Clear Sky Science · pt
Classificação incremental inteligente usando uma rede neural dinâmica aprimorada por gafanhotos para fluxos de dados
Por que dados em constante mudança importam
De redes de energia e fábricas a pagamentos online, sistemas modernos geram dados a cada segundo. Ocultos nesses fluxos contínuos estão alertas precoces sobre falhas de equipamentos, ciberataques ou aumentos iminentes de preços. O desafio é que esse rio de informação nunca para e seu comportamento continua mudando ao longo do tempo. O artigo resumido aqui introduz uma nova forma de treinar redes neurais para que elas possam continuar aprendendo a partir desses dados em tempo real sem desacelerar ou perder precisão, tornando-as mais úteis para monitoramento e tomada de decisão no mundo real.
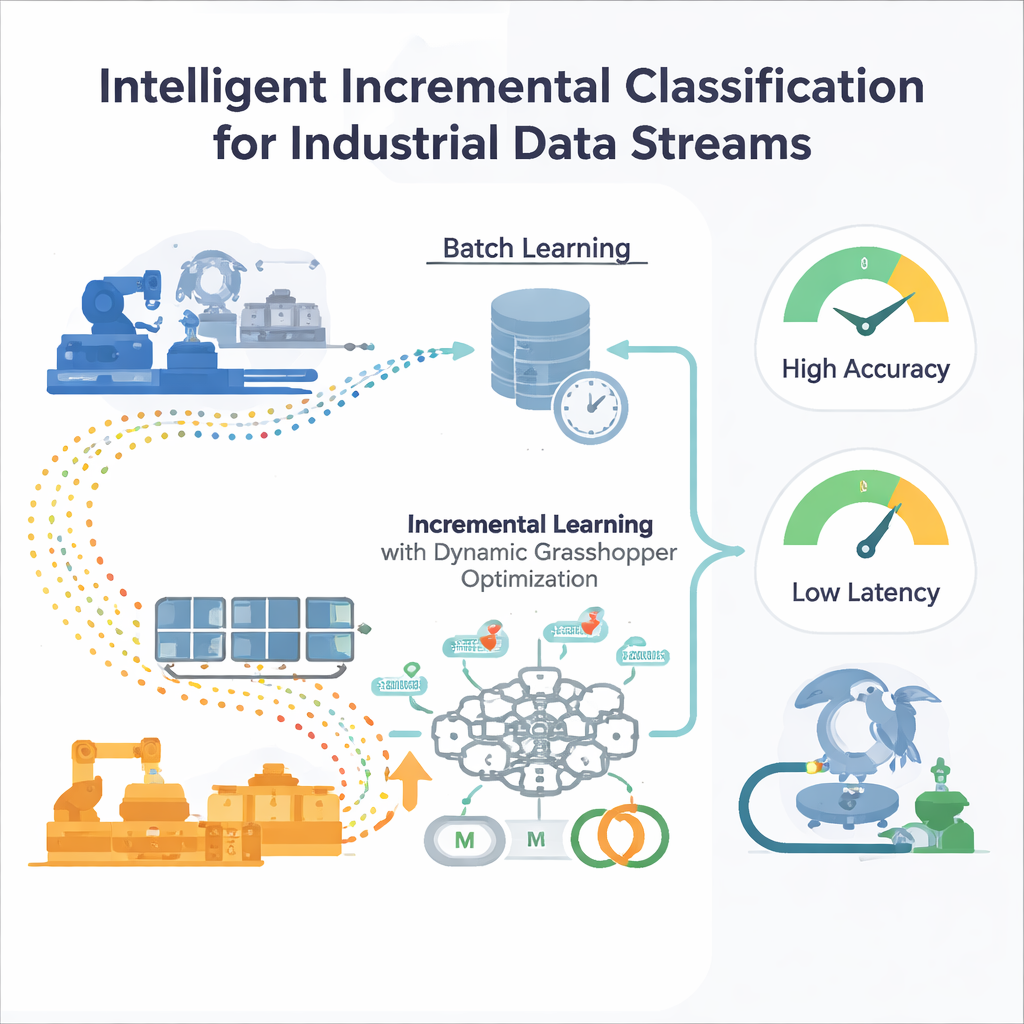
Os limites do treinamento pontual
A maioria dos modelos tradicionais de aprendizado de máquina é treinada em "lotes": engenheiros coletam um grande conjunto de dados históricos, ajustam o modelo e então o implantam. Isso funciona se o mundo permanecer aproximadamente o mesmo. Mas em ambientes industriais, as condições derivam—padrões de demanda mudam, sensores envelhecem, mercados flutuam. Um modelo congelado no tempo gradualmente fica cego a novos padrões, e retreiná-lo do zero em conjuntos de dados cada vez maiores é caro e lento. Métodos padrão de ajuste automático, como busca em grade ou algoritmos evolutivos, também pressupõem dados fixos, o que significa que precisam ser reiniciados sempre que a distribuição dos dados muda, algo impraticável para sistemas sempre ativos.
