Clear Sky Science · pt
Aprendizado federado para sistemas heterogêneos de prontuários eletrônicos com seleção de participantes custo-efetiva
Por que é tão difícil compartilhar dados hospitalares
Hospitais modernos coletam enormes quantidades de informação digital sobre seus pacientes, desde exames laboratoriais e sinais vitais até medicamentos e procedimentos. Em teoria, combinar esses registros entre muitas instituições deveria permitir que médicos desenvolvessem modelos computacionais mais inteligentes para prever quem está em risco e quais tratamentos podem ajudar mais. Na prática, entretanto, os hospitais usam softwares diferentes, armazenam dados em formatos incompatíveis e precisam proteger estritamente a privacidade dos pacientes e os orçamentos. Este estudo explora como permitir que hospitais aprendam uns com os outros sem copiar os dados nem gastar demais.
Treinar em conjunto sem compartilhar registros brutos
Os autores se baseiam em uma abordagem chamada aprendizado federado, na qual cada hospital treina um modelo local com seus próprios registros de pacientes e então compartilha apenas atualizações do modelo, não os dados brutos. Um hospital central, o “host”, coordena esse processo e busca melhorar um modelo de predição para suas próprias necessidades, como prever complicações em terapia intensiva. Outros hospitais, chamados sujetos, participam em troca de compensação. Essa configuração evita mover registros sensíveis entre instituições, mas levanta duas questões difíceis: como lidar com muitos sistemas de registro diferentes e como evitar pagar por parceiros que na prática não ajudam o modelo.
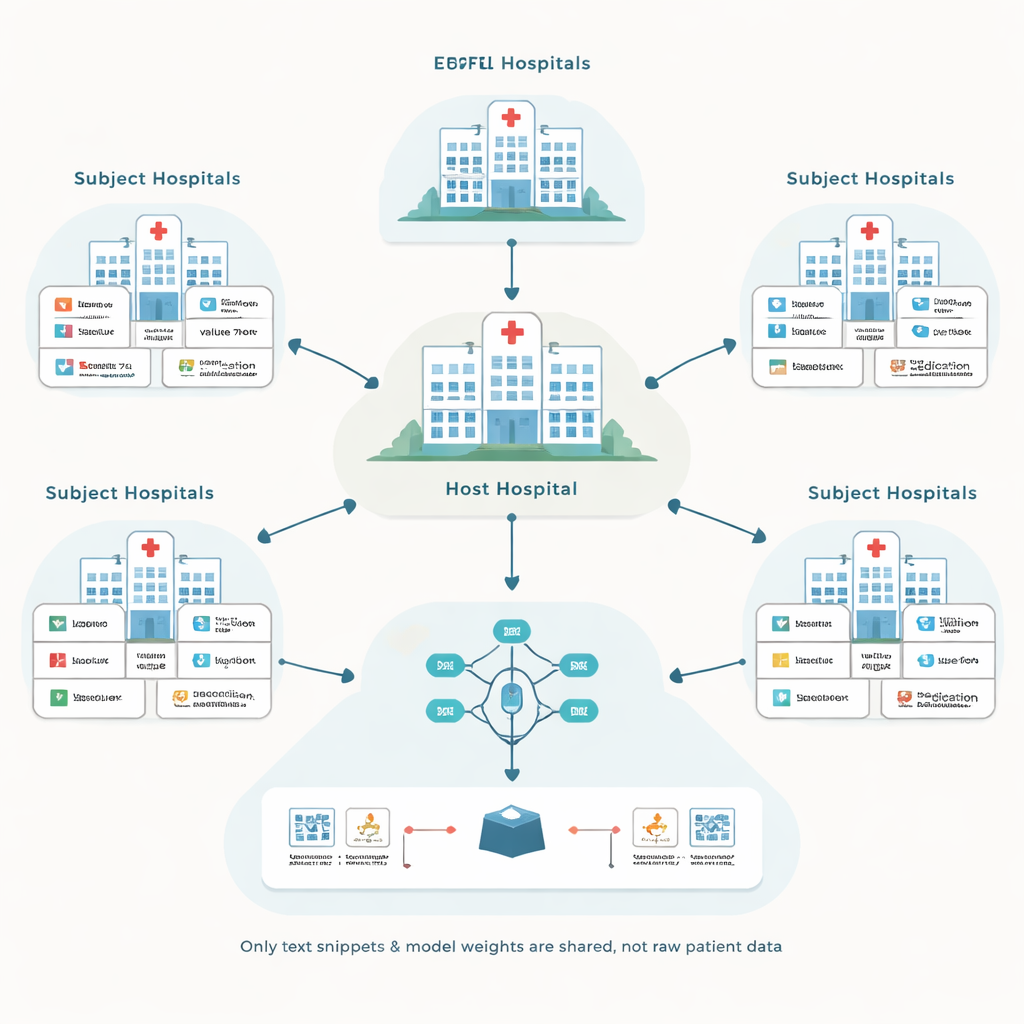
Transformando registros confusos em uma linguagem comum
Sistemas de prontuário eletrônico variam amplamente na forma como rotulam e codificam informações. Um hospital pode armazenar um teste de glicemia sob um código numérico, enquanto outro usa um código diferente para o mesmo exame. Soluções tradicionais tentam converter tudo para um único banco de dados padronizado e cuidadosamente projetado, o que é caro e exige muitas horas de especialistas. Em vez disso, o framework proposto, chamado EHRFL, converte cada evento médico em um pequeno trecho de texto. Por exemplo, uma entrada laboratorial como uma medida de glicose vira uma frase do tipo “evento laboratorial glicose valor 70 mg/dL.” Como cada hospital já mantém dicionários que mapeiam códigos locais para nomes legíveis por humanos, essa conversão pode ser automatizada sem ajustes manuais personalizados.
