Clear Sky Science · pt
Detecção de intrusões baseada em anomalias em conjuntos de referência para segurança de rede: uma avaliação abrangente
Por que defesas mais inteligentes importam para todos online
Cada e-mail que você envia, vídeo que transmite ou conta que paga online percorre redes que são constantemente sondadas por atacantes. Ferramentas de segurança chamadas sistemas de detecção de intrusões atuam como alarmes digitais, examinando esse tráfego em busca de sinais de problema. Mas à medida que os ataques se tornam mais variados e sofisticados, ferramentas antigas baseadas em regras estão tendo dificuldade para acompanhar. Este estudo explora como métodos modernos de aprendizado profundo podem alimentar alarmes mais precisos e adaptáveis que detectam tanto ameaças conhecidas quanto inéditas, mantendo baixo o número de falsos positivos.
De regras fixas a aprender pela experiência
Ferramentas tradicionais de detecção de intrusões funcionam de modo semelhante a antivírus: procuram por assinaturas conhecidas — padrões específicos que correspondem a ataques catalogados. Essa abordagem é rápida e confiável para ameaças familiares, mas falha quando os atacantes mudam de tática ou utilizam explorações do tipo zero-day. Uma estratégia mais recente, a detecção de anomalias, em vez disso aprende como é o comportamento normal da rede e sinaliza atividade incomum. Isso a torna melhor para capturar ataques novos, mas arrisca gerar muitos falsos alarmes. Os autores concentram-se em aprendizado profundo, um ramo da inteligência artificial no qual redes em camadas de unidades de processamento simples aprendem automaticamente padrões a partir dos dados, com o objetivo de combinar a adaptabilidade da detecção de anomalias com a confiabilidade dos sistemas por assinatura.
Colocando dois motores de aprendizado à prova
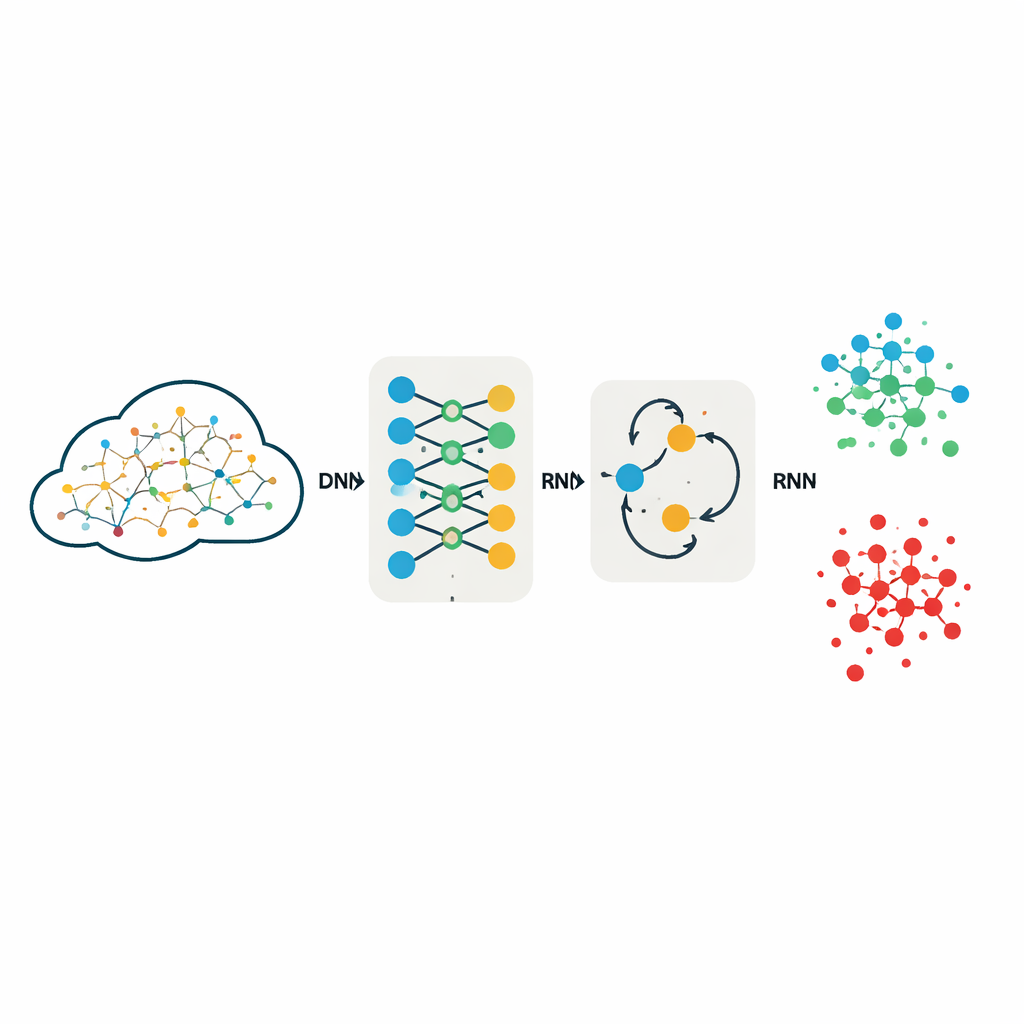
Os pesquisadores avaliam dois modelos populares de aprendizado profundo: uma rede neural profunda (DNN), que processa cada conexão de rede como um registro numérico rico, e uma rede neural recorrente (RNN), que adiciona uma “memória” interna projetada para capturar relações em dados ordenados. Em vez de criar manualmente características, eles alimentam esses modelos com conjuntos completos de medidas que descrevem cada conexão de rede, após converter campos de texto em números e escalar todos os valores. Ambos os modelos são treinados e testados exatamente da mesma forma em três coleções de referência amplamente usadas de tráfego de rede: KDDCup99, NSL-KDD e UNSW-NB15, que juntas cobrem uma ampla gama de tipos de ataque, desde sobrecarregar um servidor com tráfego (DoS) até tentativas furtivas de obter privilégios extras de usuário.
Como o estudo foi cuidadosamente configurado
