Clear Sky Science · pt
Explorando a interação professor‑aluno por meio de modelos de linguagem multimodais: uma investigação empírica
Por que observar salas de aula com IA importa
Quem já passou tempo em uma sala de aula sabe que a maneira como professores e alunos interagem pode fazer a diferença entre tédio e aprendizagem efetiva. Ainda assim, é surpreendentemente difícil estudar essas trocas momento a momento: observadores se cansam, julgamentos humanos divergem e os dados em vídeo rapidamente se tornam avassaladores. Este artigo explora como um novo tipo de inteligência artificial — grandes modelos de linguagem multimodais que podem “ver” imagens e “ler” textos — pode ajudar pesquisadores e escolas a entender a complexidade da vida em sala de aula de maneira mais rápida e objetiva.
Transformando aulas reais em dados de pesquisa
Os pesquisadores partiram de vídeos de aulas comuns de escolas primárias e secundárias chinesas, disponibilizados publicamente em uma plataforma nacional de educação. A partir de 30 aulas, extraíram quase 2.400 imagens estáticas que capturavam momentos-chave do ensino e da aprendizagem. Cada imagem foi rotulada segundo cinco padrões de interação fáceis de compreender: guiada (professor explicando), colaborativa (estudantes trabalhando juntos), questionamento (perguntas e respostas), independente (alunos trabalhando sozinhos) e expositiva (alunos apresentando para a turma). Especialistas em tecnologia educacional ajudaram a refinar essas categorias para que correspondessem ao que observadores experientes procuram em salas de aula reais.
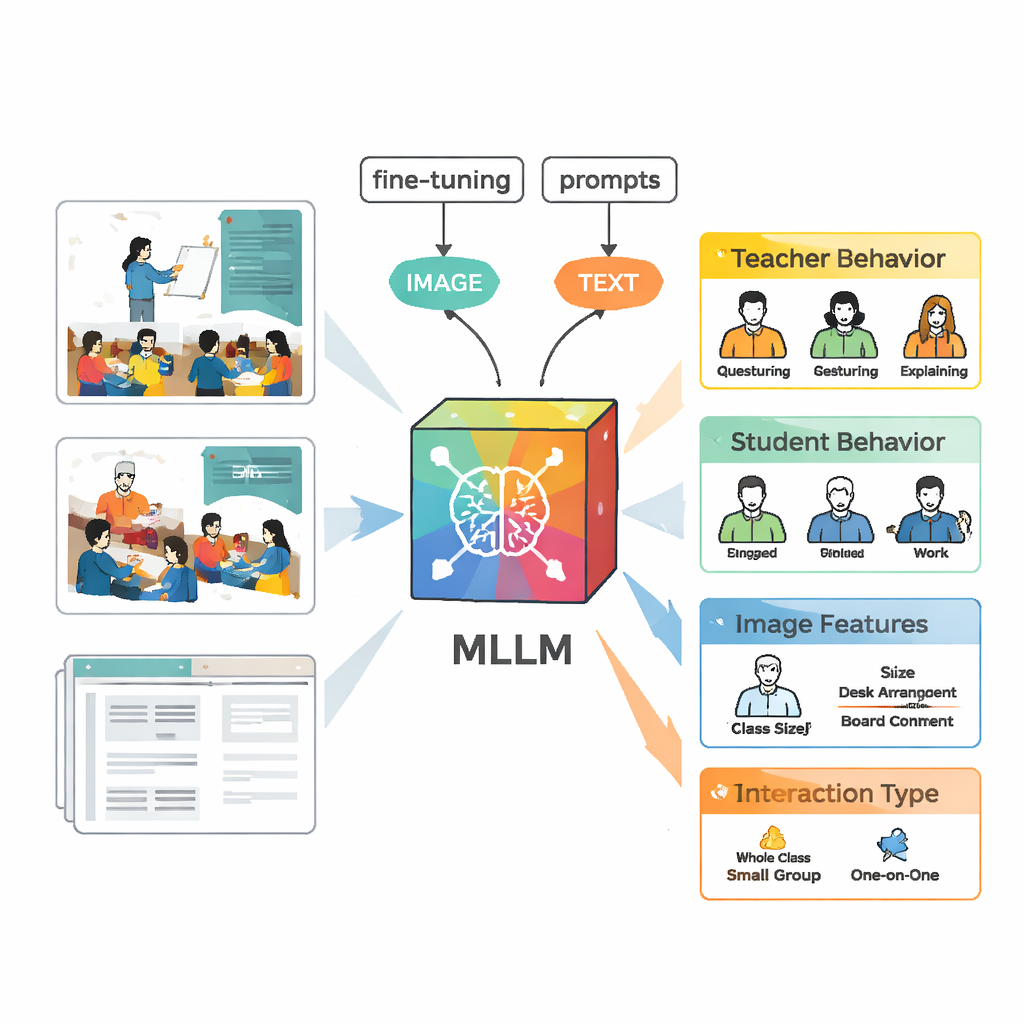
Ensinando uma IA a enxergar a dinâmica da sala de aula