Construindo perfis de pacientes a partir de texto
Uma vez que os eventos são escritos como texto, o EHRFL usa modelos modernos de processamento de linguagem para transformar cada evento em um vetor numérico e então combina muitos eventos em um único “embedding do paciente” — um resumo compacto do histórico médico daquela pessoa em uma janela temporal. Esses embeddings alimentam uma camada de predição que aborda várias tarefas clínicas ao mesmo tempo, como prever óbito hospitalar ou lesão renal após uma internação em terapia intensiva. Os autores executam o treinamento federado em cinco grandes conjuntos de dados reais de cuidados críticos que abrangem diferentes hospitais, períodos e sistemas de registro. Em uma variedade de algoritmos, incluindo métodos federados comumente usados, modelos treinados com essa abordagem baseada em texto superam consistentemente modelos treinados apenas em um hospital, mesmo quando os formatos de dados subjacentes diferem.
Escolhendo os parceiros certos enquanto se protege a privacidade
Mais hospitais parceiros nem sempre significam resultados melhores. Algumas instituições têm populações de pacientes ou padrões de registro tão diferentes do host que incluí-las pode retardar o treinamento ou prejudicar ligeiramente o desempenho, enquanto ainda adicionam custo. Para lidar com isso, os autores propõem uma etapa de seleção baseada na similaridade entre os embeddings médios de pacientes dos hospitais. O host primeiro treina um modelo com seus próprios dados, compartilha os pesos do modelo, e cada hospital candidato os usa para calcular embeddings de pacientes. Para proteger a privacidade, cada sujeto limita valores extremos em seus embeddings, calcula a média em um único vetor e então adiciona ruído aleatório calibrado antes de enviar apenas essa média ruidosa ao host. O host compara sua própria média com a de cada sujeto usando medidas simples de similaridade e escolhe apenas os hospitais mais parecidos para participar do treinamento federado completo.
