Clear Sky Science · pt
SAT: transformador de alinhamento por deslocamento para redução de ruído em vídeo sem estimativa de fluxo
Vídeos mais nítidos a partir de cenas ruidosas
Quem já tentou filmar dentro de casa à noite ou com um celular em pouca luz conhece o resultado: vídeo granuloso e tremeluzente onde os detalhes parecem rastejar e as cores ficam distorcidas. Este artigo apresenta uma nova forma de limpar esses vídeos, transformando-os em sequências mais nítidas e estáveis sem depender do software pesado de acompanhamento de movimento que normalmente torna isso possível. O método, chamado Shift Alignment Transformer, é projetado para preservar detalhes finos ao mesmo tempo em que roda de maneira eficiente o bastante para ser prático.
Por que limpar vídeo é tão difícil
Remover ruído de uma única fotografia já é um desafio; fazer o mesmo para vídeo é ainda mais complicado. Por um lado, cada quadro é corrompido por manchas aleatórias e desvios de cor. Por outro, os quadros estão conectados no tempo: objetos se movem, a câmera trepida e detalhes aparecem e desaparecem. Métodos tradicionais de redução de ruído em vídeo dependem de estimar o movimento entre quadros, frequentemente por meio de uma ferramenta chamada fluxo óptico, que tenta rastrear para onde cada pixel se desloca de um quadro para o outro. Apesar de potente, essa estimativa de movimento pode falhar quando o vídeo está extremamente ruidoso ou o movimento é rápido e complexo, além de acrescentar uma grande carga computacional que pode deixar os sistemas lentos.
Uma nova forma de alinhar sem rastrear
