Clear Sky Science · pt
FedSCOPE: Recomendação sequencial federada entre domínios com aprendizado contrastivo desacoplado e aprimoramento semântico preservador de privacidade
Por que recomendações mais inteligentes e seguras são importantes
Cada vez que você navega por filmes, faz compras online ou lê avaliações, sistemas de recomendação decidem discretamente o que mostrar a seguir. À medida que nossa vida digital se espalha por vários apps e sites, esses sistemas poderiam ser muito melhores se pudessem aprender com toda a sua atividade de uma só vez — sem jamais expor seus dados privados. Este artigo apresenta o FedSCOPE, uma nova forma de diferentes plataformas colaborarem em recomendações que são tanto mais precisas quanto mais respeitosas com a privacidade dos usuários.
O problema com os mecanismos de recomendação atuais
A maioria dos sistemas de recomendação atuais vive dentro de um único app ou site e vê apenas uma fatia estreita do seu comportamento. Isso significa que eles têm dificuldade com usuários “cold-start” que têm pouco histórico, ou com produtos de nicho com poucas interações. Quando empresas tentam combinar dados entre domínios — como livros e filmes, ou alimentos e utensílios de cozinha — elas enfrentam três grandes problemas: os dados costumam ser esparsos, diferentes plataformas têm tipos de usuários e atividades muito distintas, e regras