Para tornar a comparação justa e repetível, a equipe mantém os desenhos dos modelos intencionalmente simples e transparentes. A DNN usa três camadas totalmente conectadas para transformar as 40–42 características de entrada em previsões sobre cinco ou dez categorias de tráfego, como “normal” ou diferentes famílias de ataque. A RNN usa uma camada recorrente leve seguida por uma camada final de decisão, tratando cada registro como uma sequência muito curta para ainda poder modelar interações entre características. Ambos os modelos utilizam a mesma função de ativação e uma estratégia de otimização amplamente adotada, conhecida por promover aprendizado estável. Crucialmente, os autores não descartam características para reduzir os dados; trabalhos anteriores mostraram que redução agressiva de características pode eliminar pistas sutis que são vitais para distinguir ataques raros, porém perigosos.
O que os resultados dizem sobre precisão e confiabilidade
Nos conjuntos de dados mais antigos KDDCup99 e NSL-KDD, ambos os modelos apresentam desempenho notavelmente alto: acurácias superiores a 99% com alarmes falsos abaixo de 1%. Isso significa que quase todas as conexões maliciosas são corretamente detectadas, enquanto muito poucas conexões legítimas são sinalizadas por engano. No UNSW-NB15, um conjunto mais moderno e desafiador com dez classes distintas, o desempenho cai um pouco, como esperado, mas continua forte. A DNN alcança cerca de 96% de acurácia, enquanto a RNN fica em torno de 82%. Pontuações detalhadas mostram que a DNN não só classifica bem ataques comuns, mas também lida com categorias raras como worms e ataques user-to-root com altas pontuações F1, uma métrica que equilibra detectar ataques e evitar perdas. Experimentos com um modelo mais complexo baseado em transformers na verdade apresentaram desempenho inferior, sugerindo que sofisticação arquitetural extra não garante automaticamente melhor segurança.
O que isso significa para redes mais seguras
O estudo conclui que modelos de aprendizado profundo bem projetados, mas relativamente simples, podem formar a espinha dorsal de sistemas práticos de detecção de intrusões. Ao treinar diretamente em conjuntos de referência com recursos completos e ajustando cuidadosamente seu processo de aprendizado, a DNN em particular atinge precisão de ponta com baixos falsos positivos em uma ampla variedade de tipos de ataque. Para usuários cotidianos, isso se traduz em ferramentas de segurança mais capazes de identificar tanto ameaças rotineiras quanto incomuns sem emitir falsos alarmes constantes. Os autores sugerem que trabalhos futuros podem se basear nessa fundação refinando modelos recorrentes, explorando redução seletiva de características para ganho de velocidade e combinando extratores profundos de características com classificadores tradicionais, aproximando-nos de detecção de intrusões que seja ao mesmo tempo poderosa e eficiente em redes do mundo real.
Citação: Kumar, L.K.S., Nethi, S.R., Uyyala, R. et al. Anomaly-based intrusion detection on benchmark datasets for network security: a comprehensive evaluation. Sci Rep 16, 8507 (2026). https://doi.org/10.1038/s41598-026-38317-w
Palavras-chave: detecção de intrusões, segurança de rede, aprendizado profundo, detecção de anomalias, ciberataques