Clear Sky Science · pt
NeuroAction: uma abordagem neuroevolucionária para aprendizado por reforço em veículos autônomos
Por que estilos de direção mais inteligentes importam
A maioria de nós imagina carros autônomos como motoristas calmos e perfeitamente racionais. Mas os sistemas atuais tendem a perseguir uma única combinação de objetivos — como não colidir enquanto levam você rapidamente ao destino — e essa combinação é definida pelos engenheiros. NeuroAction, a abordagem descrita neste artigo, busca dar aos carros autônomos algo mais próximo da flexibilidade humana: a capacidade de escolher entre vários estilos de direção seguros, desde um comportamento cauteloso de "bebê a bordo" até uma condução ágil em rodovias, sem precisar re-treinar o carro a cada vez.
De modelo único para muitas opções seguras
Os sistemas atuais de aprendizado profundo por reforço para direção aprendem por tentativa e erro: observam a estrada, tomam ações como dirigir e acelerar, e recebem uma recompensa numérica única que mistura diferentes objetivos como velocidade, segurança e posicionamento na faixa. Para ajustar o sistema, os engenheiros precisam projetar essa recompensa única com muito cuidado. Se derem peso demais à velocidade, o carro pode dirigir agressivamente; se exagerarem na segurança, ele pode andar lentamente. Mudar preferências depois geralmente significa voltar e re-treinar uma grande rede neural do zero, o que é lento, exige muita memória e é sensível a configurações técnicas.
Dividindo a direção em objetivos simples
