Clear Sky Science · pt
Uma estrutura híbrida de ensemble empilhado para detecção multilabel de emoções em texto
Por que ler emoções em texto importa
Todo dia, pessoas despejam seus sentimentos em publicações nas redes sociais, avaliações e mensagens. Ocultos nesse fluxo de palavras estão sinais precoces sobre problemas de saúde mental, aumento do discurso de ódio e reações públicas a crises e desastres. Mas os computadores geralmente reconhecem apenas “sentimento positivo” ou “negativo”, perdendo a mistura de emoções que pessoas reais frequentemente expressam ao mesmo tempo. Este artigo explora uma nova forma de ensinar máquinas a reconhecer várias emoções em um único texto e a fazê-lo não apenas em inglês, mas também em idiomas que raramente se beneficiam de inteligência artificial avançada.
Indo além do simples positivo ou negativo
Ferramentas tradicionais de análise de sentimento são como termômetros grosseiros: conseguem dizer se o clima é bom ou ruim, mas não se alguém sente raiva, medo, esperança ou alívio simultaneamente. Os autores defendem que entender essa paleta emocional mais rica é crucial para aplicações como resposta a desastres, suporte terapêutico e atendimento ao cliente. Uma mensagem que mistura medo e urgência, por exemplo, pode exigir atenção imediata, enquanto outra que combine tristeza e otimismo pode pedir um tipo diferente de apoio. Capturar várias emoções em paralelo — conhecido como detecção de emoções multilabel — é portanto um passo-chave rumo a sistemas mais sensíveis e conscientes do humano.
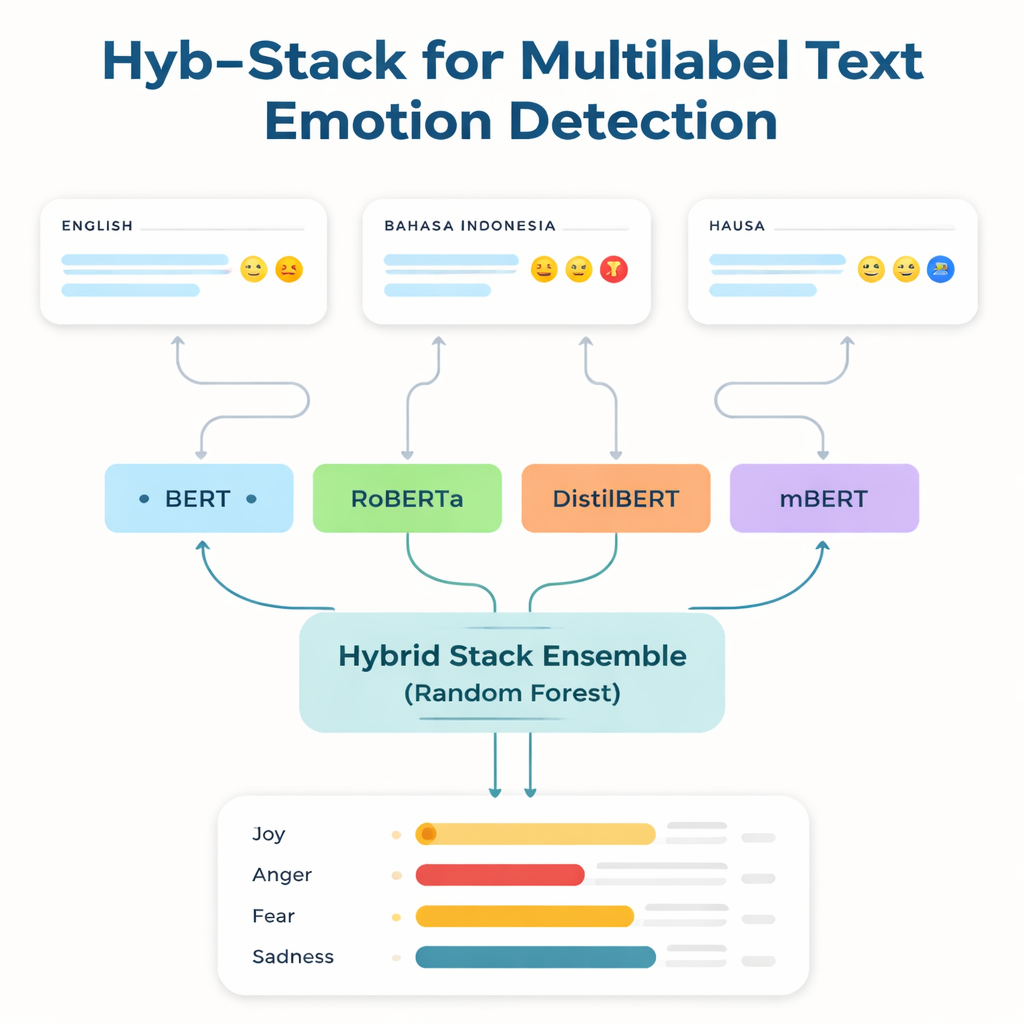
Dando voz a idiomas negligenciados
