Clear Sky Science · pt
Um método de fusão de melhoria de imagem visível e infravermelha de ponta a ponta e em múltiplas escalas
Visão noturna mais nítida para pessoas e máquinas
Quem já tentou tirar uma foto à noite sabe o quão rápido a escuridão destrói os detalhes: cenas parecem granuladas, borradas e cheias de cores estranhas. Ainda assim, muitas tecnologias críticas — de câmeras de rua e segurança residencial a carros autônomos e drones de resgate — precisam enxergar claramente exatamente nessas condições. Este artigo apresenta uma nova forma de combinar câmeras coloridas comuns com câmeras infravermelhas “de calor” para que computadores, e em última instância pessoas, obtenham vistas brilhantes e detalhadas do mundo mesmo na quase total escuridão.
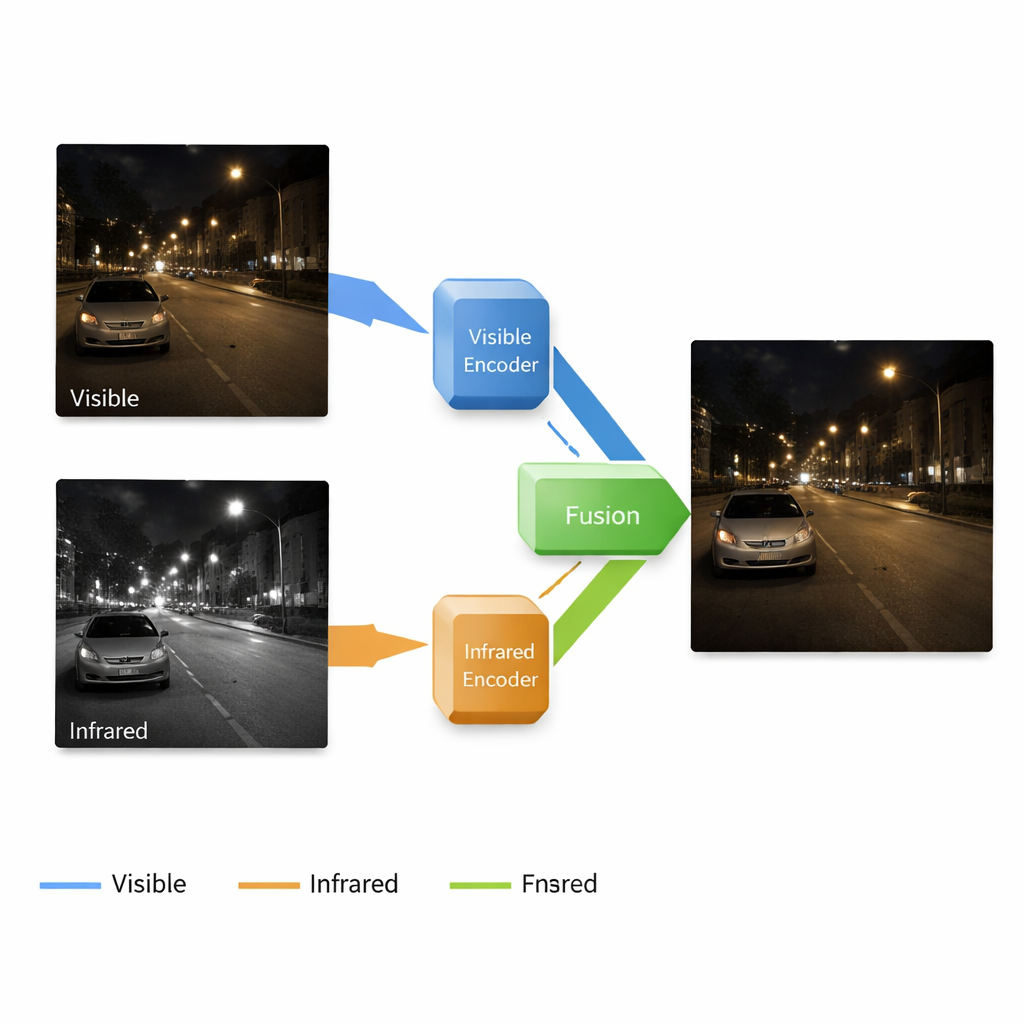
Por que dois tipos de câmeras são melhores que uma
Câmeras padrão capturam o mesmo tipo de luz que nossos olhos veem, o que torna suas imagens fáceis de interpretar para humanos, mas elas falham quando a luz é escassa: sombras engolem detalhes, aparece ruído e as cores mudam. Câmeras infravermelhas fazem o oposto: detectam padrões de calor, revelando pessoas, animais e veículos no escuro ou através de neblina leve, mas suas imagens carecem de texturas finas e aparência natural. Pesquisadores há muito tentam fundir essas duas visões em uma única imagem que pareça uma foto colorida clara e ainda revele objetos quentes escondidos. Métodos existentes, no entanto, muitas vezes tratam cada etapa — clareamento de imagens escuras, remoção de ruído e incorporação da informação infravermelha — como tarefas separadas. Essa abordagem fragmentada pode causar desalinhamento de características e resultados de fusão decepcionantes.