NeuroAction enfrenta isso dividindo a tarefa de dirigir em vários objetivos claros em vez de um só. No estudo, o condutor virtual do carro é avaliado de forma independente em três aspectos: quão rápido viaja dentro de um intervalo seguro, quão fielmente permanece na faixa mais à direita (tipicamente mais segura) e quão bem evita colisões. Em vez de combinar esses fatores em uma única pontuação, o método os trata como medidas separadas. Nos bastidores, cada política de direção possível — a rede neural que converte entrada de sensores em decisões de direção e velocidade — é avaliada simultaneamente ao longo dessas três dimensões.
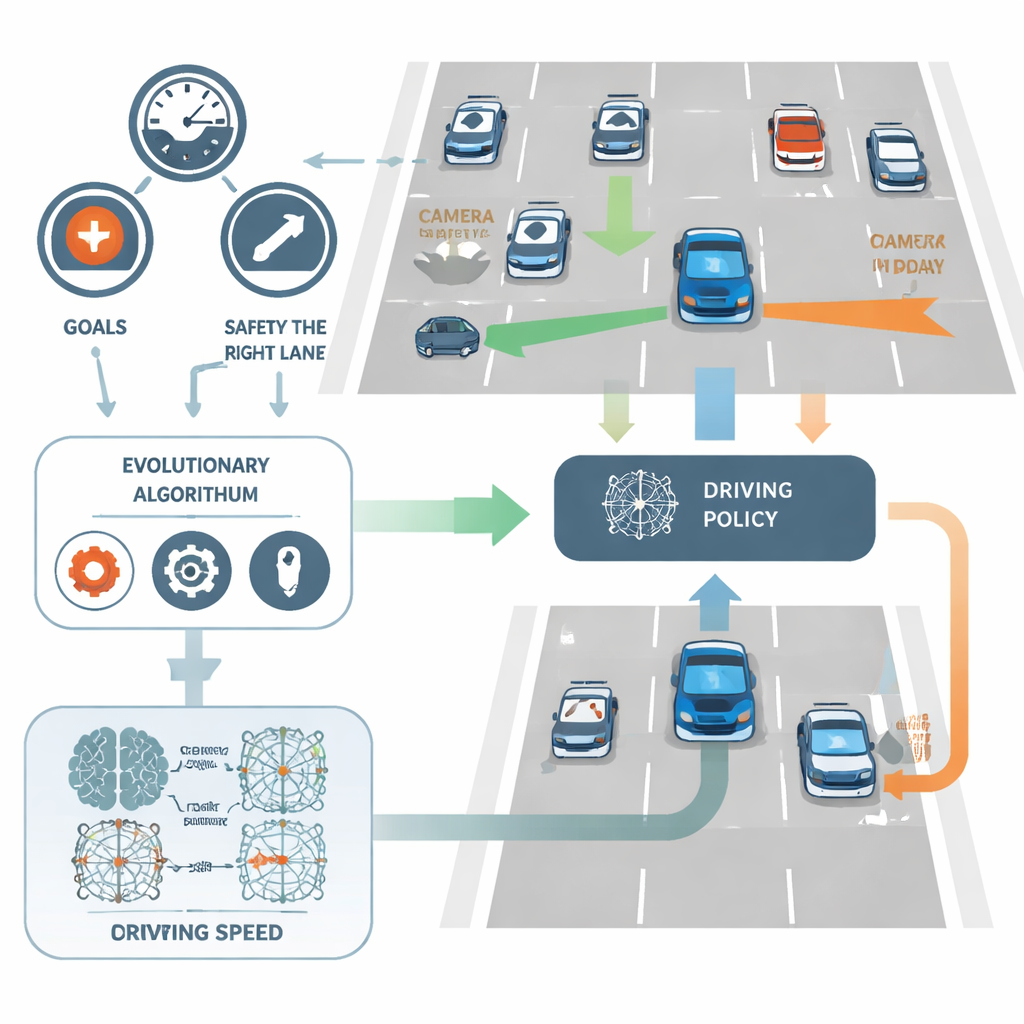
Deixe a evolução procurar melhores motoristas
Em vez de ajustar pesos de rede com a técnica padrão de retropropagação, NeuroAction usa ideias emprestadas da evolução biológica. Uma população de políticas de direção diferentes é criada e testada em um ambiente simulado de rodovia. Políticas que encontram bons trade-offs entre velocidade, disciplina de faixa e segurança são mantidas e recombinadas, enquanto as piores são descartadas. Ao longo de muitas gerações, esse processo evolutivo descobre toda uma fronteira de soluções fortes — conhecida como frente de Pareto — onde nenhuma política pode ser melhorada em um objetivo sem sacrificar pelo menos um dos outros.
Comparando aprendizado evolutivo e baseado em gradiente
Os pesquisadores aplicaram NeuroAction a um simulador de rodovia 2D amplamente usado, empregando um agente de direção padrão baseado em rede neural. Em seguida, otimizaram os parâmetros do agente com vários algoritmos evolucionários multiobjetivo estabelecidos, comparando quão bem cada um conseguia cobrir a gama de trade-offs desejáveis. Uma medida de desempenho chave, o “hipervolume” da fronteira descoberta, captura tanto a qualidade quanto a diversidade das soluções. Um algoritmo, NSGA-II, alcançou a melhor cobertura geral, enquanto um parente próximo, NSGA-III, produziu resultados particularmente consistentes ao longo de execuções repetidas.
