Clear Sky Science · pt
Um modelo de aprendizado de máquina interpretável usando dados clínicos rotineiros para previsão precoce de recidiva no carcinoma hepatocelular
Por que isso importa para pacientes e famílias
Para pessoas que passam por cirurgia para remover câncer de fígado, uma das perguntas mais urgentes é: “O câncer vai voltar em breve?” Hoje, os médicos só conseguem oferecer estimativas grosseiras, frequentemente baseadas em sistemas amplos de estadiamento que tratam muitos pacientes diferentes como se fossem iguais. Este estudo apresenta uma nova forma de usar informações que os hospitais já coletam — exames de sangue rotineiros e resultados de imagem — junto com inteligência artificial interpretável, para dar a cada paciente uma visão mais clara e personalizada do risco de curto prazo de recidiva.
Um câncer comum com uma taxa de retorno persistente
O carcinoma hepatocelular é o tipo mais comum de câncer primário do fígado e uma causa importante de mortes por câncer no mundo. Mesmo quando os cirurgiões removem completamente os tumores visíveis, mais de 70% dos pacientes veem a doença retornar em até cinco anos. A recidiva precoce — dentro de cerca de dois anos após a cirurgia — é especialmente preocupante, porque normalmente reflete células cancerígenas agressivas que já se espalharam dentro do fígado e reduz fortemente a sobrevida. Sistemas de estadiamento clínico existentes, como TNM ou Barcelona Clinic Liver Cancer (BCLC), conseguem classificar os pacientes em categorias amplas, mas muitas vezes falham em identificar quem está realmente em alto risco de recidiva precoce.
Transformando resultados de testes do dia a dia em uma pontuação de risco
Os pesquisadores utilizaram prontuários de 1.120 pacientes que se submeteram a cirurgia hepática com intenção curativa em dois hospitais importantes na China entre 2014 e 2024. Eles se concentraram apenas nas informações disponíveis antes da operação: idade e sexo, características de imagem como o tamanho do maior tumor e a presença de tumores múltiplos, e um amplo painel de exames laboratoriais padrão realizados nos dias que antecederam a cirurgia. A partir desses dados, selecionaram nove preditores chave ligados à chance de recidiva. Em vez de depender de uma única fórmula matemática, combinaram três abordagens diferentes de aprendizado de máquina e fizeram a média das previsões em uma única pontuação de risco entre 0 e 1. Os pacientes foram então agrupados em categorias de baixo, moderado e alto risco com base nessa pontuação. 
Superando os sistemas de estadiamento padrão
Para testar o desempenho do modelo, a equipe primeiro o avaliou em um conjunto “hold‑out” de pacientes do hospital original e depois em um grupo independente do segundo hospital. Em ambos os cenários, o novo modelo foi claramente superior aos sistemas de estadiamento tradicionais para distinguir quem permaneceria livre de câncer e quem teria recidiva dentro de 24 meses. No grupo de teste interno, a acurácia temporal do modelo, medida por uma estatística padrão chamada área sob a curva, foi de cerca de 0,76, comparada com aproximadamente 0,55 a 0,64 para métodos de estadiamento comuns. Pessoas no grupo de alto risco tiveram a pior sobrevida livre de recidiva, aquelas no grupo de risco moderado tiveram seu risco de recidiva reduzido em cerca de 60%, e as do grupo de baixo risco apresentaram um risco cerca de 90% menor do que o grupo de alto risco. Essas diferenças significativas também se mantiveram no hospital externo e permaneceram consistentes na maioria dos subgrupos, como pacientes mais jovens e mais velhos, homens e mulheres, e aqueles com tumores grandes ou pequenos.