Para analisar essas cenas, a equipe usou um grande modelo de linguagem multimodal chamado VisualGLM‑6B, que aceita imagens e texto como entrada. Como o modelo original foi treinado de forma ampla e não especificamente em contextos escolares, os pesquisadores o “ajustaram” (fine‑tuned) usando suas imagens rotuladas. Adotaram uma técnica chamada LoRA que ajusta apenas um pequeno número de parâmetros internos do modelo, tornando o treinamento mais eficiente, sem perder potência. Também elaboraram prompts cuidadosos — instruções estruturadas que orientam o modelo a descrever o comportamento do professor, o comportamento dos alunos, características visuais e o tipo de interação em um formato consistente, para que a saída fosse mais fácil de comparar com os julgamentos de especialistas humanos.
Construindo rótulos melhores com humanos e máquinas
Criar um conjunto de treinamento de alta qualidade exigiu mais do que simplesmente apontar o modelo para vídeos. Primeiro, o VisualGLM produziu descrições básicas de cada imagem. Anotadores humanos então corrigiram erros e preencheram contextos faltantes, como quem estava falando ou se os alunos estavam ouvindo ou discutindo. Em seguida, essas descrições lapidadas foram inseridas no ChatGPT que, guiado por prompts customizados, gerou análises estruturadas seguindo as cinco categorias de interação. Especialistas revisaram e editaram novamente essas análises geradas pela IA. O resultado final foi um conjunto de dados rico, no qual cada imagem trazia um relato detalhado e confiável do que professores e alunos estavam fazendo.
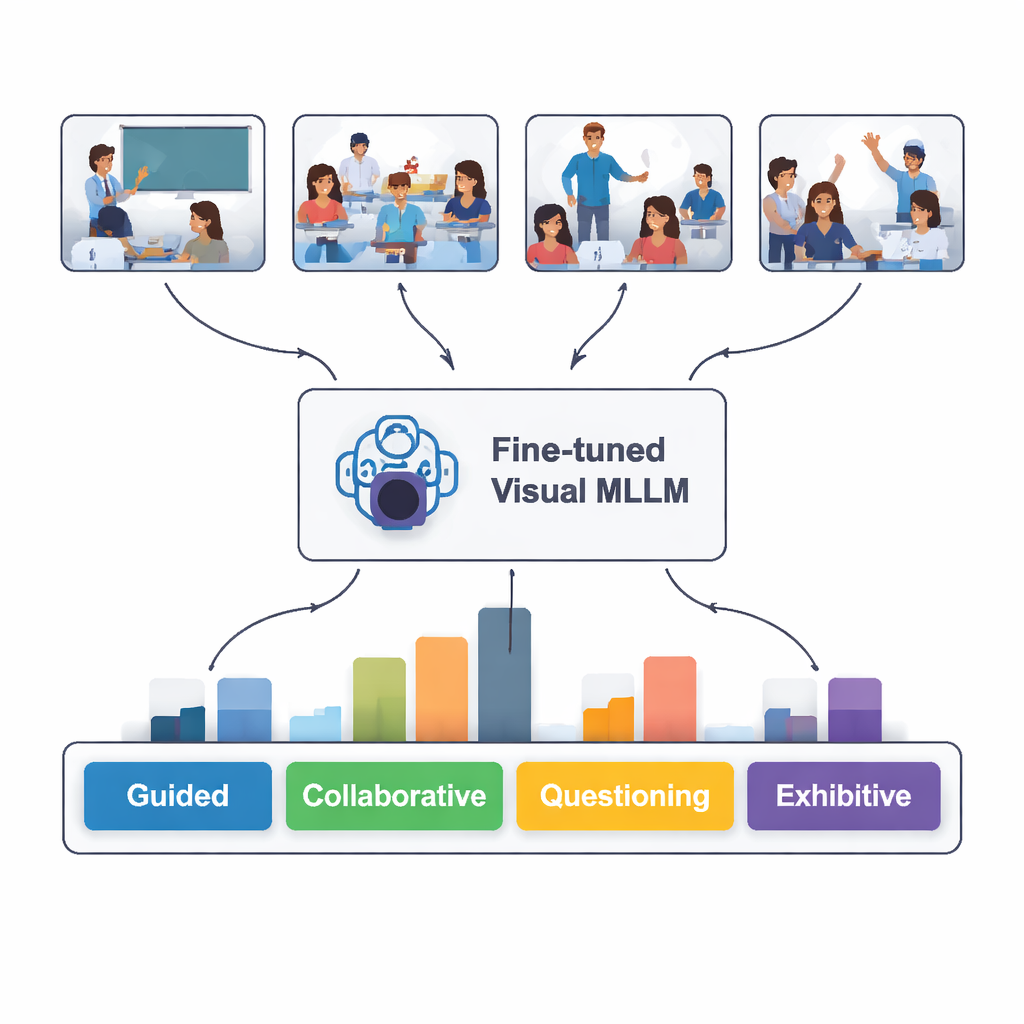
Quão bem a IA “leu” a sala de aula?