Um único fluxo que tanto clareia quanto funde
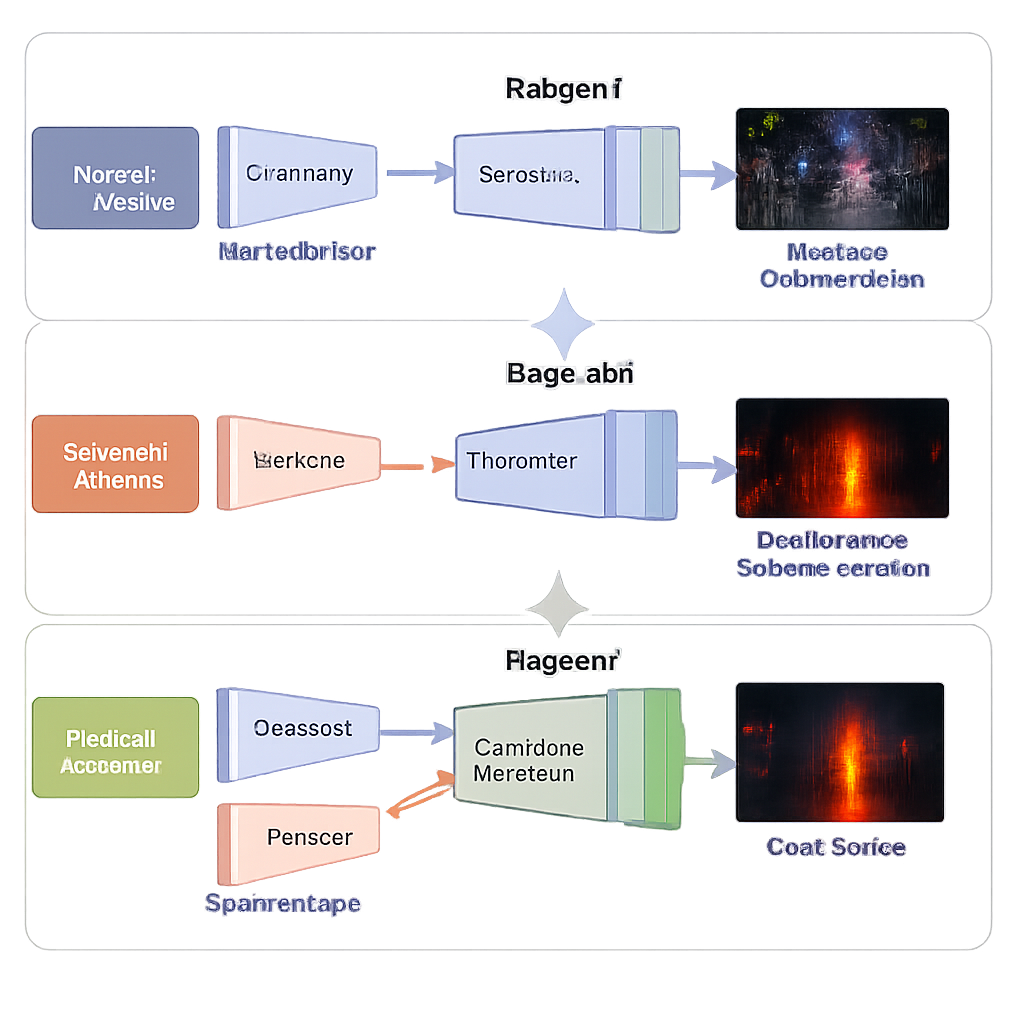
Os autores propõem um sistema ponta a ponta que aprimora e funde imagens em um pipeline contínuo. Ele é construído em torno de uma rede neural com quatro partes principais: um ramo aprende a limpar e clarear imagens coloridas em baixa luminosidade, outro aprende a representar a cena a partir da câmera infravermelha, um bloco de fusão combina o que cada ramo aprendeu, e um decodificador reconstrói a imagem final a partir desses sinais mistos. Importante: o sistema opera em múltiplas escalas, desde formas grosseiras até texturas finas. Camadas rasas preservam bordas e detalhes de superfície como tijolos ou marcações viárias, enquanto camadas mais profundas capturam estruturas mais amplas — edifícios, carros ou árvores — e a localização de alvos quentes na imagem infravermelha.
Três fases de aprendizado em vez de um grande salto
Em vez de treinar todo o sistema de uma só vez, a equipe usa uma estratégia de aprendizado em três etapas projetada para estabilidade e precisão. Na primeira etapa, a rede vê apenas fotos visíveis escuras e aprende a clareá-las sem imagens de referência “perfeitas” fornecidas por humanos. Termos de perda cuidadosamente escolhidos orientam a saída para ter brilho natural, cores estáveis, regiões suaves sem ruído em manchas e textura preservada. Na segunda etapa, o mesmo decodificador é reutilizado enquanto um novo ramo infravermelho aprende a reconstruir fielmente imagens infravermelhas, ensinando à rede como os padrões de calor devem parecer. Na terceira etapa, todas essas peças aprendidas são congeladas, e apenas o bloco de fusão é treinado para misturar as duas representações em uma única imagem de alta qualidade que seja ao mesmo tempo brilhante e rica em informação.
Colocando o método à prova
