Clear Sky Science · pt
MDI-YOLO: um modelo leve de fusão multidimensional de recursos baseado em transformer-CNN para detecção de pequenos objetos
Olhos mais nítidos no céu
De monitoramento de tráfego a resposta a desastres, drones e satélites observam cada vez mais o nosso mundo. Ainda assim, as coisas que mais nos interessam nessas imagens — carros, pessoas, barcos e aeronaves minúsculos — frequentemente aparecem como apenas alguns pixels. O artigo sobre o MDI‑YOLO enfrenta uma pergunta simples, porém crucial: como computadores podem detectar esses alvos minúsculos de forma confiável em tempo real, mesmo em dispositivos de baixa potência embarcados nos próprios drones?
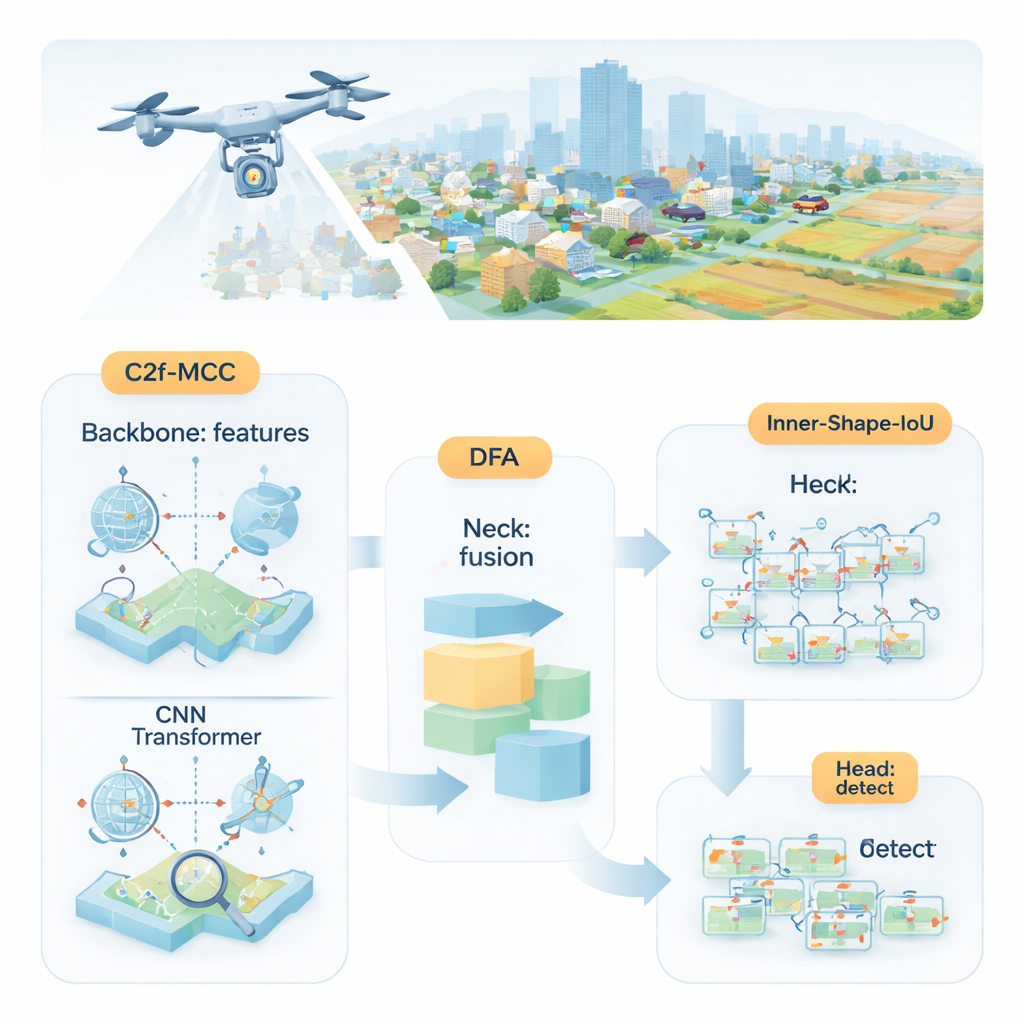
Por que é difícil detectar pequenos objetos
Em vistas aéreas e por satélite, os objetos de interesse geralmente são muito pequenos, frequentemente aglomerados e parcialmente escondidos por prédios, árvores ou sombras. Sistemas de detecção padrão enfrentam um dilema: modelos leves rodam rápido em dispositivos de borda, como os computadores a bordo de drones, mas perdem muitos alvos pequenos; modelos maiores e mais precisos são lentos e exigem muitos recursos, tornando‑se impraticáveis em campo. Pequenos objetos também tendem a se fundir com fundos complexos — pense em carros cinza em estradas cinzentas — de modo que suas características distintivas podem desaparecer conforme as imagens são comprimidas e processadas por redes profundas.