rígidas de privacidade tornam arriscado reunir dados brutos em um só lugar. Correções simples, como adicionar a mesma quantidade de ruído preservador de privacidade para todos, tendem a enfraquecer a proteção ou prejudicar severamente a precisão.
Deixando modelos de linguagem preencherem as lacunas
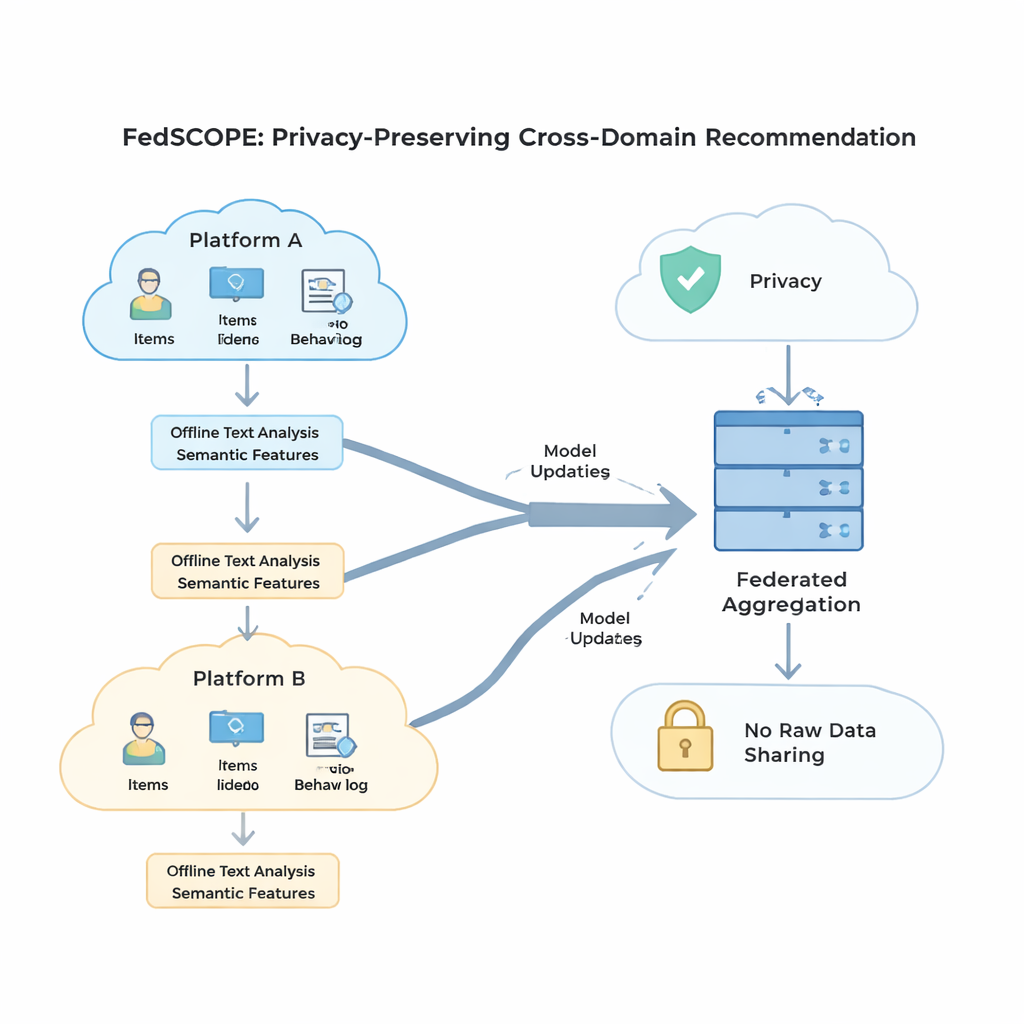
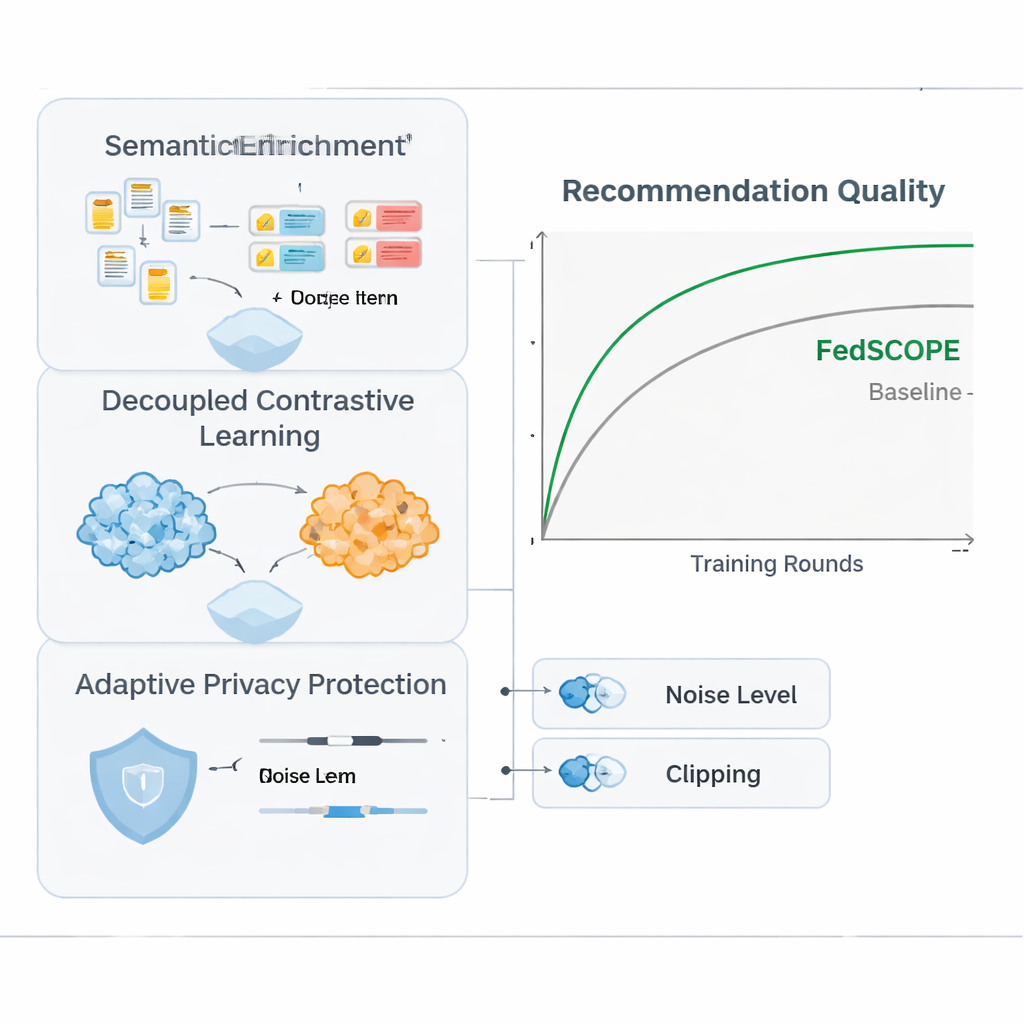
O FedSCOPE enfrenta o problema da esparsidade fazendo com que cada plataforma enriqueça seus dados usando um grande modelo de linguagem (LLM), mas de uma maneira incomum e consciente da privacidade. Em vez de enviar históricos de usuários a um serviço de IA remoto a cada recomendação, cada cliente executa um processo offline único: alimenta títulos e informações básicas dos itens (por exemplo, nome e gênero de um filme) a um LLM e solicita descrições estruturadas, como temas prováveis, hábitos de visualização ou interesses relacionados. Esses atributos gerados permanecem no dispositivo ou servidor local e são fundidos com os históricos habituais de cliques e visualizações usando uma rede neural leve. Isso dá ao sistema uma percepção mais rica tanto dos usuários quanto dos itens, o que é especialmente útil quando há poucas interações registradas. Como o processo é offline e local, o comportamento bruto nunca sai da plataforma, e não há dependência contínua de serviços de IA externos.
