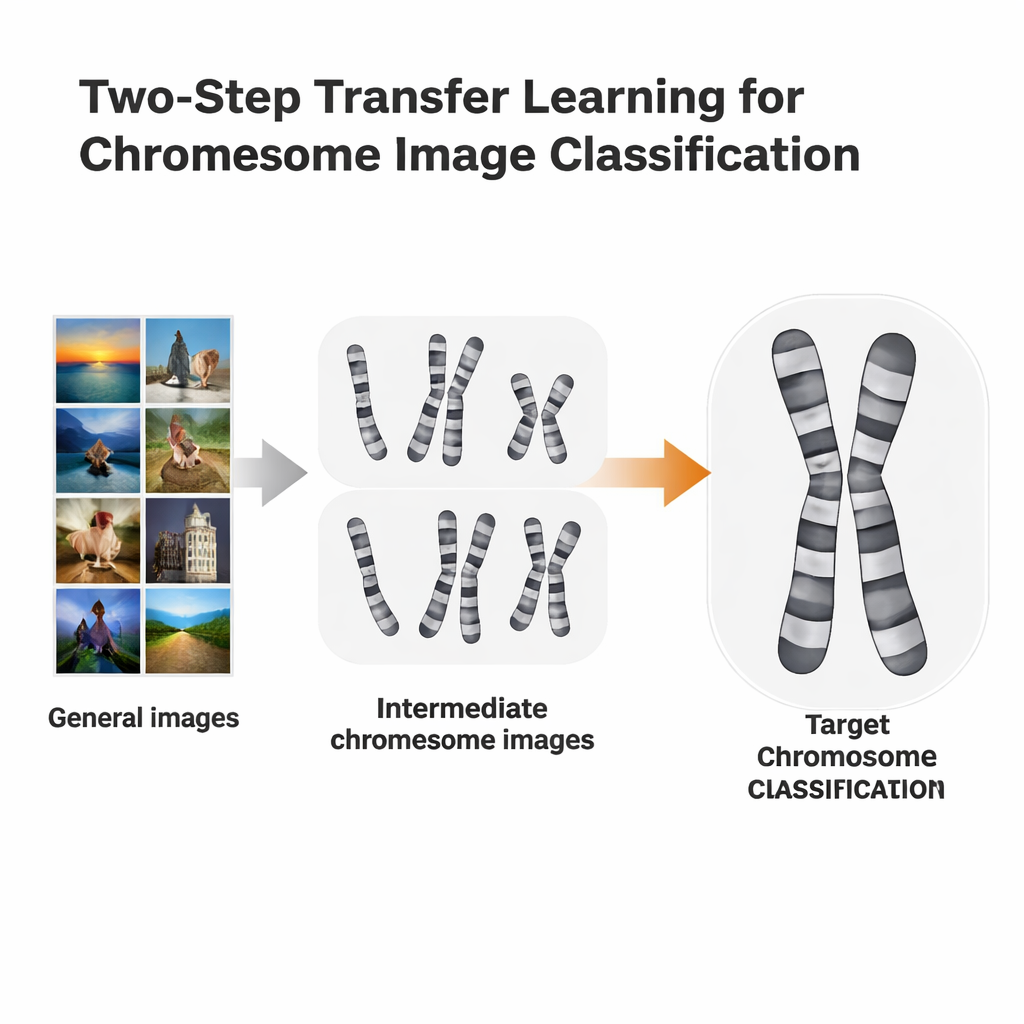
Um atalho de aprendizado em duas etapas
Os pesquisadores testaram uma rota de treinamento mais adaptada chamada aprendizado por transferência em duas etapas. Em vez de ir direto do ImageNet para uma tarefa específica de cromossomos, primeiro ajustaram finamente modelos treinados no ImageNet em imagens de cromossomos de um método de coloração, e então ajustaram novamente para um segundo método, ligeiramente diferente. Eles usaram dois conjuntos de dados abertos: imagens Q-band, que têm qualidade menor e são mais difíceis de ler, e imagens G-band, que são mais limpas e detalhadas. Cada conjunto de dados alternou no papel de “pedra de apoio” para o outro. A ideia é similar ao aprendizado de idiomas: se você já fala espanhol, pode ser mais fácil aprender italiano do que pular diretamente do inglês.
