Clear Sky Science · pt
Decomposição de tensores sem posto via aprendizado de métrica
Encontrando padrões em um mar de dados
A ciência moderna está sobrecarregada por dados complexos: pilhas de exames médicos, mapas de atividade cerebral, imagens astronômicas e simulações de materiais. Fazer sentido desses dados frequentemente significa condensá‑los em formas mais simples sem perder o que realmente importa. Este artigo apresenta uma nova maneira de fazer isso. Em vez de tentar reconstruir fielmente cada pixel, a proposta se concentra em capturar as verdadeiras relações entre amostras — qual cérebro se parece mais com qual, qual formato de galáxia se assemelha a qual — de modo que o mapa resultante dos dados reflita significado em vez de detalhes brutos.
De reconstruir imagens a medir similaridade
Ferramentas tradicionais para simplificar dados multidimensionais, conhecidas como decomposições de tensores, funcionam um pouco como decompor um acorde em notas. Elas fatoram um “bloco” de dados em um pequeno número de padrões básicos mais pesos. Para isso, é preciso informar antecipadamente quantos padrões — o “posto” — poderão ser usados, e o sucesso é avaliado pela qualidade da reconstrução dos dados originais. Isso é ideal para compressão ou remoção de ruído, mas nem sempre serve para tarefas como “essas duas faces são da mesma pessoa?” ou “esse exame cerebral pertence a um sujeito autista ou típico?”, onde agrupar corretamente importa mais do que reconstruir perfeitamente.
Paralelamente, o aprendizado profundo popularizou outra ideia: em vez de decompor um tensor algebraicamente, aprende‑se um código numérico compacto, ou embedding, por meio de uma rede neural. Autoencoders clássicos ainda focam na reconstrução. Este trabalho inverte o objetivo. Propõe um framework “sem posto” que não fixa um posto antecipadamente e não se importa com recuperação pixel a pixel. Em vez disso, aprende uma medida de distância para que pontos que deveriam estar próximos (mesma pessoa, mesmo diagnóstico, mesma classe física) se tornem vizinhos no espaço de embedding, e pontos que deveriam ser diferentes sejam afastados.
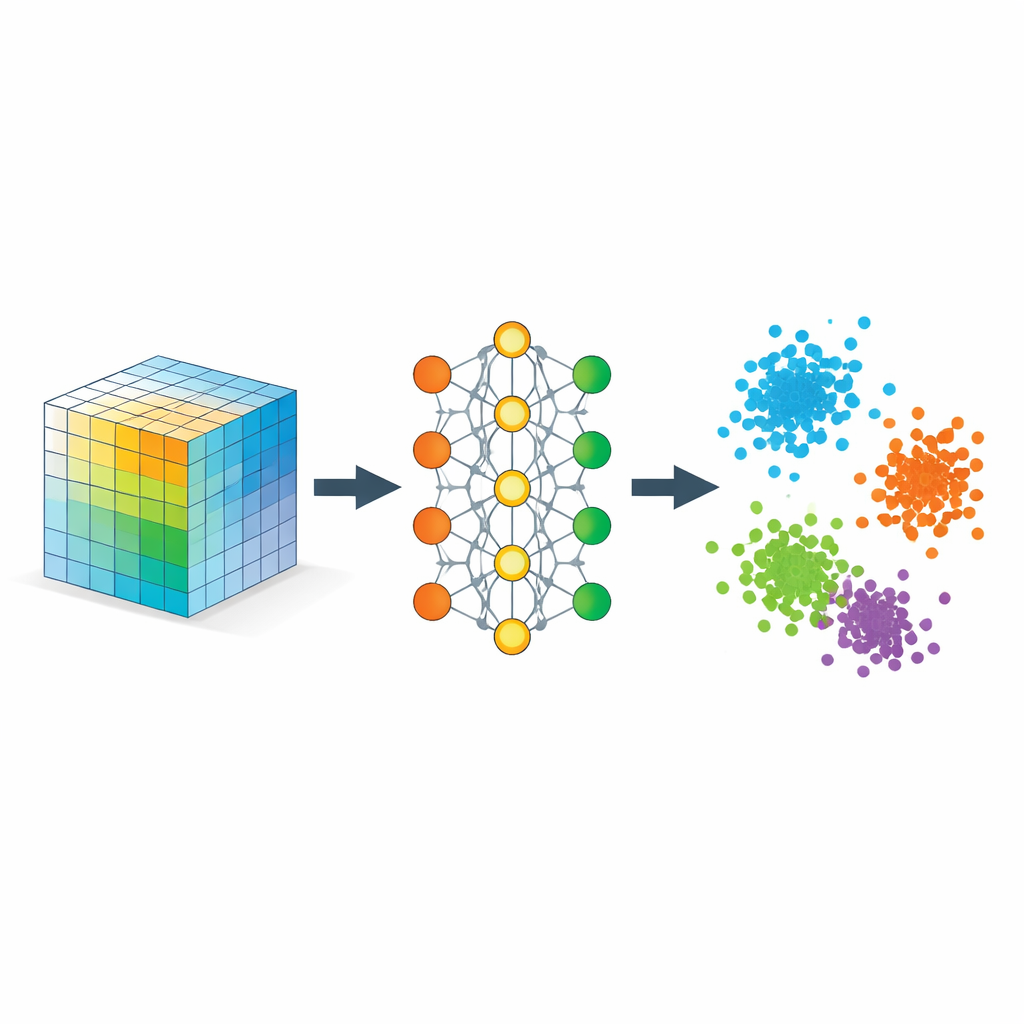