Quando testado em 100 novas imagens de sala de aula que nunca havia visto, o modelo ajustado identificou corretamente o tipo de interação em 82% dos casos. Teve melhor desempenho ao reconhecer situações guiadas, independentes e expositivas — quando o professor está claramente explicando, os alunos trabalham em silêncio por conta própria ou um aluno apresenta na frente. Teve mais dificuldade com trabalho colaborativo e questionamento, onde linguagem corporal e disposição dos assentos podem ser ambíguas mesmo para humanos. Uma comparação textual mais profunda mostrou que as descrições escritas pelo modelo frequentemente correspondiam de perto às análises de especialistas, embora ele ocasionalmente “alucine” detalhes não presentes nas imagens ou interprete mal um gesto sutil.
O que isso significa para as salas de aula do futuro
Para um leitor leigo, a mensagem central é que sistemas de IA estão se tornando capazes de observar salas de aula e resumir como o ensino e a aprendizagem se desenrolam, com um nível de estrutura e consistência difícil de manter por humanos ao longo de milhares de cenas. Embora não sejam perfeitos — especialmente para formas sutis de discussão e questionamento — a abordagem demonstra que grandes modelos de linguagem multimodais já podem apoiar pesquisas educacionais e, eventualmente, ferramentas de feedback para sala de aula. À medida que esses modelos passarem a incluir som, gestos e conjuntos de dados maiores e mais variados, poderão ajudar professores a identificar padrões em sua prática que antes estavam ocultos, oferecendo uma nova lente sobre como interações cotidianas moldam a aprendizagem dos alunos.
Citação: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
Palavras-chave: interação professor‑aluno, análise de sala de aula, IA multimodal, tecnologia educacional, grandes modelos de linguagem