Clear Sky Science · pt
Modelagem de degradação acoplada em rede guiada por VLM para fusão de imagens infravermelho e visível consciente da degradação
Visão Noturna Mais Nítida para um Mundo Barulhento
Câmeras modernas conseguem ver no escuro, detectar calor e vigiar a estrada por nós — mas suas imagens muitas vezes estão longe da perfeição. Lâmpadas de rua geram halos, sombras escondem detalhes e os sensores acrescentam ruído pontilhado. Este estudo apresenta uma nova forma de mesclar vídeo colorido comum com imagens infravermelhas que detectam calor, de modo que a visão final fique mais clara e confiável, mesmo quando ambas as entradas estão severamente degradadas. O método pode tornar carros autônomos, sistemas de vigilância e outras câmeras inteligentes mais dependáveis nas condições em que mais precisamos: à noite, em mau tempo e em cenas reais confusas.
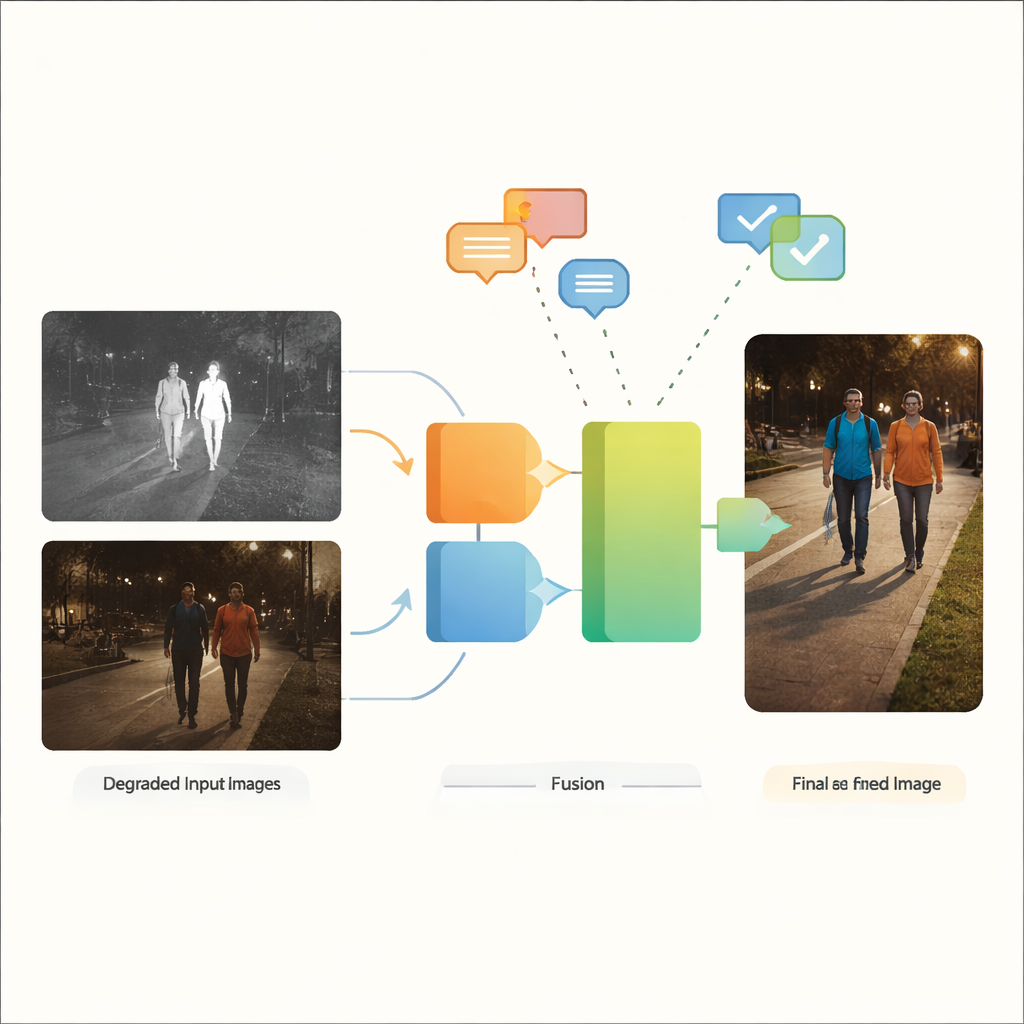
Por Que Dois Olhos São Melhores que Um
Câmeras de luz visível capturam as cores ricas e as texturas às quais estamos acostumados, mas têm dificuldade em baixa luminosidade, em face de brilho intenso e sob sombras profundas. Câmeras infravermelhas, por outro lado, detectam calor e conseguem destacar facilmente objetos quentes como pessoas ou veículos no escuro, embora suas imagens frequentemente pareçam planas e sem detalhes finos. A fusão de imagens infravermelhas e visíveis busca combinar o melhor dos dois: os contornos nítidos de alvos quentes do infravermelho com o detalhe contextual e a cor da luz visível. Tradicionalmente, porém, a maioria dos métodos de fusão parte do pressuposto de que ambas as imagens de entrada já estão limpas e de alta qualidade — uma suposição inadequada para ruas, cidades e locais industriais reais, onde desfoque, ruído, iluminação fraca e superexposição são a norma e não a exceção.
