Clear Sky Science · pt
Podar floresta de árvores e reamostragem para problema de classes desequilibradas
Por que os casos raros importam em previsões inteligentes
Muitas decisões movidas por inteligência artificial dependem de detectar o evento raro: uma cobrança de cartão de crédito fraudulenta, um sinal precoce de doença ou uma falha perigosa em uma máquina. Nesses cenários, os casos importantes são muito menos frequentes que os comuns, e a maioria dos algoritmos de aprendizado tende a ignorá-los. Este artigo apresenta uma maneira de tornar um método popular, as Random Forests, muito mais atento a esses casos raros porém cruciais — ao mesmo tempo deixando o modelo mais enxuto e rápido.
O problema dos exemplos desiguais
O aprendizado de máquina padrão funciona melhor quando os dados estão bem equilibrados — quando há números aproximadamente similares de exemplos para cada resultado. Na vida real, entretanto, eventos raros dominam muitas tarefas. Por exemplo, apenas uma pequena fração de exames médicos mostra um tumor, e apenas uma parcela ínfima das transações é fraudulenta. Esse desequilíbrio facilita que um algoritmo aparente bom desempenho simplesmente prevendo majoritariamente o resultado comum, mesmo que erre repetidamente o caso raro. À medida que a diferença entre casos comuns e raros aumenta, a fronteira de decisão do modelo tende a se deslocar para a maioria, e a classe rara fica mais difícil de reconhecer.
Equilibrando a balança com amostragem inteligente
Pesquisadores frequentemente tentam reequilibrar esses dados antes de treinar modelos. Uma opção é reduzir a classe majoritária (under-sampling), descartando alguns casos comuns para igualar o número de raros. Outra é copiar ou gerar exemplos raros extras (over-sampling), aumentando sua presença sem perder dados originais. Uma terceira abordagem híbrida mistura as duas ideias, cortando alguns exemplos da maioria enquanto reforça a minoria. Cada tática tem compensações: aparar corre o risco de descartar informação útil, enquanto duplicar muitos exemplos pode tornar o treinamento mais lento e causar overfitting. Os autores utilizam todas as três estratégias para criar conjuntos de treinamento mais equilibrados e adaptados aos dados em questão.
Treinando e podando uma floresta de árvores de decisão
O estudo foca nas Random Forests, um método em conjunto que constrói muitas árvores de decisão em fatias ligeiramente diferentes dos dados e depois combina seus votos. As Random Forests são conhecidas por lidar com dados complexos e por destacar quais variáveis são mais importantes. Ainda assim, quando treinadas em dados fortemente desequilibrados, mesmo florestas grandes podem continuar tendenciosas em favor da classe majoritária. No método proposto, os autores primeiro reequilibram os dados usando under-sampling, over-sampling ou o híbrido. Em seguida, crescem muitas árvores usando o procedimento usual de Random Forest, mas com uma alteração importante: em vez de manter todas as árvores, avaliam cada uma usando observações out-of-bag — pontos de dados que não foram usados para gerar aquela árvore específica — e descartam metade com as piores taxas de erro. Esse passo de poda resulta em uma floresta menor e mais seletiva, construída a partir das árvores mais confiáveis.