Uma nova combinação de visão global e local
Os pesquisadores propõem o MDI‑YOLO, uma versão redesenhada do popular detector YOLOv8 que mantém o modelo compacto ao mesmo tempo em que aprimora sua capacidade de encontrar alvos minúsculos. No núcleo está um novo bloco construtor chamado C2f‑MCC, que divide a informação visual que flui pela rede em dois caminhos. Um caminho usa processamento no estilo Transformer, eficiente para capturar relações de longo alcance por toda a imagem — por exemplo, como um aglomerado de pixels se encaixa em uma estrada ou pista maior. O outro caminho mantém os filtros convolucionais clássicos, que se destacam em identificar detalhes locais como bordas e texturas. Ao agrupar canais e enviar apenas parte dos dados pelo caminho mais pesado do Transformer, o modelo ganha consciência global sem crescer demais em tamanho ou ficar mais lento.
Ajuda para a rede focar no que importa
Mesmo com blocos construtores melhores, a rede ainda precisa decidir onde prestar atenção. Para guiar isso, os autores introduzem um mecanismo chamado Attention de Fusão Direcional (Directional Fusion Attention, DFA). Esse módulo observa padrões ao longo da largura e da altura da imagem, além de um resumo geral da cena, e aprende a ponderar diferentes regiões e canais de recurso. Na prática, o DFA incentiva o modelo a concentrar‑se em áreas prováveis de conter objetos — como manchas em forma de veículo sobre estradas — e a diminuir a importância de texturas de fundo repetitivas ou confusas. Essa combinação de foco espacial e por canal facilita separar alvos minúsculos de cenários carregados ou de regiões de fundo com aparência semelhante.
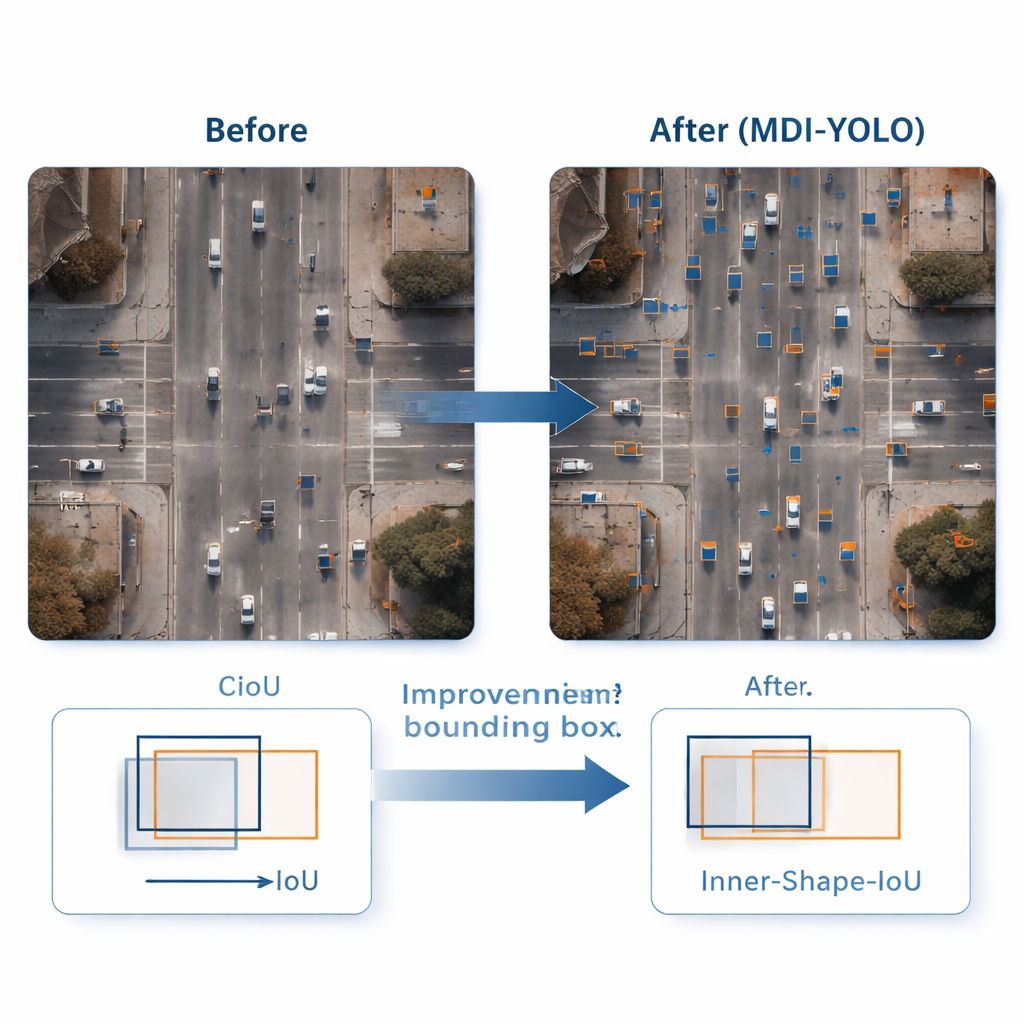
Desenhando caixas mais precisas ao redor de alvos minúsculos