Abrindo a caixa‑preta da inteligência artificial
Uma crítica frequente ao aprendizado de máquina na medicina é que ele age como uma caixa‑preta: pode prever bem, mas nem mesmo especialistas conseguem ver por quê. Para enfrentar isso, os autores aplicaram um método chamado SHapley Additive exPlanations, ou SHAP, que decompõe cada previsão em contribuições de cada fator de entrada. A análise mostrou que o tamanho do tumor foi o único motor mais forte de risco aumentado em todos os três algoritmos, seguido por características como o número de tumores e indicadores sanguíneos de função hepática e inflamação. Curiosamente, o nível de cloreto no sangue tendia a reduzir o risco, atuando como um fator protetor neste conjunto de dados. Para pacientes individuais, o modelo pode gerar gráficos simples em estilo barra que mostram, por exemplo, como um grande diâmetro tumoral e marcadores sanguíneos desfavoráveis elevam a pontuação de risco, enquanto melhor função hepática a reduz. 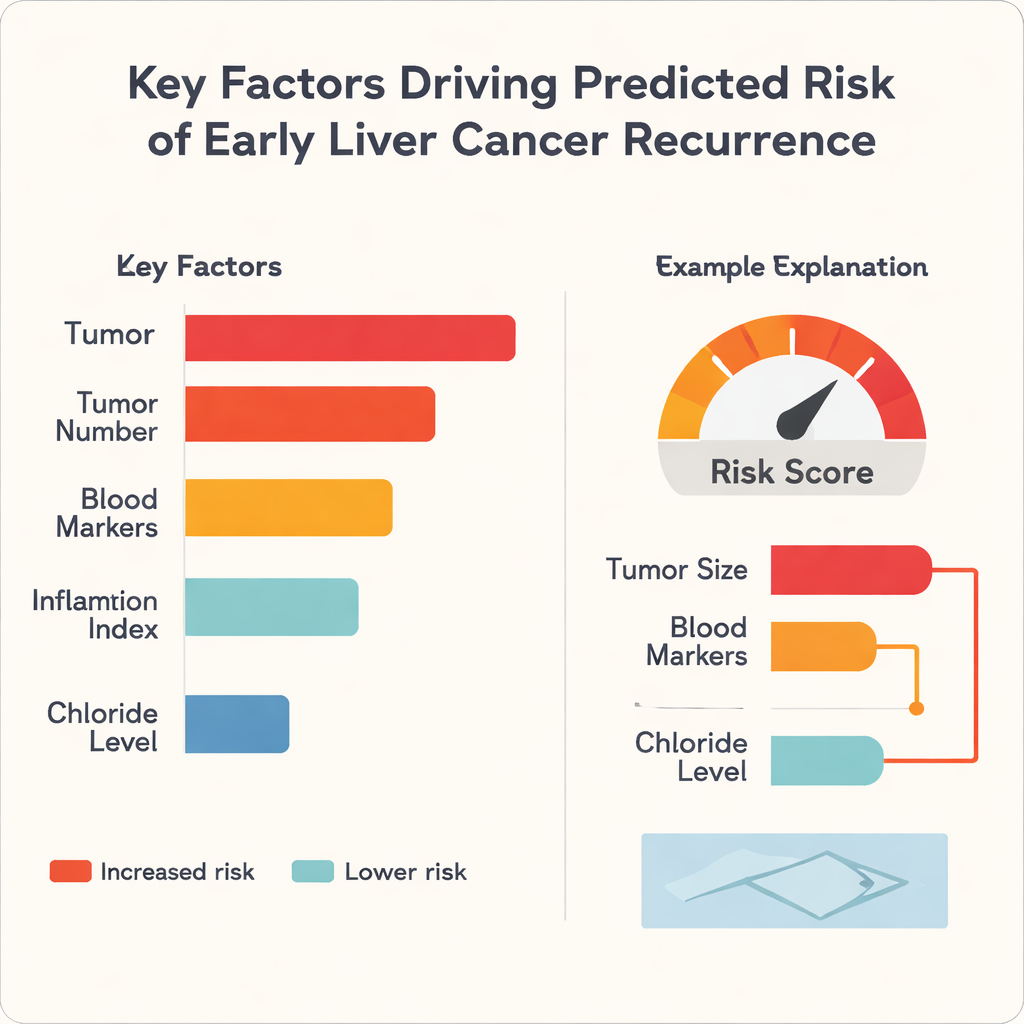
O que isso pode significar na clínica
Como o modelo usa dados que os hospitais já coletam e não requer exames especiais ou testes genéticos caros, ele poderia ser implementado em diferentes contextos de atenção, incluindo aqueles com recursos limitados. Antes da cirurgia, os médicos poderiam usá‑lo para identificar pessoas que necessitam de acompanhamento mais intenso ou que poderiam se beneficiar de tratamentos adicionais após a operação, ao mesmo tempo poupando pacientes genuinamente de baixo risco de exames e ansiedade desnecessários. Os autores observam que seu estudo é retrospectivo e baseado em uma população de pacientes específica, de modo que ensaios prospectivos em ambientes mais diversos ainda são necessários. Ainda assim, o trabalho ilustra como IA transparente e explicável pode transformar números de exames rotineiros e achados de imagem em previsões individualizadas e relevantes que apoiam a tomada de decisão compartilhada entre pacientes e suas equipes de cuidado.
Citação: Guo, DF., Wen, Q., Zhang, X. et al. An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma. Sci Rep 16, 7520 (2026). https://doi.org/10.1038/s41598-026-38484-w
Palavras-chave: recorrência do câncer de fígado, modelo de aprendizado de máquina, predição de risco clínico, IA interpretável, carcinoma hepatocelular