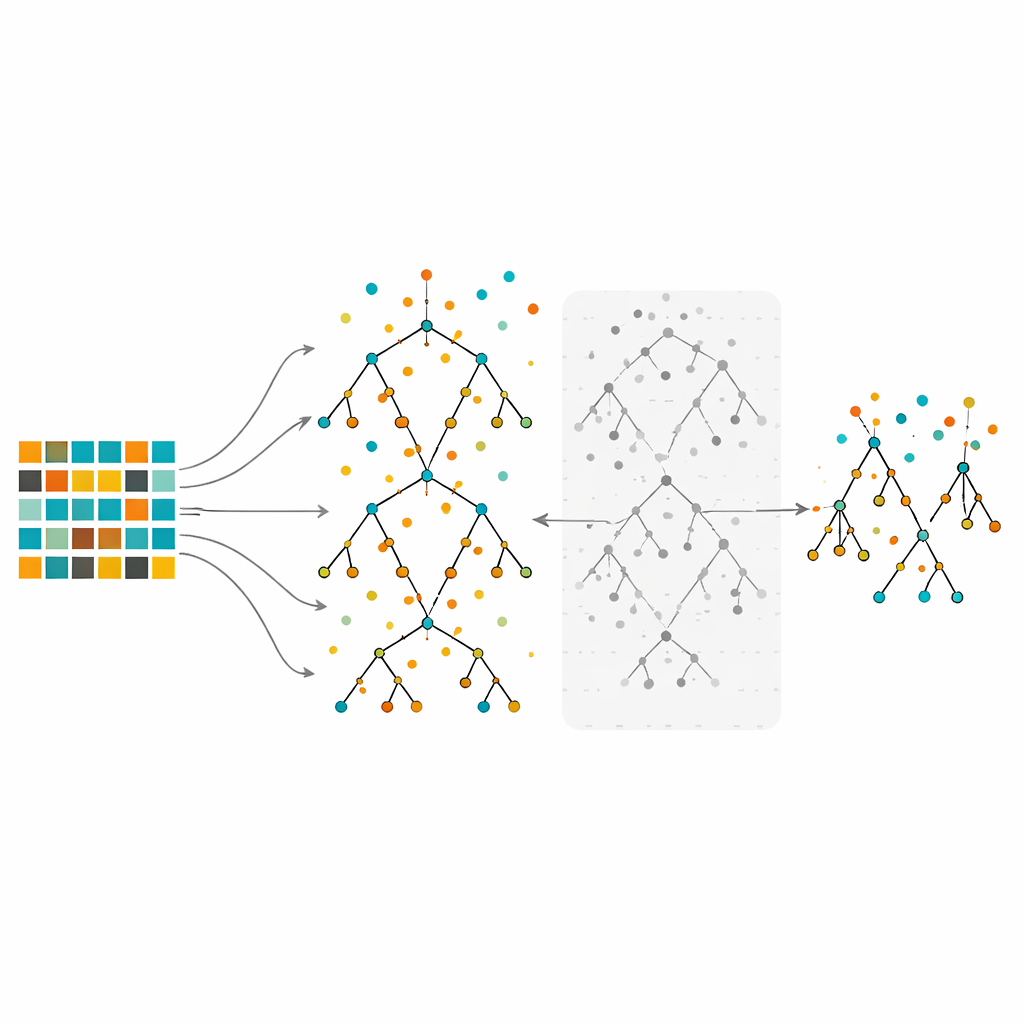
Testes em muitos conjuntos de dados do mundo real
Para avaliar o desempenho dessa floresta podada, os autores a testam em dez conjuntos de dados públicos que refletem uma ampla gama de aplicações, desde medições médicas e biológicas até filtragem de spam e classificação de sons. Cada conjunto tem duas classes, com uma claramente mais rara que a outra, e variam em tamanho, número de atributos e grau de desequilíbrio. O novo método é comparado com várias abordagens amplamente usadas: k-nearest neighbors, uma única árvore de decisão, uma Random Forest padrão, uma variante Balanced Random Forest e máquinas de vetor de suporte. Através das diferentes estratégias de amostragem, a floresta podada alcança de forma consistente erro de classificação menor que as alternativas na maioria dos conjuntos. A combinação de amostragem híbrida mais poda apresenta os melhores resultados globais, tanto em termos de acurácia quanto de desempenho estável ao longo das dez tarefas.
Modelos mais afiados que desperdiçam menos esforço
Além da acurácia, a abordagem também melhora a eficiência. Ao eliminar as árvores menos eficazes, o conjunto final fica menor e requer menos computação para treinar e para fazer previsões, sem sacrificar — e frequentemente melhorando — sua capacidade de detectar casos raros. Testes estatísticos confirmam que os ganhos sobre métodos concorrentes não se devem ao acaso. Para praticantes que enfrentam dados desequilibrados, este trabalho mostra que reequilibrar cuidadosamente o conjunto de treinamento e depois podar uma Random Forest com base no desempenho out-of-bag pode gerar modelos tanto mais precisos quanto mais eficientes. Em termos práticos, o método ajuda nossos algoritmos a prestar a atenção devida aos sinais raros, porém importantes, que se escondem em um mar de exemplos comuns.
Citação: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Palavras-chave: desequilíbrio de classes, random forest, reamostragem, aprendizado de máquina, métodos de conjunto