Uma rede neural que aprende em tempo real
Os autores propõem uma estrutura de aprendizado incremental centrada em um perceptron multicamadas (MLP), um tipo comum de rede neural. Em vez de alimentar a rede com todos os dados passados de uma vez, o fluxo de dados que chega é dividido em janelas manejáveis. Cada nova janela torna-se um pequeno passo de treinamento que atualiza os pesos internos da rede e então é descartada—uma estratégia de "treinar e esquecer" que mantém baixo o uso de memória. Crucialmente, o sistema não depende de configurações de treinamento fixas. Dois controles-chave que governam o comportamento de aprendizado—a taxa de aprendizado (o tamanho de cada atualização) e o momentum (o quão suavemente as atualizações se movem)—são ajustados continuamente à medida que o fluxo evolui, para que o modelo possa continuar responsivo sem se tornar instável.
Gafanhotos como afinadores inteligentes de parâmetros
Para lidar com esse ajuste contínuo, o artigo usa um otimizador inspirado na natureza chamado Algoritmo Dinâmico de Otimização por Gafanhotos (DGOA). Imagine um enxame de gafanhotos virtuais explorando possíveis combinações de taxa de aprendizado e momentum. No início, eles vagueiam amplamente para procurar boas regiões; depois, afinam seus movimentos para refinar escolhas promissoras. Nesta variante dinâmica, o tamanho de passo e a atração em direção à melhor solução mudam ao longo do tempo com base no desempenho da rede neural. O sistema também monitora "deriva de conceito"—mudanças súbitas nos erros de previsão ou nos próprios dados. Quando uma deriva é detectada, alguns gafanhotos são reiniciados e seus passos ficam temporariamente maiores, permitindo ao otimizador buscar rapidamente por novas regiões e escapar de configurações desatualizadas.
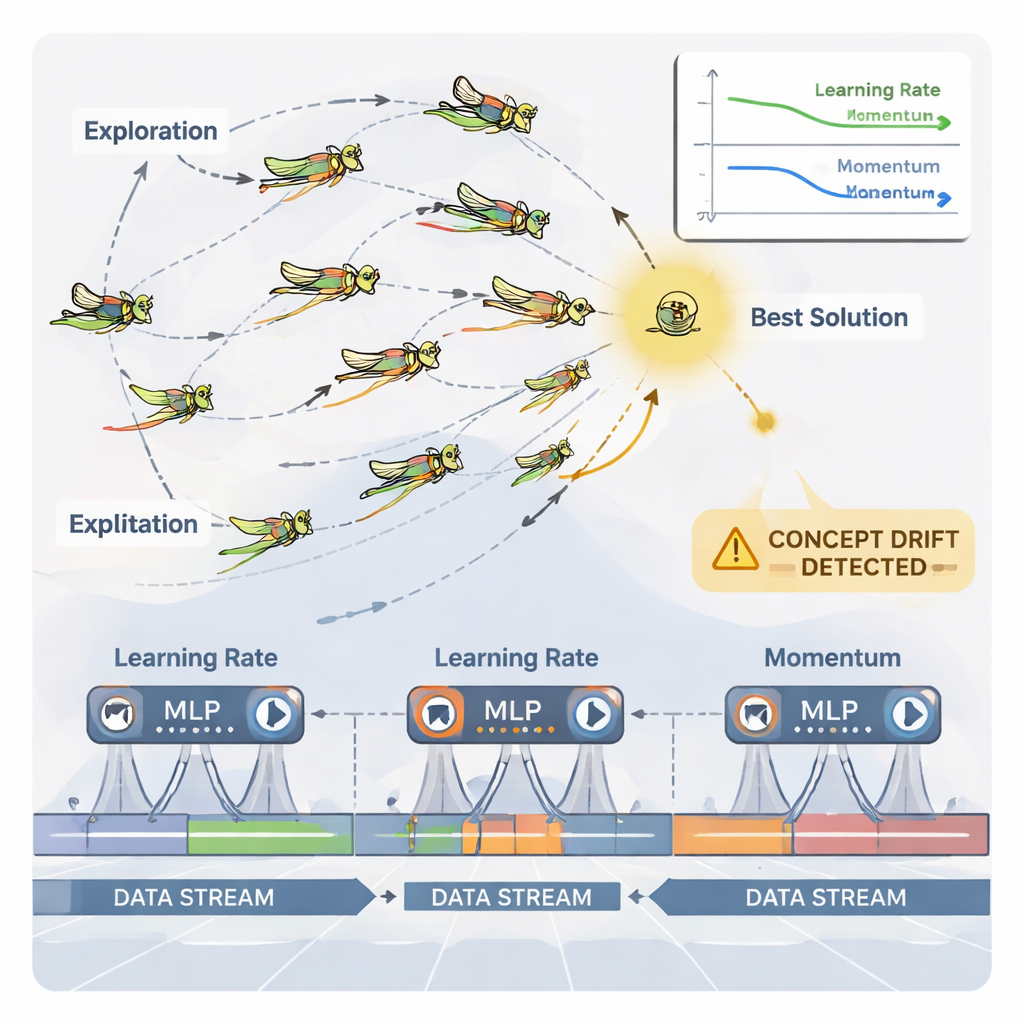