Ensinando à rede o que “próximo” deve significar
O ingrediente chave é uma estratégia chamada aprendizado de métrica, implementada aqui por meio de tríplices de exemplos: uma amostra âncora, uma amostra positiva do mesmo tipo e uma amostra negativa de tipo diferente. Durante o treinamento, a rede é recompensada quando a âncora fica mais próxima da positiva do que da negativa por uma margem de segurança. Ao longo de muitos tríplices assim, essa regra simples modela o espaço de embedding para que as distâncias reflitam similaridade semântica em vez de similaridade bruta de pixels. Regularizadores adicionais incentivam a rede a distribuir a informação uniformemente pelas dimensões, evitar o colapso em uma linha e manter vizinhanças locais razoavelmente intactas, de modo que pontos próximos nos dados originais permaneçam próximos quando incorporados.
Matematicamente, os autores mostram que esse embedding se comporta como uma decomposição de tensor flexível, mas sem um posto pré‑definido. As coordenadas aprendidas podem ser interpretadas como fatores em uma decomposição clássica de um tensor de similaridade cujas entradas medem o quanto diferentes partes dos dados se alinham. Como o modelo penaliza direções redundantes, tende a usar efetivamente todas as dimensões do embedding, deixando que os próprios dados determinem quantos componentes significativos são necessários. Ao mesmo tempo, eles fornecem garantias teóricas de que os procedimentos padrão de treinamento convergem e que a geometria resultante separa classes de forma fiel sem distorcer exageradamente relações locais relevantes.
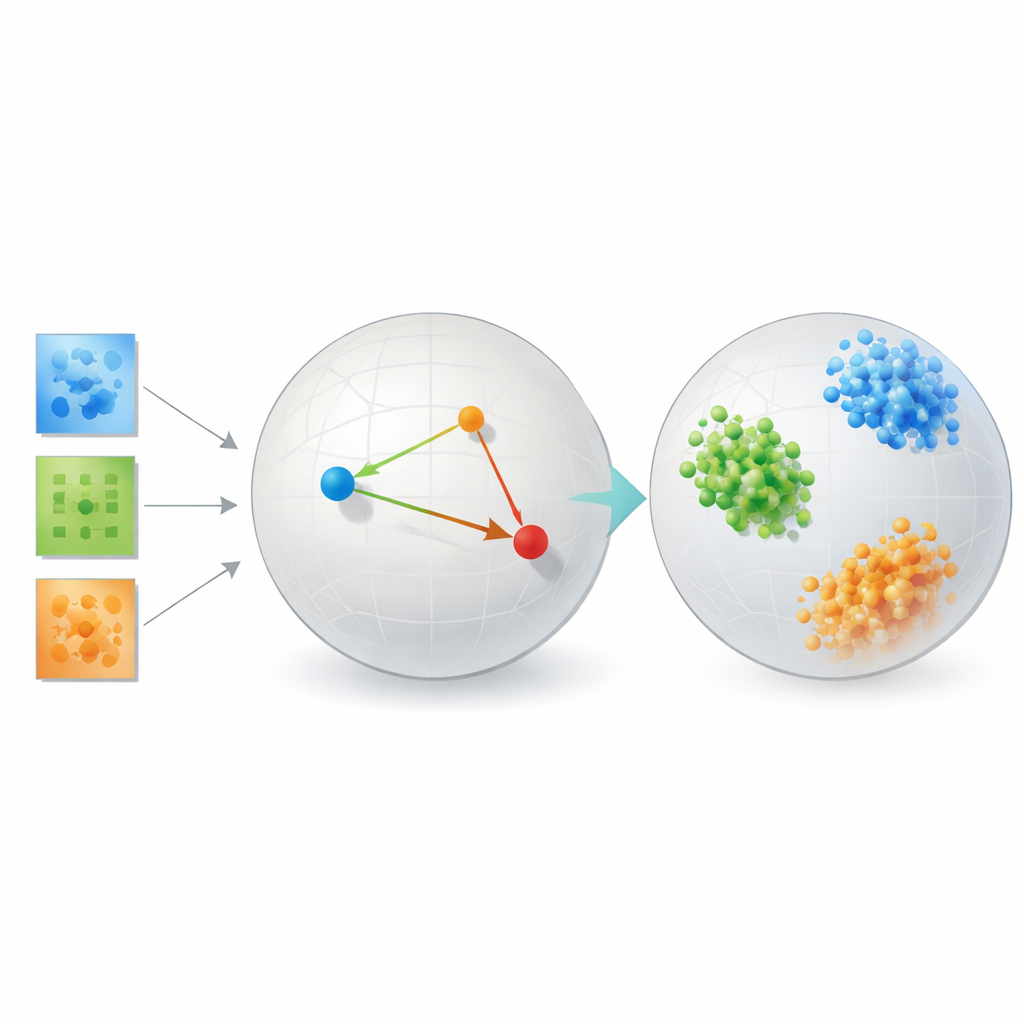
Colocando o método à prova
Para demonstrar que a abordagem não é apenas teoria elegante, o autor a testa em vários problemas bastante distintos. Em benchmarks de reconhecimento facial, os embeddings aprendidos agrupam imagens da mesma pessoa em aglomerados apertados e bem separados, superando dramaticamente métodos clássicos como componentes principais, ferramentas populares de visualização como t‑SNE e UMAP, e decomposições de tensor tradicionais que dependem de postos fixos. Em dados de conectividade cerebral de pessoas com e sem autismo, o método descobre um espaço onde os dois grupos ficam mais nitidamente separados do que com ferramentas de tensor focadas em reconstrução ou redes autoencoder, sugerindo que ele está captando padrões clinicamente relevantes em como regiões cerebrais interagem.