A maioria das tecnologias linguísticas mais poderosas é treinada e ajustada em inglês e em alguns outros idiomas amplamente usados. Falantes de línguas com poucos recursos — aquelas com poucos dados rotulados e poucas ferramentas digitais — frequentemente ficam para trás. Para enfrentar essa lacuna, os pesquisadores focam em três conjuntos de dados: um benchmark de emoções bem conhecido em inglês; uma coleção em Bahasa Indonesia centrada em linguagem abusiva e de ódio; e um corpus novo do Twitter em Hausa que eles criaram, chamado HaEmoC_V1. O conjunto de dados em Hausa inclui mais de doze mil tweets cuidadosamente limpos e anotados, cada um marcado com uma ou mais de onze emoções, como raiva, alegria, confiança, pessimismo e antecipação. Revisores especialistas checaram os rótulos, e as pontuações de concordância mostraram que as anotações são ao mesmo tempo consistentes e confiáveis.
Combinando vários leitores inteligentes em um só
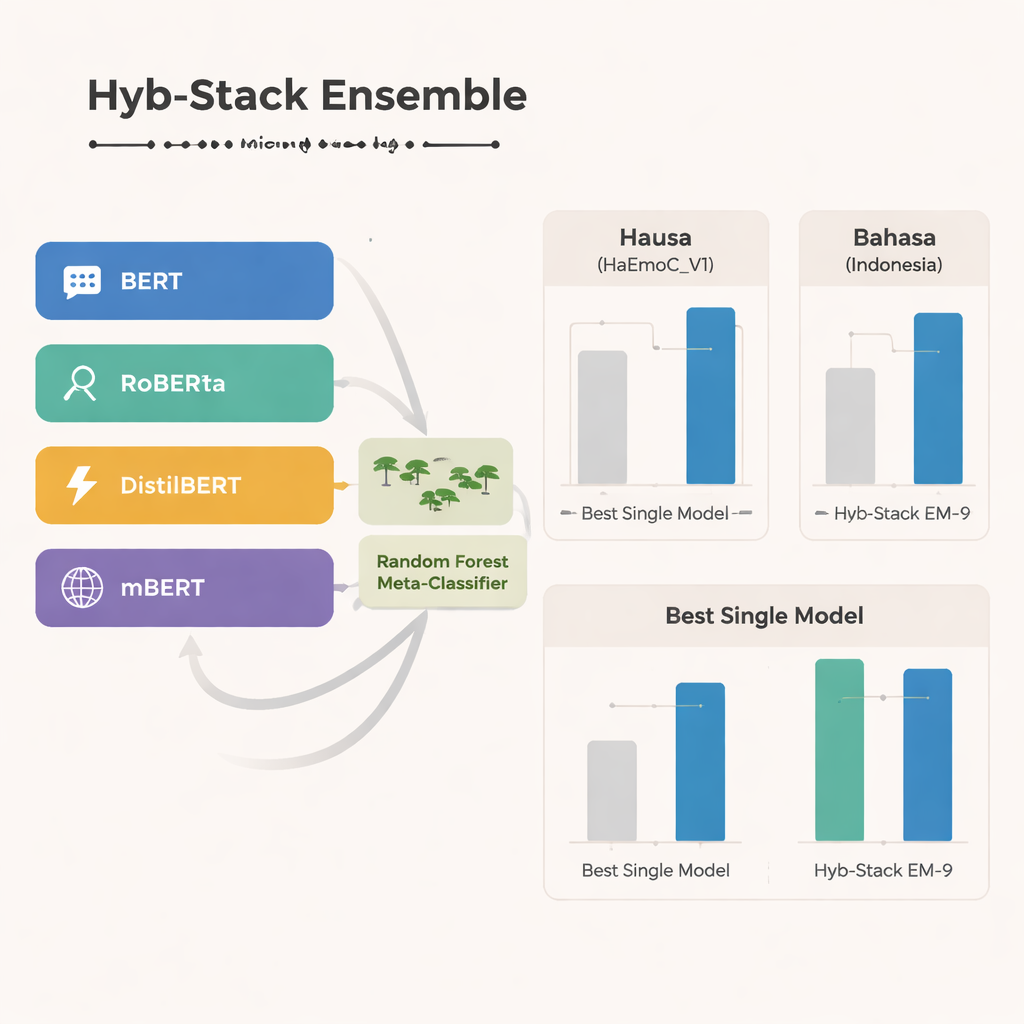
No núcleo do estudo está o Hyb-Stack, um ensemble híbrido empilhado — uma espécie de “comitê de especialistas” para linguagem. Quatro modelos avançados baseados em transformers (BERT, RoBERTa, DistilBERT e o multilingue mBERT) são finamente ajustados para ler sinais emocionais no texto. Em vez de confiar apenas em um modelo, o Hyb-Stack permite que todos façam previsões e então alimenta suas pontuações internas a um tomador de decisão de segundo nível: um classificador Random Forest. Esse meta-classificador aprende a ponderar as diferentes forças de cada modelo, capturando padrões complexos em como as emoções coocorrem. A equipe também testa métodos de ensemble mais simples que apenas fazem a média das previsões, com ou sem ponderação pela performance prévia, para ver se o empilhamento mais elaborado realmente compensa.
Quão bem a abordagem híbrida performa