Quando o Pré-processamento Não Basta
Sistemas existentes normalmente enfrentam imagens ruins em dois passos desconectados. Primeiro, ferramentas de melhoria separadas clareiam cenas escuras, reduzem ruído ou corrigem contraste. Só então uma rede de fusão mistura as imagens melhoradas. Essa abordagem em duas etapas tem várias limitações. Obriga engenheiros a escolher e ajustar diferentes ferramentas de melhoria para cada tipo de defeito e cada sensor, tornando os fluxos de trabalho frágeis e complexos. Mais importante, qualquer informação perdida ou distorcida durante a limpeza isolada não pode ser recuperada depois pela etapa de fusão. Pesquisas recentes introduziram redes especiais ajustadas a um tipo específico de degradação ou usaram modelos guiados por linguagem para lidar com uma única modalidade degradada por vez. Ainda assim, quando tanto imagens infravermelhas quanto visíveis estão degradadas — e frequentemente de maneiras diferentes — essas estratégias continuam dependendo fortemente de pré-processamento manual e têm dificuldade com condições mistas do mundo real.
Uma Rede de Fusão que Entende Degradação
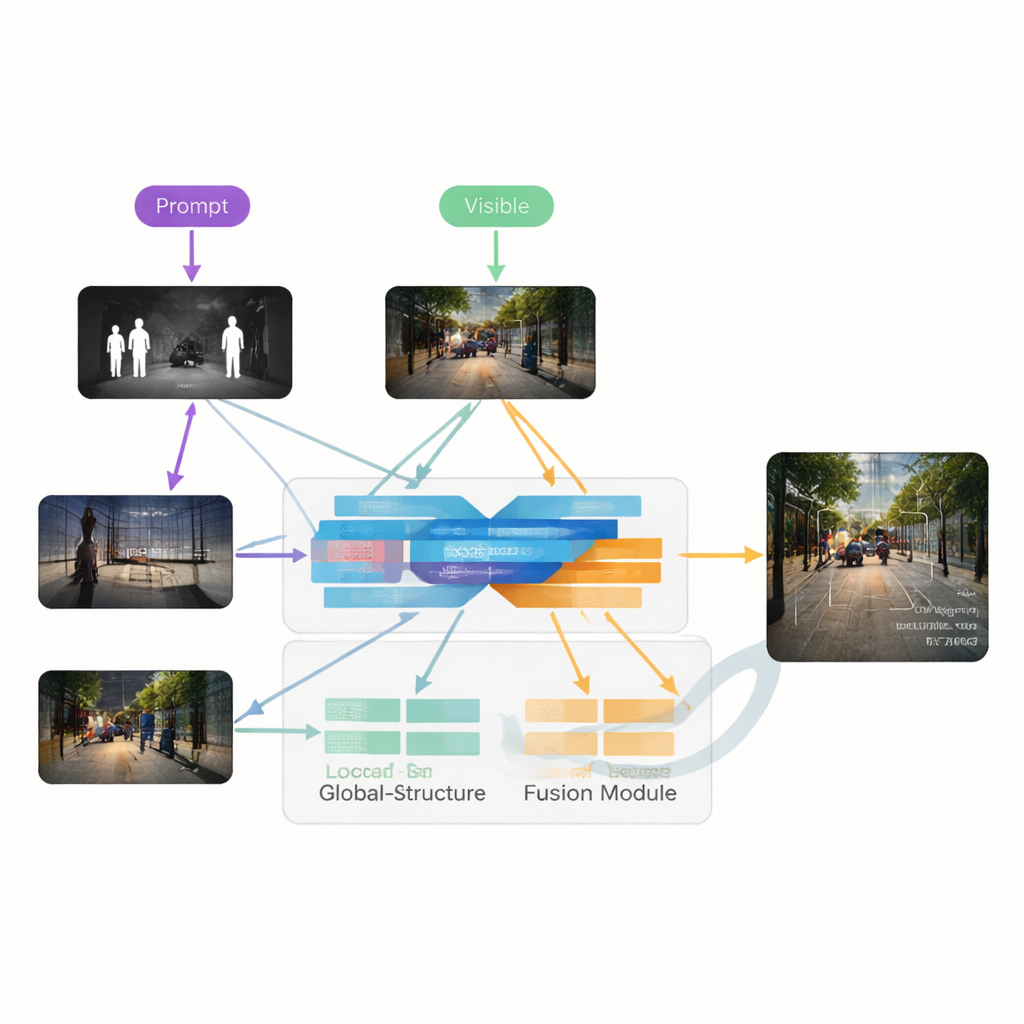
Os autores propõem o VGDCFusion, um novo framework de deep learning que incorpora o tratamento da degradação diretamente no processo de fusão. A ideia central é informar à rede, em palavras, que tipo de problemas ela deve esperar, e então usar esse conhecimento em cada etapa da extração e da fusão de características. Prompts de texto curtos descrevem a tarefa (fusão infravermelho–visível) e os problemas específicos presentes, como baixa luminosidade, superexposição, baixo contraste ou ruído. Um poderoso modelo visão–linguagem — semelhante em espírito a sistemas como o CLIP — transforma esses prompts em descritores numéricos compactos. Esses descritores guiam dois blocos principais: o Specific-Prompt Degradation-Coupled Extractor (SPDCE), que opera separadamente em cada modalidade, e o Joint-Prompt Degradation-Coupled Fusion (JPDCF), que combina informações entre as modalidades enquanto continua atento ao tipo de degradação remanescente.
Como Funciona o Processo de Fusão Guiada
Dentro de cada módulo SPDCE, a orientação derivada do prompt direciona a rede para características relevantes e afasta artefatos. Camadas convolucionais multiescala observam vizinhanças pequenas para preservar bordas e texturas, enquanto camadas Transformer capturam estrutura e contexto em maior escala. Juntas, elas aprendem a destacar, por exemplo, assinaturas térmicas importantes em um quadro infravermelho ruidoso ou marcações de pista tênues em