Em vez de tentar seguir explicitamente cada pixel, o Shift Alignment Transformer (SAT) toma outro caminho: permite que a rede descubra implicitamente como os quadros se relacionam por meio de deslocamentos e comparações cuidadosas de características. O modelo é construído em torno de uma arquitetura moderna conhecida como Transformer, que é excelente em encontrar conexões de longo alcance nos dados. Dentro desse quadro, os autores introduzem um Módulo de Deslocamento Espaço-Temporal que embaralha suavemente informação através do tempo e do espaço. No tempo, o modelo desloca ciclicamente as características dos quadros para que, camada por camada, cada quadro possa “enxergar” mais para o passado e o futuro. No espaço, divide características em muitos grupos pequenos e empurra cada grupo em direções diferentes. Essa combinação imita efetivamente como objetos podem se mover pelo vídeo, permitindo que a rede alinhe informação de quadros distintos sem nunca calcular um campo de movimento explícito.
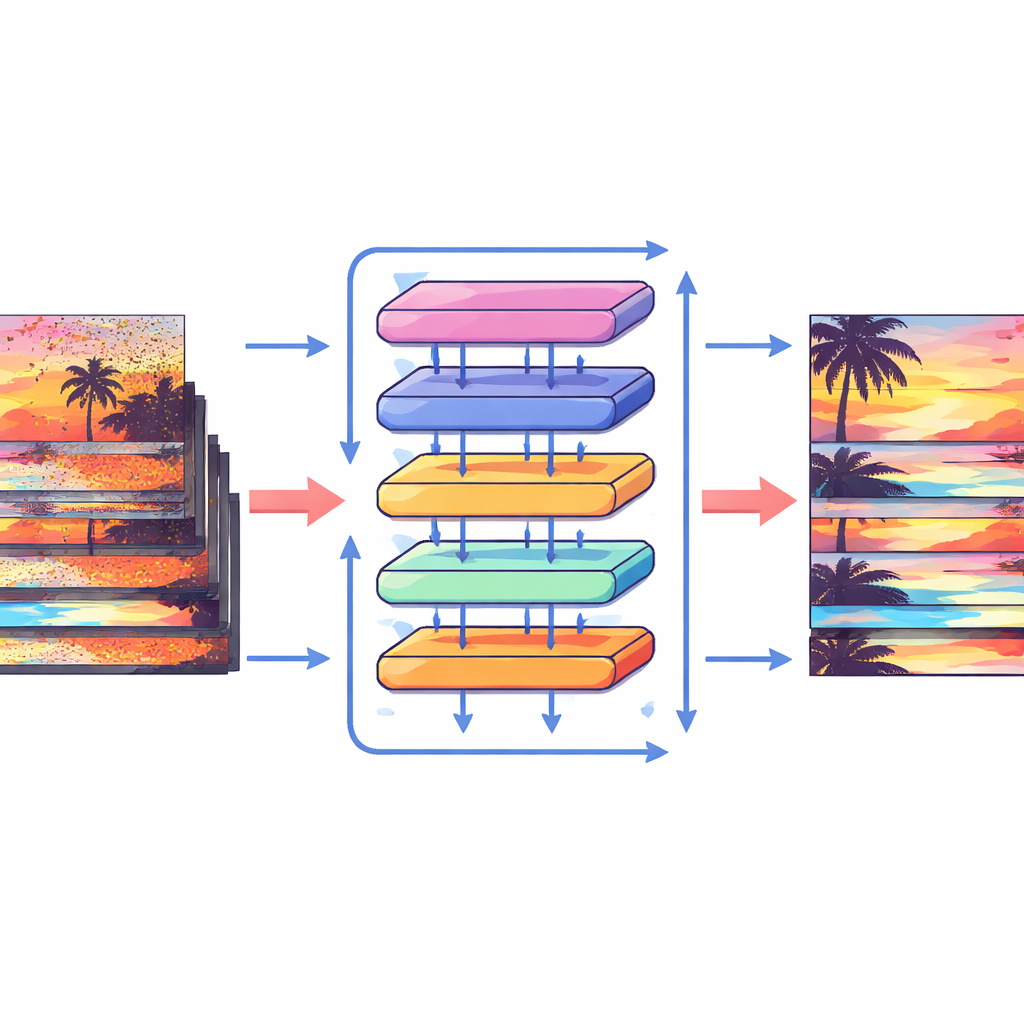
Como os novos blocos funcionam
Para tirar o máximo proveito desses deslocamentos, os autores projetam um bloco de atenção especial que mistura informação dentro e entre quadros. Primeiro, as características deslocadas de quadros vizinhos são reunidas e comparadas por meio de uma operação de atenção cruzada: o modelo aprende quais regiões em outros quadros melhor suportam o quadro atual em cada localização. Ao mesmo tempo, uma operação de atenção separada foca nas relações dentro de cada quadro individual, reforçando estrutura e textura locais. Esses dois fluxos são então unidos e passados por camadas de processamento simples em uma rede em forma de U multiescala, que vai de resolução grosseira para fina e volta. Esse desenho permite ao sistema lidar tanto com grandes movimentos de câmera quanto com detalhes minúsculos, como bordas finas ou pequenos padrões, reconstruindo gradualmente uma versão limpa de cada quadro.
