Clear Sky Science · pt
Método robusto baseado em imputação para previsão da cor dos olhos, cabelo e pele a partir de DNA antigo de baixa cobertura
Vendo os Rostos por Trás do DNA Antigo
Quando arqueólogos desenterram ossos antigos, raramente sabem como as pessoas eram em vida — qual era a cor dos olhos, quão escura era a pele ou se o cabelo era preto, loiro ou ruivo. Este estudo apresenta uma nova forma de ler esses traços visíveis a partir de DNA extremamente degradado, permitindo aos cientistas esboçar uma imagem mais humana de indivíduos do passado distante e aplicar as mesmas ideias a amostras forenses degradadas hoje.
Por Que o DNA Antigo É Tão Difícil de Ler
O DNA de restos sepultados por muito tempo é um destroço biológico. O tempo o fragmenta em pedaços minúsculos e introduz danos químicos que trocam uma letra genética por outra. A maioria dos genomas antigos é sequenciada apenas em “baixa cobertura”, o que significa que muitas posições são lidas uma vez — ou nem são lidas. Ferramentas forenses existentes, como o HIrisPlex-S, que podem prever cor dos olhos, do cabelo e da pele a partir de 41 marcadores chave, foram desenvolvidas para DNA moderno e de alta qualidade e esperam informação confiável em ambas as cópias de cada marcador. Com material antigo, essas informações frequentemente faltam ou são incertas, então métodos tradicionais ou falham completamente ou fornecem previsões muito frágeis.
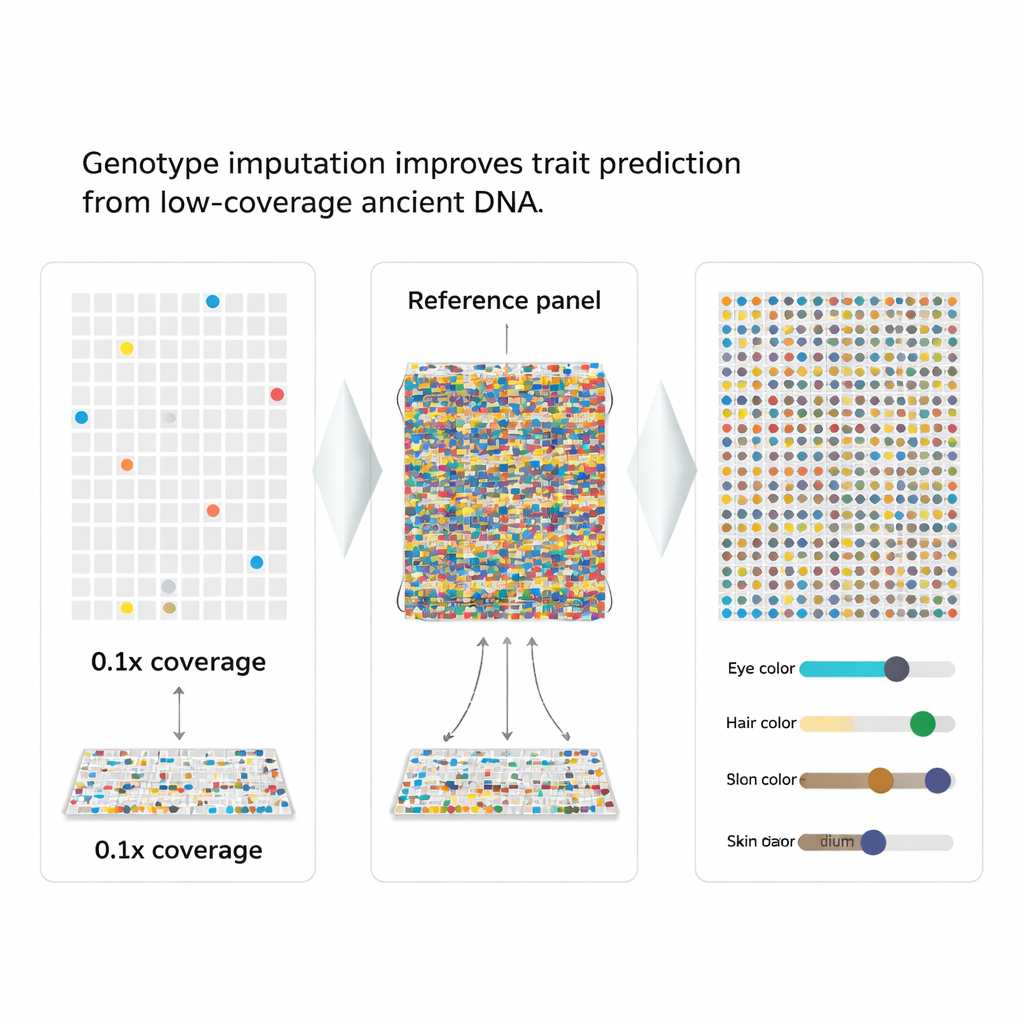
Preenchendo as Lacunas com Chute Inteligente
Os autores recorreram a uma estratégia chamada imputação de genótipos, que usa padrões em um grande painel de referência de genomas modernos para “preencher” as peças faltantes em um genoma degradado. Como marcadores genéticos próximos são herdados juntos em blocos, um padrão parcialmente observado pode indicar fortemente as letras faltantes mais prováveis. A equipe incorporou essa ideia em um novo fluxo de trabalho, o aHISplex, que parte de leituras de DNA alinhadas, executa software de imputação de ponta, converte os resultados para o formato exato exigido pelo HIrisPlex-S e então transforma automaticamente as probabilidades previstas em categorias claras de traços para cor dos olhos, cabelo e pele.
