Clear Sky Science · pt
Ataque adversarial baseado em decisão com baixo orçamento de consultas e eficiência de consultas
Por que pequenos defeitos em imagens conseguem enganar máquinas inteligentes
A inteligência artificial moderna consegue identificar rostos, animais e objetos cotidianos com precisão impressionante. Ainda assim, esses mesmos sistemas podem ser enganados por alterações numa imagem tão pequenas que pessoas mal as percebem. Este artigo explora uma nova forma de criar essas imagens “enganadoras” pedindo ao sistema de IA o menor número possível de respostas, revelando tanto a fragilidade dos modelos atuais quanto como atacantes poderiam explorá‑los no mundo real.
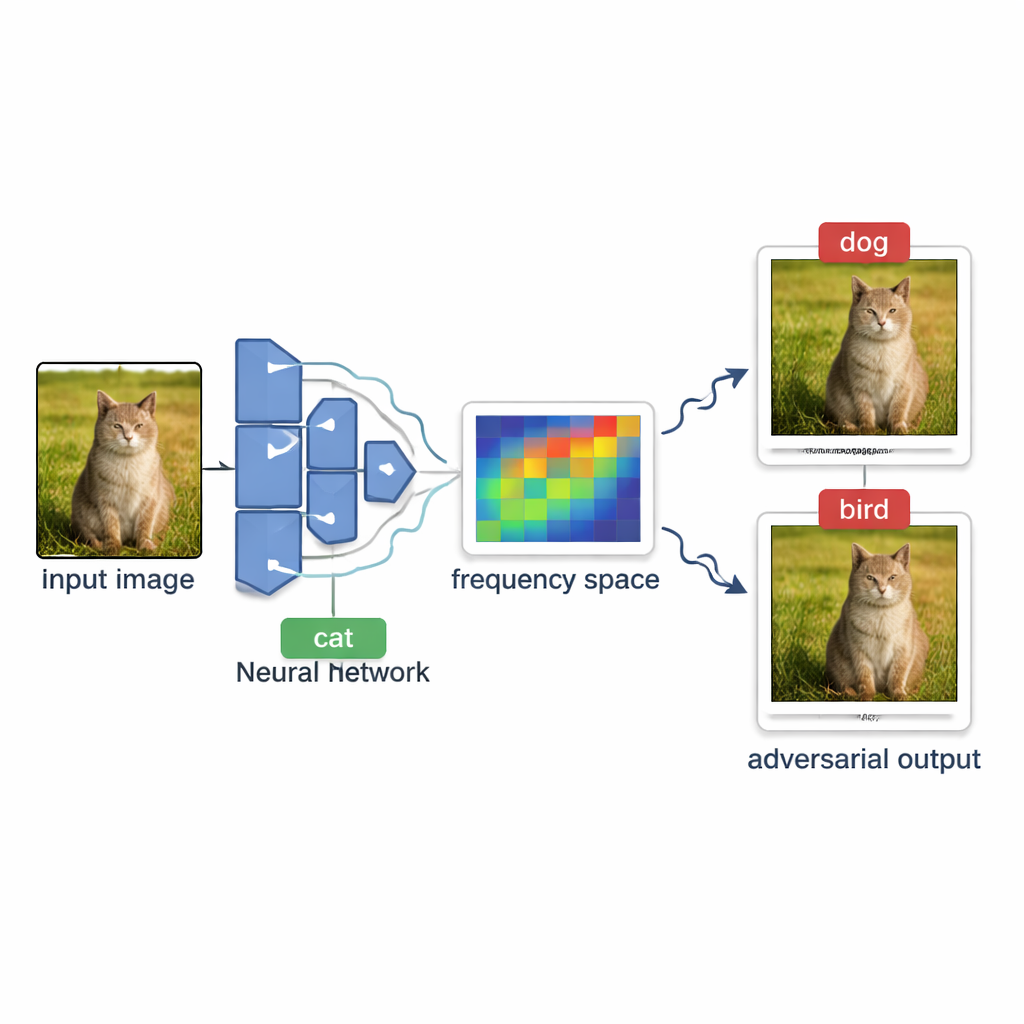
Como atacantes sondam sistemas de IA do lado de fora
Em muitos serviços reais — como marcação automática de fotos online ou filtros de conteúdo — o modelo se comporta como uma caixa‑preta. Pessoas externas podem enviar uma imagem e ver apenas o rótulo final, como “cachorro” ou “placa de pare”, mas nunca as pontuações internas de confiança ou a arquitetura do modelo. Criar uma imagem enganosa nessas condições é chamado de ataque caixa‑preta baseado em decisão. O desafio é empurrar suavemente uma imagem normal até que o modelo a rotule errado, sem poder ver quão “perto” ela está de mudar de opinião e sem enviar tantas imagens de teste a ponto de o sistema notar ou de as consultas se tornarem muito caras.
