Clear Sky Science · pt
Um modelo híbrido explicável CNN–transformer para reconhecimento de língua de sinais em dispositivos de borda usando fusão adaptativa e destilação de conhecimento
Por que ferramentas compactas para língua de sinais importam
Bilhões de conversas diárias dependem de movimentos das mãos, expressões faciais e linguagem corporal em vez de palavras faladas. Ainda assim, a maioria dos telefones, tablets e dispositivos públicos ainda não consegue entender línguas de sinais, especialmente fora de países de língua inglesa. Este artigo apresenta o TinyMSLR, um sistema compacto e explicável de reconhecimento de língua de sinais projetado para rodar em tempo real em dispositivos pequenos e de baixo consumo. O objetivo é transformar hardware comum em auxiliares de comunicação acessíveis e confiáveis para pessoas surdas e com perda auditiva ao redor do mundo.
Trazer mais línguas para a conversa
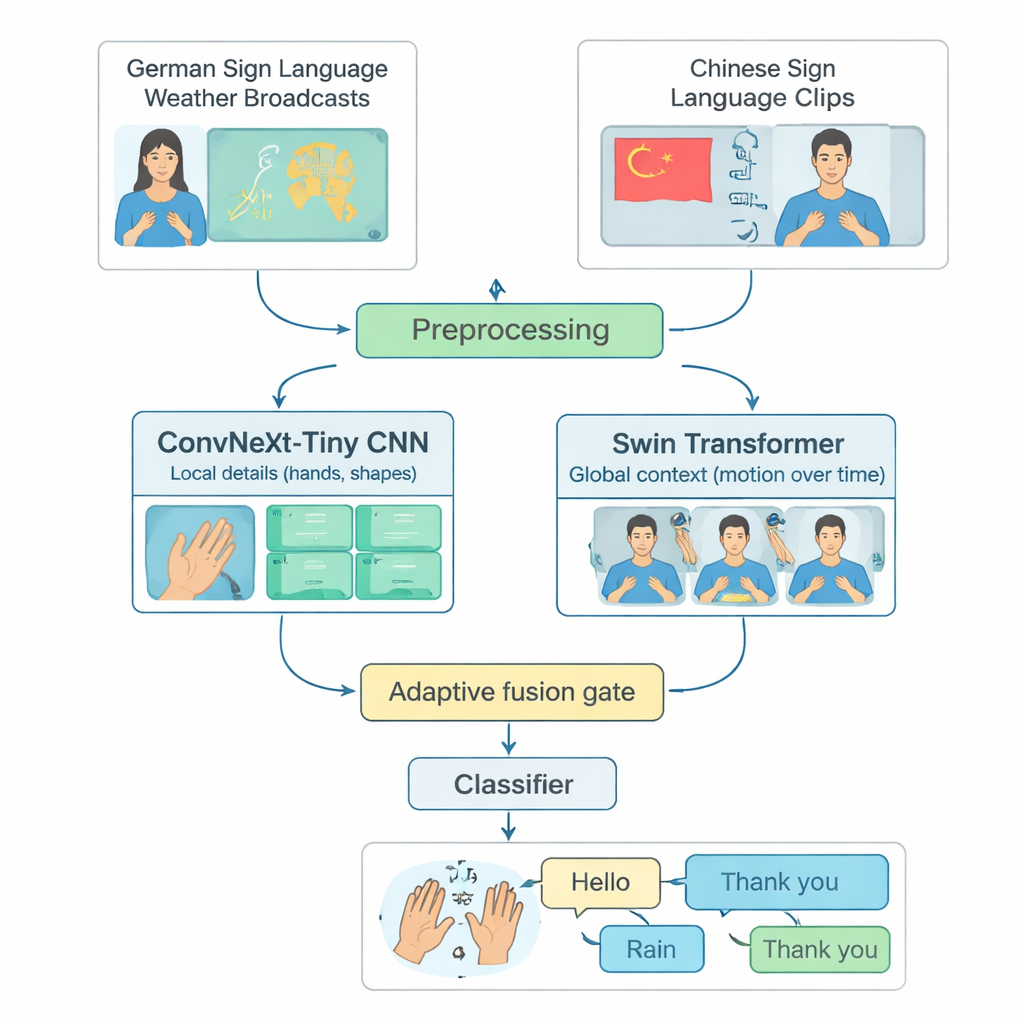
Muitos sistemas avançados de reconhecimento de língua de sinais concentram‑se em uma única língua, na maioria das vezes a American Sign Language, e só funcionam em computadores potentes. Isso exclui pessoas que usam outras línguas de sinais ou vivem em regiões com recursos computacionais limitados. Os autores enfrentam essa lacuna construindo um banco de testes compartilhado a partir de duas línguas diferentes: transmissões meteorológicas em Língua de Sinais Alemã e uma grande coleção de Língua de Sinais Chinesa. Eles selecionam cuidadosamente 20 sinais cotidianos comuns — como Olá, Tempo, Chuva, Feliz, Sim e Obrigado — que existem em ambas as línguas. Ao cortar vídeos longos em clipes curtos contendo apenas um sinal e balancear o número de exemplos por classe e por intérprete, criam uma maneira justa e reprodutível de avaliar quão bem um modelo reconhece sinais isolados entre línguas.