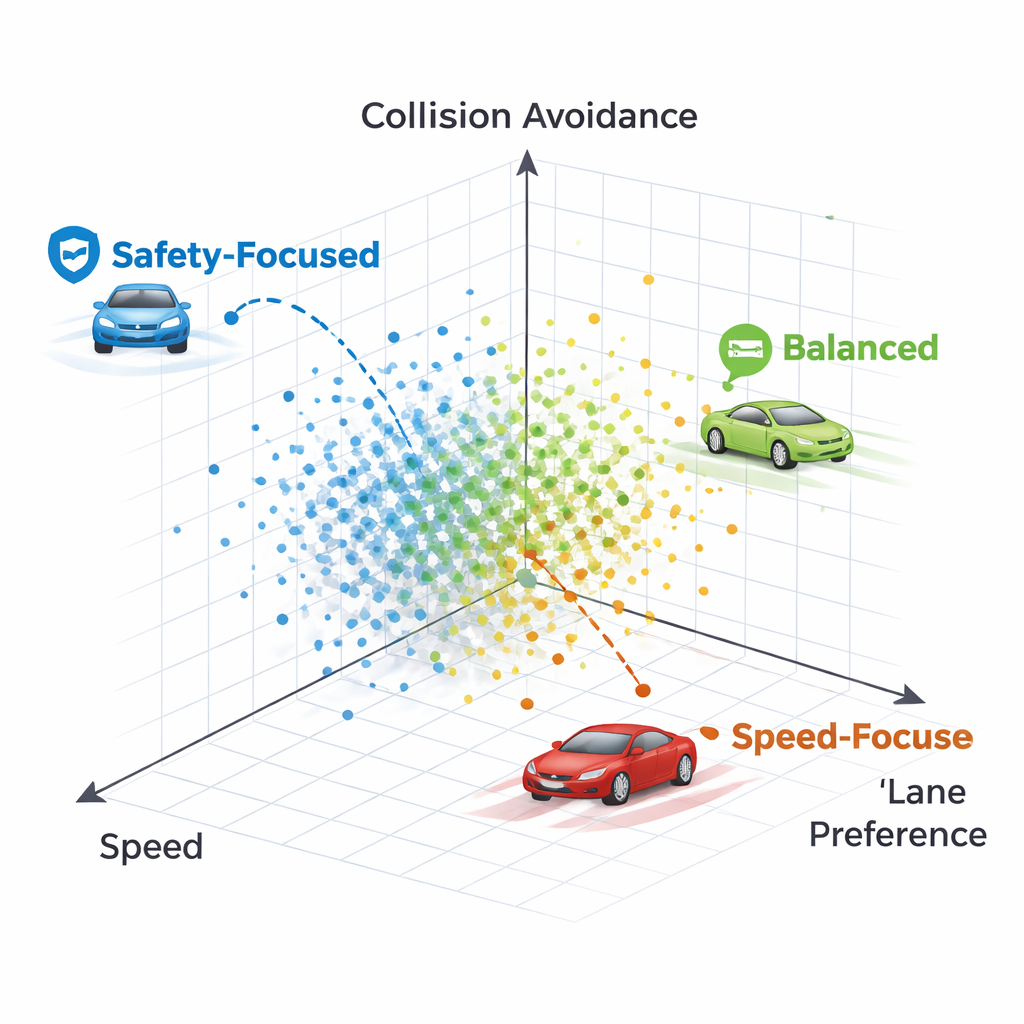
Como diferentes estilos de direção se manifestam
Ao inspecionar políticas individuais na frente de Pareto, os autores mostram que cada ponto corresponde a um estilo de direção reconhecível. Uma política mantém-se firmemente na faixa da direita quase a qualquer custo, sacrificando velocidade e eventualmente colidindo com um veículo muito lento à frente — uma estratégia excessivamente cautelosa que valoriza demais a preferência pela faixa. Outra política muda de faixa inicialmente, mas depois retorna a uma faixa direita livre, mantendo maior velocidade enquanto ainda evita acidentes. Em geral, os métodos produzem um espectro de estratégias que vão de condutores conservadores que preservam a faixa a motoristas mais assertivos, porém ainda seguros, todos disponíveis simultaneamente sem re-treinamento.
O que isso significa para os carros autônomos do futuro
Para um público não especializado, a mensagem central é que NeuroAction transforma o treinamento de carros autônomos em uma busca por muitas boas opções em vez de um comportamento fixo. Isso possibilita selecionar uma política de direção para adequar-se à situação — lenta e ultra-segura ao transportar crianças, mais rápida quando você tem pressa — ao mesmo tempo em que respeita restrições de segurança. Embora os experimentos atuais sejam em simulação e usem objetivos simplificados, o arcabouço aponta para veículos autônomos mais adaptáveis e sensíveis às preferências, capazes de oferecer estilos de direção personalizados e confiáveis, fundamentados em uma base matemática sólida.
Citação: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Palavras-chave: condução autônoma, aprendizado por reforço, algoritmos evolutivos, otimização multiobjetivo, carros autônomos