Em todos os três idiomas, o multilingue mBERT se destaca como o modelo único mais forte, apresentando desempenho especialmente bom nos dados recém-construídos em Hausa e no conjunto de discurso de ódio em Bahasa Indonesia. Ainda assim, o ensemble híbrido vai além. Uma combinação particular — chamada EM-9, que une BERT, DistilBERT e mBERT dentro da estrutura Hyb-Stack — entrega consistentemente os melhores resultados. Ela alcança pontuações F1 maiores, uma medida comum de acurácia, do que qualquer modelo individual ou abordagem de média simples, com os maiores ganhos aparecendo nos conjuntos de baixa disponibilidade de dados em Hausa e Bahasa Indonesia. Análises detalhadas de erro mostram que os equívocos restantes normalmente ocorrem entre emoções intimamente relacionadas, como alegria versus surpresa ou tristeza versus medo, refletindo a imprecisão natural do sentimento humano em vez de falhas claras do sistema.
O que isso significa para sistemas do mundo real
Para um leitor geral, a principal conclusão é que combinar vários modelos de IA de maneira inteligente pode ajudar computadores a ler emoções em texto com mais precisão, especialmente em idiomas que foram por muito tempo negligenciados pela tecnologia. Ao construir um corpus de alta qualidade em Hausa e mostrar que ensembles híbridos superam modelos únicos e esquemas de votação simples, os autores demonstram um caminho prático rumo a ferramentas mais inclusivas e sensíveis às emoções. Trabalhos futuros ampliarão a abordagem para matizes emocionais mais sutis, linguagem code-mixed, emojis e idiomas subrepresentados adicionais, com o objetivo de criar sistemas capazes de perceber não apenas se as pessoas estão felizes ou tristes, mas como e por que elas se sentem assim — independentemente da língua que falem.
Citação: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Palavras-chave: detecção de emoção, PNL multilingue, aprendizado por ensemble, modelos transformer, línguas com poucos recursos