Detectar um objeto é apenas metade do trabalho; o detector também precisa contorná‑lo com precisão. Métodos de treinamento padrão comparam retângulos previstos com os verdadeiros usando uma pontuação de “sobreposição”, mas isso pode ser insensível quando objetos são pequenos ou de forma estranha. Os autores propõem uma nova função de perda, Inner‑Shape‑IoU, que avalia caixas não só pelo quanto se sobrepõem, mas também por quão bem sua forma, tamanho e região central se alinham com o objeto real. Ao combinar duas medidas complementares, ela penaliza caixas que batem apenas nas bordas enquanto perdem o núcleo do alvo, levando a contornos mais precisos — especialmente para objetos pequenos, aglomerados ou alongados.
Ganho comprovado sem peso extra
Para testar o MDI‑YOLO, a equipe realizou experimentos em dois benchmarks públicos desafiadores: VisDrone2019, com filmagens de drones em cidades e tráfego, e DOTAv1.0, uma grande coleção de cenas aéreas com muitos objetos pequenos e densamente agrupados. Sem depender de modelos pré‑treinados, o MDI‑YOLO melhorou as métricas de precisão padrão em vários pontos percentuais sobre o YOLOv8 base, mantendo o número de parâmetros quase inalterado e preservando tempos de inferência rápidos. Comparado a uma gama de detectores populares — de variantes leves do YOLO a sistemas maiores baseados em Transformer — ele ofereceu uma combinação rara de alta precisão, baixo custo computacional e robustez em diferentes cenários.
O que isso significa para o uso no mundo real
Para não especialistas, a conclusão é que o MDI‑YOLO oferece aos drones e sistemas de sensoriamento remoto “olhos” mais nítidos e confiáveis sem exigir computadores grandes e energívoros. Ao misturar de forma inteligente contexto global, detalhe local, atenção direcionada e uma forma mais criteriosa de treinar caixas delimitadoras, o método facilita detectar pequenos objetos importantes para segurança, monitoramento e mapeamento. Esse tipo de visão eficiente e de alta precisão é um passo-chave rumo a plataformas aéreas mais inteligentes que podem operar de forma autônoma, responder rapidamente e ser amplamente implantadas no mundo real.
Citação: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Palavras-chave: imagens por drone, detecção de pequenos objetos, sensoriamento remoto, YOLO, visão computacional