uma imagem visível subexposta, ao mesmo tempo em que suprimem ruído do sensor e defeitos de iluminação. Em paralelo, os módulos JPDCF recebem as características refinadas de ambos os ramos e as combinam, novamente sob a orientação dos prompts. Eles usam atenção espacial e por canal para enfatizar regiões informativas, filtrar degradação residual e reunir pistas complementares — como alinhar o contorno brilhante de um pedestre no infravermelho com a cor e a estrutura de fundo da câmera visível — antes de reconstruir uma imagem de saída fundida em três canais.
Colocando o Método à Prova
Para demonstrar sua utilidade, a equipe avaliou o VGDCFusion em vários conjuntos de dados públicos que incluem imagens visíveis em baixa luminosidade e superexpostas, bem como imagens infravermelhas ruidosas ou de baixo contraste. Compararam seu método com uma variedade de técnicas de fusão de ponta, abrangendo autoencoders, redes convolucionais, redes adversariais geradoras e Transformers. Usando medidas padrão de qualidade de imagem, o VGDCFusion produziu de forma consistente imagens fundidas com bordas mais nítidas, melhor contraste e cor mais natural, mesmo quando métodos concorrentes receberam a vantagem de pré-processamento cuidadosamente ajustado. A nova abordagem melhorou métricas-chave em cerca de 15% em média em cenários fortemente degradados. Quando as imagens fundidas foram inseridas em um sistema popular de detecção de objetos, também resultaram em maior precisão de detecção do que o uso isolado de imagens infravermelhas ou visíveis, ou do que outras redes de fusão.
Visão Mais Clara para Sistemas Mais Seguros
Em termos simples, este trabalho mostra que dizer a uma rede de fusão de imagens que tipos de problemas visuais esperar — e permitir que ela corrija e fusione em um único passo fortemente conectado — pode gerar imagens mais limpas e informativas do que tratar melhoria e fusão como tarefas separadas. Ao acoplar a modelagem da degradação ao processo de fusão e usar sinais guiados por linguagem em cada camada, o VGDCFusion pode se adaptar a formas variadas e mistas de degradação de imagem sem necessidade de ajuste humano constante. Esse tipo de fusão inteligente e consciente da degradação pode ajudar futuros sistemas de visão, desde carros autônomos até câmeras de segurança, a enxergar com mais confiabilidade nas condições imperfeitas e bagunçadas do mundo real.
Citação: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Palavras-chave: fusão infravermelho e visível, imagens em baixa luminosidade, modelos visão-linguagem, degradação de imagem, percepção para direção autônoma