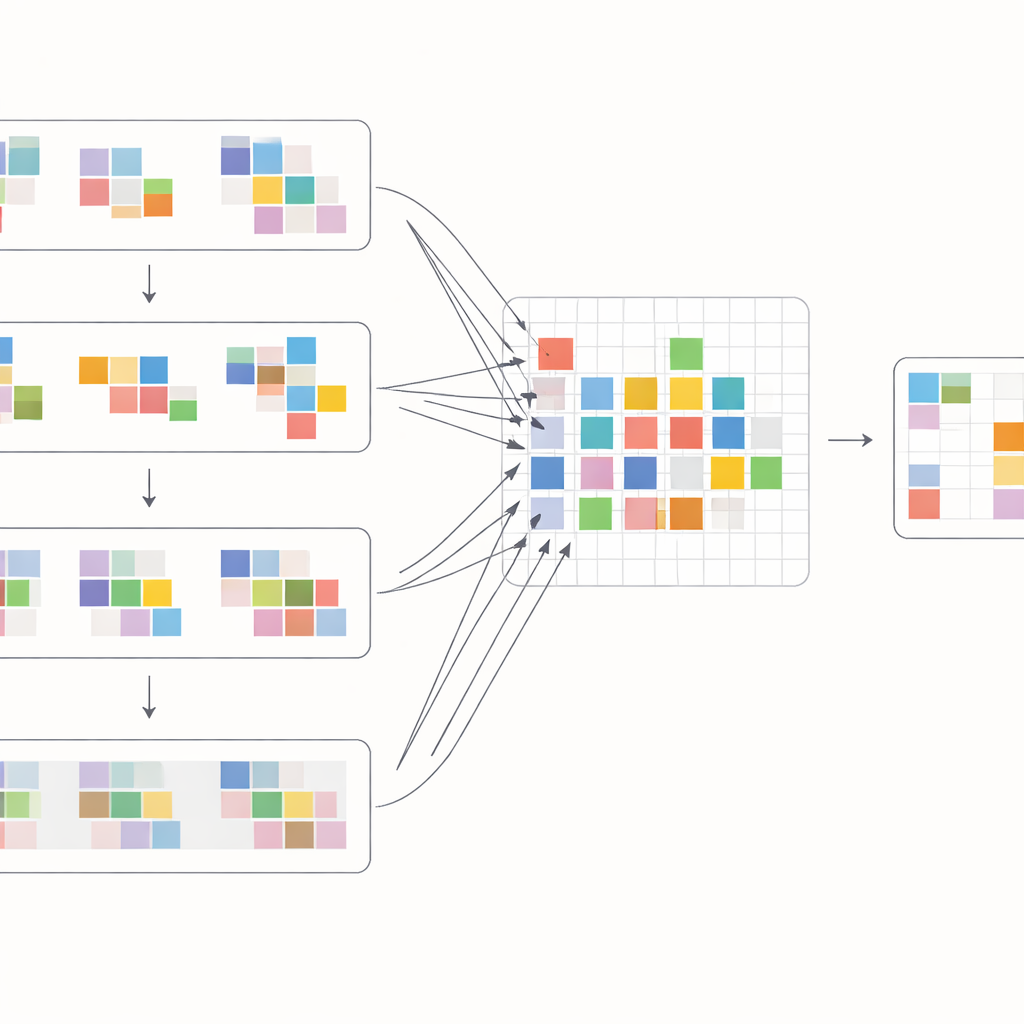
Quão bem isso funciona na prática
Os pesquisadores testam sua abordagem em dois benchmarks exigentes. O primeiro envolve vídeos limpos corrompidos artificialmente com diferentes níveis de ruído aleatório, permitindo medir com precisão o quão próximos os quadros restaurados estão dos originais. Nesse cenário, o novo método consistentemente iguala ou supera a qualidade de redes convolucionais e recorrentes anteriores, e chega perto dos melhores modelos baseados em Transformer existentes enquanto usa menos computação. O segundo benchmark emprega filmagens reais capturadas por sensores de imagem em baixa luminosidade, onde o ruído é desigual, colorido e muito menos previsível. Neste teste mais realista, o Shift Alignment Transformer supera de forma decisiva métodos anteriores de última geração, produzindo vídeos que parecem mais limpos, nítidos e estáveis ao longo do tempo, com menos desvios de cor e menos artefatos remanescentes.
O que isso significa para ferramentas de vídeo futuras
Em termos simples, os autores mostram que é possível reduzir ruído em vídeos de forma eficaz sem rastrear explicitamente o movimento, combinando deslocamentos inteligentes no tempo e no espaço com correspondência de características baseada em atenção. O Shift Alignment Transformer oferece um forte equilíbrio entre precisão e eficiência, especialmente para filmagens do mundo real em baixa luminosidade, onde a estimativa de movimento tradicional é frágil. À medida que modelos baseados em atenção se tornam mais eficientes, métodos como este podem chegar a câmeras do dia a dia e serviços de streaming, ajudando a transformar clipes ruidosos e difíceis de assistir em vídeos suaves e nítidos com o mínimo de trabalho para o usuário.
Citação: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Palavras-chave: redução de ruído em vídeo, transformador, ruído de imagem, vídeo com pouca luz, visão computacional