Testando a Precisão em Pessoas Modernas e Antigas
Para avaliar o desempenho do método, os pesquisadores usaram 93 genomas modernos com traços conhecidos e os “subamostraram” artificialmente para simular cobertura muito baixa, tão pobre quanto um décimo de uma leitura completa. Em seguida imputaram os marcadores faltantes e compararam os resultados com os dados verdadeiros. Mesmo com apenas 0,5× de cobertura, a taxa de erro geral para os 41 marcadores permaneceu abaixo de cerca de 2%, e os erros mais graves — trocar um marcador completamente de um estado homozigoto para o oposto — foram extremamente raros. A maioria das previsões de cor dos olhos e do cabelo coincidiu com os traços conhecidos, e as previsões de cor da pele mudaram apenas ligeiramente entre categorias de tonalidade vizinhas.
Desafios com Traços Raros e Diversidade Antiga
Nem todos os traços são igualmente fáceis de recuperar. O cabelo ruivo, impulsionado em grande parte por variantes raras no gene MC1R, mostrou-se mais difícil: o método quase nunca inventou ruivo onde ele não existia, mas às vezes deixou de identificar verdadeiros indivíduos ruivos, classificando-os como loiros ou loiro escuro. A equipe também aplicou seu fluxo de trabalho a 31 indivíduos genuinamente antigos com genomas de alta qualidade e, em seguida, simulou baixa cobertura nesses genomas para reimputá-los. Novamente, a precisão geral foi alta, com cerca de 95% dos marcadores chave corretamente imputados a 0,5× de cobertura. No entanto, um pequeno conjunto de combinações marcador–amostra, especialmente em indivíduos cujos antecedentes genéticos são mal representados nos painéis de referência modernos, mostrou erro sistematicamente maior. Esse “viés de referência” poderia, por exemplo, transformar um genótipo de olhos azuis em uma previsão de olhos castanhos em uma fração das execuções.
Trazendo Pessoas Antigas a Foco Mais Nítido
Apesar dessas ressalvas, o estudo mostra que hoje é viável prever cor dos olhos, cabelo e pele para muitos indivíduos antigos mesmo quando seu DNA é extremamente escasso, com apenas 0,1–0,5× de cobertura. O novo pipeline aHISplex automatiza os passos complexos entre arquivos brutos de sequenciamento e chamadas de traços amigáveis ao usuário, tornando-o acessível a laboratórios de arqueogenética e potencialmente a equipes forenses que lidam com amostras degradadas. À medida que os painéis de referência crescem para incluir genomas mais diversos e antigos, e conforme os cientistas descobrirem marcadores adicionais ligados a traços, essa abordagem deve se tornar ainda mais precisa — ajudando-nos a passar de ossos anônimos e sequências de DNA para retratos vívidos e eticamente considerados de pessoas que viveram há muito tempo.
Citação: Maróti, Z., Nyerki, E., Török, T. et al. Robust imputation-based method for eye, hair, and skin colour prediction from low-coverage ancient DNA. Sci Rep 16, 7371 (2026). https://doi.org/10.1038/s41598-026-38372-3
Palavras-chave: DNA antigo, fenotipagem forense, olhos cabelo pele, imputação de genótipos, arqueogenética