Colocando o método à prova
Os pesquisadores avaliaram sua abordagem em um conjunto de dados real do mercado de eletricidade da Austrália, onde o objetivo era prever se os preços subiriam ou cairiam. Em comparação com métodos comuns de ajuste, como busca em grade, busca aleatória, otimização por enxame de partículas, algoritmos genéticos, otimização por colônia de formigas e o algoritmo padrão de gafanhotos, a versão dinâmica emparelhada com aprendizado incremental alcançou a maior acurácia (cerca de 89,5%) enquanto usava menos tempo de computação e menos iterações. Experimentos adicionais mostraram que o método se adapta melhor tanto a fluxos de dados estáveis quanto a fluxos em mudança, escala de milhares a bilhões de amostras mantendo a memória sob controle, e tem desempenho competitivo em tarefas como manutenção preditiva, detecção de anomalias e detecção de fraude, bem como em benchmarks padrão de otimização matemática.
O que isso significa na prática
Para não especialistas, a conclusão é que este trabalho oferece uma forma de manter redes neurais "vivas" e bem ajustadas em ambientes onde os dados nunca param e as condições mudam constantemente. Em vez de parar repetidamente o sistema para reconstruir modelos do zero, a estrutura proposta permite que uma rede leve se atualize janela por janela, enquanto um otimizador baseado em enxame ajusta continuamente quão rápido e quão suavemente ela aprende. O resultado é adaptação mais rápida a novos padrões, melhor precisão de longo prazo e uso mais eficiente dos recursos de computação—ingredientes-chave para tomada de decisão confiável em tempo real em setores como energia, manufatura e finanças.
Citação: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Palavras-chave: fluxos de dados, aprendizado incremental, redes neurais, otimização de hiperparâmetros, inteligência de enxame