Os pesquisadores avaliaram sua abordagem em conjuntos de dados públicos contendo pares de imagens visíveis e infravermelhas obtidas sob iluminação difícil, como ruas noturnas. Eles compararam com várias técnicas de fusão de ponta, incluindo aquelas baseadas em transformadas clássicas de imagem, redes convolucionais padrão e modelos generativos mais complexos. Seu método geralmente entregou detalhes mais nítidos, brilho mais uniforme e alvos térmicos mais claros, enquanto também obteve pontuações mais altas em medidas quantitativas de conteúdo informacional, nitidez de borda, similaridade estrutural e contraste. Experimentos adicionais, nos quais removeram seletivamente componentes-chave do sistema, mostraram que cada parte — o bloco de fusão multiescala, o treinamento em etapas e a ponderação adaptativa de recursos visíveis versus infravermelhos — contribui de forma mensurável para a qualidade final.
O que isso significa para sistemas de visão no mundo real
Para não especialistas, a conclusão é simples: este trabalho mostra que uma única rede cuidadosamente treinada pode tanto clarear cenas escuras quanto mesclar de forma inteligente visões de calor e cor em uma imagem coerente. As imagens fundidas preservam texturas finas enquanto ainda destacam objetos quentes, tornando-as muito mais úteis para tarefas como vigilância noturna, assistência à condução e realidade aumentada ou virtual em ambientes de baixa iluminação. Embora os autores ressaltem algumas questões remanescentes — como contraste reduzido em regiões muito brilhantes e a necessidade de modelos mais rápidos e leves — sua abordagem representa um passo significativo rumo a sistemas de câmera que enxergam de forma confiável no escuro, de modo que pareça natural e interpretável para usuários humanos.
Citação: Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
Palavras-chave: melhoria de imagem em baixa luminosidade, fusão de imagens infravermelhas, visão noturna, imagem multisensorial, visão por aprendizado profundo