Separando o que é pessoal do que é compartilhado
Para aproveitar comportamentos vindos de múltiplos domínios sem misturar sinais de forma prejudicial, o FedSCOPE introduz uma estratégia de treinamento chamada aprendizado contrastivo desacoplado. Em termos simples, o sistema aprende duas coisas ao mesmo tempo. Primeiro, dentro de cada domínio — por exemplo, apenas o lado dos filmes — ele aproxima usuários que se comportam de forma semelhante e afasta os que não, afinando a noção de gosto pessoal naquele ambiente. Segundo, entre domínios, alinha representações do mesmo usuário enquanto mantém usuários diferentes distintos, de modo que o que você assiste possa ajudar a prever o que você pode ler ou comprar, sem confundi-lo com outros. Ao tratar separadamente esses objetivos “dentro do domínio” e “entre domínios”, o método evita uma armadilha comum em que forçar tudo a um único molde compartilhado destrói preferências granulares.
Protegendo a privacidade sem sacrificar a utilidade
Privacidade matemática forte, conhecida como privacidade diferencial, geralmente significa adicionar ruído aleatório às atualizações do modelo antes de compartilhá-las com um servidor central. Muitos sistemas anteriores usavam as mesmas configurações de privacidade para todos os participantes, o que é um ajuste ruim quando alguns clientes têm milhões de usuários e outros apenas alguns milhares. O FedSCOPE, em vez disso, dá a cada cliente um orçamento de privacidade personalizado e adapta quanto recorta (clipping) e perturba suas atualizações com base no tamanho dos dados e no comportamento passado. Plataformas grandes e ricas em dados podem contribuir com informação mais precisa sem serem excessivamente ruidosas, enquanto as menores são protegidas de forma mais agressiva. Todas as atualizações são então combinadas usando agregação segura, de modo que o servidor nunca vê qualquer contribuição individual em claro.
O que os experimentos mostram na prática
Os autores testaram o FedSCOPE em dados de compras do mundo real da Amazon, combinando domínios como Filmes com Livros e Alimentos com Cozinha. Eles o compararam com uma série de métodos modernos de recomendação, incluindo outras abordagens preservadoras de privacidade e entre domínios. Em diversas métricas de acurácia, o FedSCOPE consistentemente ficou no topo ou perto dele. Convergiu mais rápido durante o treinamento, funcionou melhor para usuários com pouquíssimas interações passadas e se manteve robusto quando o número de clientes participantes ou a fração amostrada em cada rodada mudaram. Importante: quando a equipe apertou as restrições de privacidade, a estratégia adaptativa do FedSCOPE manteve o desempenho muito superior ao de sistemas que usam privacidade diferencial única para todos.
O que isso significa para usuários comuns
Do ponto de vista de um leigo, o FedSCOPE aponta para um futuro em que seus apps favoritos podem colaborar para entender seus gostos mais profundamente sem jamais reunir seus dados brutos. Ao enriquecer históricos esparsos com insights de modelos de linguagem, separar cuidadosamente o que é específico do domínio do que é compartilhado e ajustar controles de privacidade para cada participante, o framework oferece recomendações que são ao mesmo tempo mais relevantes e mais respeitosas com informações pessoais. Em termos práticos, isso pode significar sugestões melhores sobre o que assistir, ler ou comprar a seguir — sem precisar abrir mão da sua privacidade digital.
Citação: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
Palavras-chave: recomendação federada, IA preservadora de privacidade, personalização entre domínios, grandes modelos de linguagem, privacidade diferencial