Testando muitos “olhos” computacionais
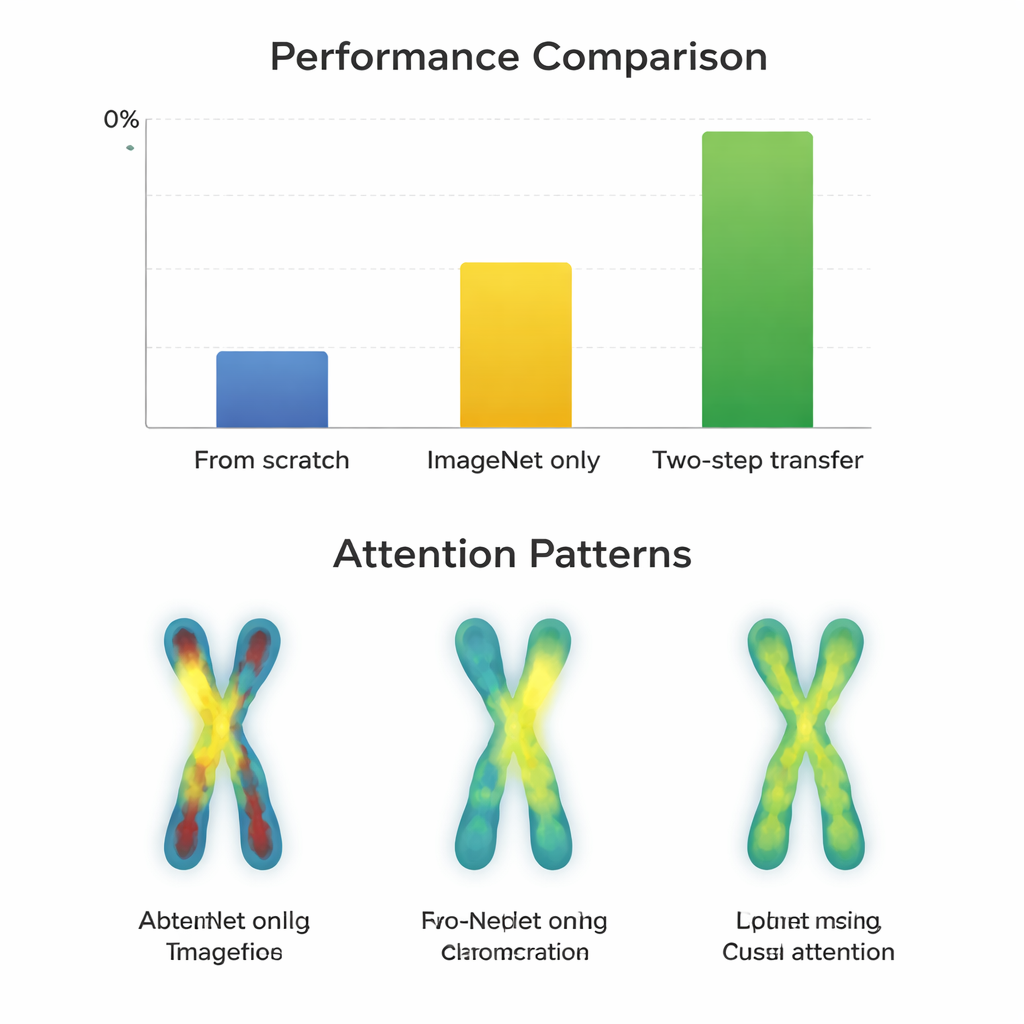
Para ver quando esse passo extra ajuda, a equipe treinou 66 classificadores diferentes, combinando 11 arquiteturas de redes neurais populares com três estratégias: treinar do zero, ajustar a partir do ImageNet apenas, e usar transferência em duas etapas. Eles mediram desempenho usando Macro-F1, uma pontuação que trata todos os tipos de cromossomos de forma justa, incluindo os raros. Primeiro, confirmaram que imagens Q-band e G-band são estatisticamente mais semelhantes entre si do que cada uma é em relação às fotos do ImageNet, o que as torna promissoras como etapas intermediárias. Em seguida, compararam quão bem os diferentes modelos aprendiam sob cada estratégia, tanto no conjunto mais fácil (G-band) quanto no mais difícil (Q-band).
Quando o passo extra compensa
Nas imagens G-band de maior qualidade, quase todos os modelos já tiveram desempenho extremamente bom após o simples ajuste a partir do ImageNet, com pontuações em torno de 97–98%. Aqui, o treinamento em duas etapas trouxe ganhos diminutos — muitas vezes menos de um ponto percentual — e às vezes até prejudicou arquiteturas mais antigas. Em contraste, nas imagens Q-band mais desafiadoras, a história mudou. Arquiteturas modernas e compactas, como ConvNeXt, Swin Transformer, Vision Transformer e MobileNetV3, claramente se beneficiaram da rota em duas etapas, melhorando cerca de 0,8 a 3,3 pontos percentuais em relação ao ImageNet sozinho. Mapas de atenção mostrando onde os modelos “olhavam” explicaram o motivo: com a transferência em duas etapas, as redes focalizaram-se de forma mais uniforme ao longo das faixas dos cromossomos em ambos os braços, em vez de apenas nos contornos ou em uma região única. No entanto, redes muito grandes e antigas, como VGG, não ganharam e às vezes pioraram, o que sugere que um design mais inteligente supera o simples tamanho.
Limites impostos pelos próprios dados
Os pesquisadores também examinaram erros em imagens G-band. Algumas falhas foram atribuídas não à estratégia de aprendizado, mas a entradas defeituosas, como cromossomos que haviam sido recortados de forma inadequada ao separar formas sobrepostas. Nesses casos, todos os métodos de treinamento tiveram dificuldade, e os mapas de atenção ficaram dispersos ou fixados em bordas enganosas. Isso ressalta uma mensagem prática para clínicas e desenvolvedores: mesmo o melhor pipeline de treinamento não consegue superar totalmente má qualidade de imagem ou erros de pré-processamento, especialmente quando se trabalha com conjuntos de dados modestos, como os disponíveis para imagens de cromossomos.
O que isso significa para o diagnóstico no mundo real
Para não especialistas, a conclusão chave é que a reutilização inteligente de imagens médicas relacionadas pode tornar a leitura automatizada de cromossomos mais precisa — especialmente quando os dados-alvo são ruidosos ou escassos e quando se usam redes neurais modernas e bem projetadas. Para imagens de alta qualidade, o treinamento padrão baseado no ImageNet pode já ser suficiente. Mas quando patologistas trabalham com conjuntos de dados mais difíceis, um passo extra de aprendizado usando um tipo de imagem intimamente relacionado pode afiar o “olhar” do computador, elevando o desempenho para a faixa de 93–98%. Essa abordagem pode se estender além dos cromossomos para muitas áreas de imagem médica onde há poucos rótulos, ajudando a levar ferramentas de IA confiáveis mais perto da prática clínica diária.
Citação: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Palavras-chave: classificação de cromossomos, IA em imagens médicas, aprendizado por transferência, modelos de deep learning, cariótipo