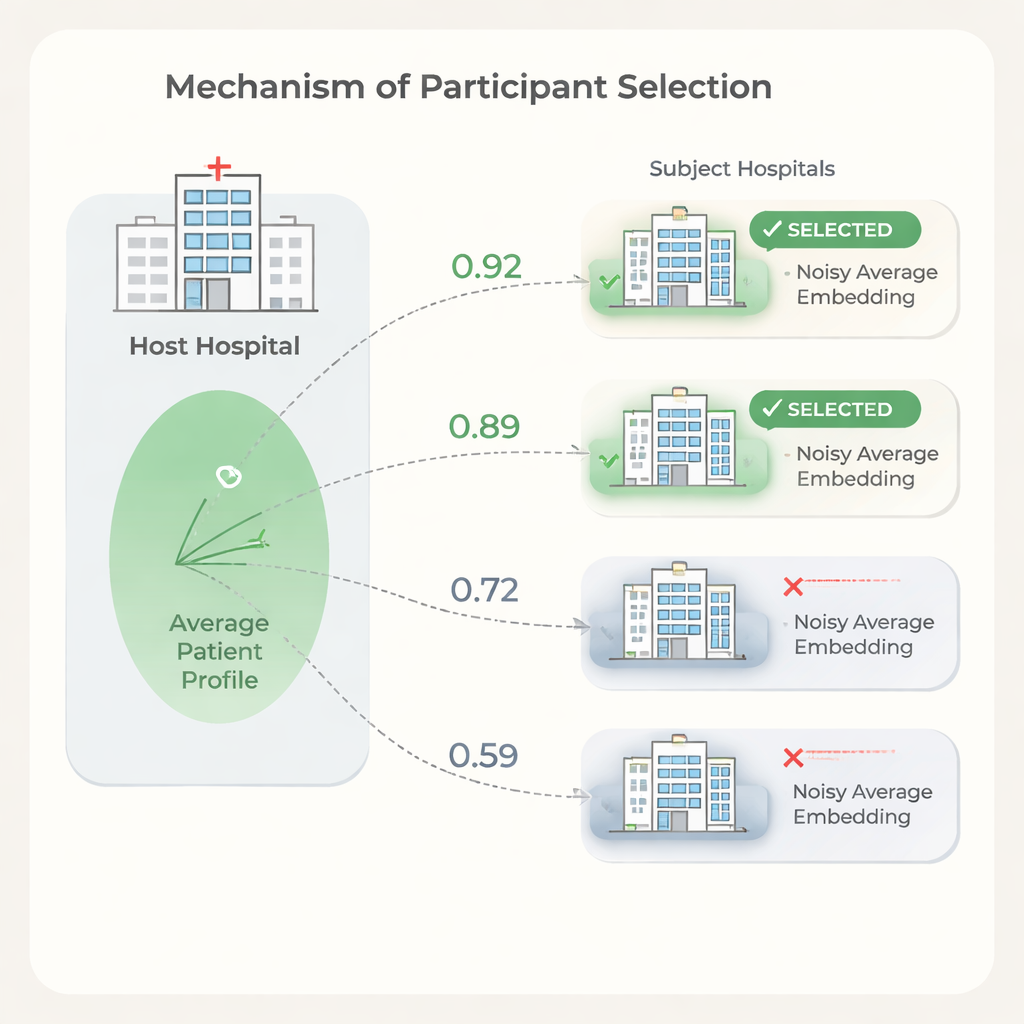
Economizando dinheiro sem perder acurácia
Experimentos mostram que a similaridade entre os embeddings médios de pacientes dos hospitais se alinha com o quanto cada hospital ajuda ou prejudica o desempenho de predição do host. Usando esse sinal para selecionar parceiros, o host pode descartar hospitais de baixa similaridade enquanto mantém ou até melhora a qualidade da predição em comparação com usar todos os sites disponíveis. Os autores também apresentam um modelo de custos que mostra que, como taxas de uso de dados e tempo de treinamento escalam com o número de hospitais participantes, até reduções modestas no número de parceiros podem levar a economias substanciais. Ao mesmo tempo, a etapa de seleção é leve: o modelo é treinado uma vez e cada hospital realiza apenas cálculos simples sobre um único vetor médio.
O que isso significa para o futuro da IA na saúde
Para leitores fora da área, a mensagem principal é que pode ser possível que hospitais “aprendam juntos” sem consolidar registros brutos de pacientes, e fazê-lo de uma maneira que respeite tanto a privacidade quanto limites financeiros. Ao traduzir registros diversos para uma forma textual compartilhada e então usar resumos de populações de pacientes que preservam a privacidade para escolher parceiros compatíveis, o EHRFL oferece uma receita prática para construir ferramentas de predição específicas para cada hospital. Embora o estudo se concentre em dados de terapia intensiva, as mesmas ideias podem se estender a ambulatórios, emergências e até domínios não médicos onde organizações queiram colaborar em modelos melhores sem abrir mão do controle sobre seus dados.
Citação: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Palavras-chave: aprendizado federado, prontuários eletrônicos, privacidade do paciente, predição clínica, IA na saúde