Como o modelo híbrido enxerga mãos e movimento
O TinyMSLR combina duas formas complementares de analisar vídeo. Um ramo usa uma rede convolucional moderna (ConvNeXt‑Tiny) que se destaca ao detectar detalhes finos, como a forma dos dedos e texturas sutis. O segundo ramo usa um Swin Transformer, uma família mais recente de modelos que sobressai em rastrear padrões no espaço e no tempo — como mãos, rosto e parte superior do corpo se movem ao longo de vários quadros. Cada clipe curto é padronizado para 32 quadros de 224×224 pixels, ligeiramente aumentados (por exemplo, pequenas rotações ou alterações de brilho) e então alimentados para ambos os ramos em paralelo. Cada ramo produz um resumo de 768 números do que observa; juntos, esses dois resumos capturam tanto detalhes locais nítidos quanto movimento e contexto mais amplos.
Deixar o modelo decidir o que importa mais
Como alguns sinais se distinguem principalmente pela configuração das mãos enquanto outros dependem de movimentos mais amplos dos braços ou de sinais faciais, o TinyMSLR não fixa uma única receita para combinar suas duas visões. Em vez disso, usa uma pequena “porta de fusão” que aprende, para cada clipe de entrada, quanto confiar no ramo focado em detalhes versus no ramo focado em contexto. A porta analisa ambos os resumos de características e produz dois pesos que sempre somam um; a representação final é uma mistura ponderada dos dois. Durante o treinamento, cada ramo também recebe seu próprio pequeno classificador para aprender a ser útil por conta própria, e um par de redes maiores “professoras” (uma CNN, uma Transformer) guia suavemente o modelo compacto mostrando não apenas o rótulo correto, mas também quais rótulos alternativos parecem semelhantes. Essa técnica, chamada destilação de conhecimento, ajuda o sistema compacto a aproximar a precisão de modelos mais pesados enquanto mantém seu tamanho e velocidade adequados para dispositivos de borda.
Ver por que o sistema toma cada decisão
Além da precisão bruta, os autores enfatizam que usuários e desenvolvedores devem poder inspecionar no que o modelo está prestando atenção. Eles adotam o SHAP, uma família de ferramentas que atribui um valor de importância a cada parte da entrada. Na prática, calculam essas explicações em características intermediárias e as mapeiam de volta para os quadros como mapas de calor e gráficos temporais. Isso revela, por exemplo, quais quadros e regiões impulsionam a decisão entre sinais visualmente semelhantes como Chuva e Neve ou Frio e Ruim. Agregar muitas explicações mostra padrões mais amplos: pistas não manuais como expressão facial e movimento da cabeça, assim como orientação do pulso e configuração da mão, emergem como especialmente influentes. Esses insights ajudam a verificar que o sistema se baseia em aspectos significativos da sinalização em vez de artefatos de fundo.

Velocidade, frugalidade e espaço para crescer
No benchmark bilíngue de 20 sinais, o TinyMSLR atinge cerca de 99% de acurácia em treinamento e validação e uma pontuação F1 próxima de 99%, usando menos de 2,7 milhões de parâmetros e cerca de 1,9 bilhão de operações por clipe. Em uma GPU moderna, processa um sinal em aproximadamente 13,5 milissegundos e consome menos de 30 milijoules de energia; o modelo armazenado tem apenas cerca de 7,2 megabytes. Esses números sugerem que o reconhecimento de sinais em tempo real, no dispositivo, é viável em placas de baixo custo e sistemas embarcados. Os autores observam com cuidado que seu trabalho cobre apenas sinais curtos e isolados e duas línguas, e trata expressões faciais implicitamente em vez de como um sinal separado. Estender a abordagem para vocabulários mais ricos, sentenças contínuas, mais línguas e modelagem explícita de movimentos faciais e de cabeça fica para trabalhos futuros. Ainda assim, o TinyMSLR oferece uma prova de conceito atraente: ferramentas precisas, eficientes e interpretáveis para entender línguas de sinais não precisam ficar restritas à nuvem — elas podem rodar diretamente em dispositivos do dia a dia.
Citação: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Palavras-chave: reconhecimento de língua de sinais, tiny machine learning, edge AI, IA explicável, modelos multilíngues