Uma nova forma de buscar com pouquíssimas perguntas
Os autores apresentam OPOQA (One Plane One Query Attack), um método projetado para economizar consultas enquanto ainda produz imagens adversariais de alta qualidade. Em vez de sondar repetidamente ao longo de uma única direção suposta, o OPOQA opera em rodadas. Em cada rodada, parte de uma imagem já enganadora e da imagem limpa original, então propõe vários novos candidatos situados em direções escolhidas com cuidado. Crucialmente, cada direção é sondada no máximo uma vez, o que libera o orçamento limitado de consultas para explorar muitas mais possibilidades em vez de refinar excessivamente um único palpite.
Surfando as ondas suaves numa imagem
Para escolher direções promissoras, o OPOQA se apoia na ideia de que as mudanças mais eficazes e difíceis de ver costumam ser suaves e amplas, em vez de ruído agudo ao nível de pixel. O método usa uma ferramenta matemática chamada transformada discreta cosseno para mover a imagem para uma visão em “frequência”, onde variações lentas e suaves ficam concentradas numa região compacta. Ele amostra aleatoriamente alguns desses componentes de baixa frequência, converte‑os de volta em alterações de pixels e os usa como direções básicas de exploração. Cada direção amostrada ajuda a definir uma superfície plana bidimensional que conecta a imagem original, a imagem adversarial atual e um novo candidato. Em cada uma dessas superfícies, o OPOQA escolhe um único ponto para testar, equilibrando dois objetivos: aproximar‑se da imagem original enquanto ainda tem alta probabilidade de levar o modelo a uma decisão errada.

Escolhendo o melhor candidato e adaptando-se em tempo real
Depois de gerar um pequeno conjunto de imagens candidatas, o OPOQA mede o quão distante cada uma está da imagem original e as ordena do menor para o maior desvio. Em seguida, consulta o modelo nessa ordem. No momento em que encontra um candidato que o modelo classifica incorretamente, ele para e trata essa imagem como o novo ponto de partida para a próxima rodada. Se nenhum dos candidatos conseguir enganar o modelo, o OPOQA mantém a melhor imagem adversarial anterior, mas ajusta um parâmetro interno que controla quão conservadoras ou agressivas serão as próximas etapas. Essa estratégia “gananciosa” — aceitar sempre a melhor imagem mal classificada disponível e ajustar dinamicamente o tamanho dos passos — permite ao ataque concentrar‑se em perturbações sutis e eficazes sem desperdiçar consultas em direções pouco promissoras.
O que os experimentos revelam sobre os pontos fracos da IA
Os pesquisadores testaram o OPOQA em 200 imagens do grande benchmark ImageNet e em seis modelos de rede neural amplamente usados, incluindo Inception‑v3, ResNet, VGG, DenseNet e transformadores de visão. Sob um limite rígido de 1.000 consultas ao modelo por imagem, o OPOQA igualou ou superou vários métodos de ataque líderes. Por exemplo, no Inception‑v3 ele enganou o modelo com sucesso em 94% das imagens mantendo alterações tão pequenas que eram quase invisíveis ao olho humano, melhorando em vários pontos percentuais sobre o método anterior de referência. Entre os modelos, o OPOQA tendia a alcançar altas taxas de sucesso mais cedo — usando menos consultas — embora alguns métodos concorrentes tenham alcançado ou superado seu desempenho quando receberam orçamentos de consulta muito grandes e tempo para refinamento.
O que isso significa para a segurança cotidiana da IA
O estudo mostra que os sistemas de visão atuais podem ser enganados mesmo quando atacantes veem apenas as decisões finais e têm oportunidades limitadas de sondar o modelo. Ao explorar de forma inteligente mudanças suaves e de baixa frequência e racionar cuidadosamente cada consulta, o OPOQA pode criar imagens que parecem idênticas para pessoas, mas confundem fortemente as máquinas. Para leigos, a lição é que a “visão” da IA ainda é bastante frágil: ela pode ser desviada por meios sutis que são difíceis de perceber. Reconhecer e estudar tais ataques eficientes é um passo-chave para fortalecer sistemas do mundo real — como câmeras de segurança, ferramentas de imagem médica e veículos autônomos — contra manipulações que, de outra forma, poderiam passar despercebidas.
Citação: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
Palavras-chave: exemplos adversariais, ataques caixa-preta, segurança em deep learning, classificação de imagens, ataque eficiente em consultas