O estudo também inclui simulações controladas de formatos de galáxias e estruturas cristalinas, onde as categorias “verdadeiras” são conhecidas com precisão. Nesses casos, o framework de aprendizado de métrica quase perfeitamente agrupa as galáxias e cristais sintéticos por seus tipos físicos subjacentes. Em todos esses cenários, o método consistentemente troca um pouco de fidelidade ao layout de pixels original por uma representação na qual similaridade e diferença correspondem ao significado científico. Importante: faz isso sem os vastos dados e recursos computacionais frequentemente necessários para treinar modelos profundos baseados em transformers, que tiveram dificuldades nesses conjuntos de dados científicos relativamente pequenos.
Por que isso importa para os dados científicos futuros
Para cientistas que buscam padrões em dados limitados e de alta dimensionalidade, este trabalho oferece uma mudança de perspectiva atraente. Em vez de adivinhar um posto e otimizar para reconstrução, pesquisadores podem pedir diretamente um embedding que reflita as relações que lhes interessam: mesmo diagnóstico, mesma fase de material, mesma classe astrofísica. O framework proposto de aprendizado de métrica sem posto mostra que tais embeddings podem ser ao mesmo tempo interpretáveis e poderosos, especialmente quando os dados são escassos. Como o autor observa, desafios permanecem — incluindo lidar com desequilíbrio entre classes e escalar para muitas categorias — mas a mensagem é clara: em muitos problemas científicos, aprender uma boa noção de similaridade pode ser mais valioso do que reconstruir cada detalhe do sinal original.
Citação: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Palavras-chave: aprendizado de métrica, decomposição de tensores, aprendizado de representação, redução de dimensionalidade, análise de dados científicos