Clear Sky Science · pt
Cálculo eficiente e projeto de arquitetura multiplicadora Védica de dupla precisão e alta velocidade
Por que acelerar os cálculos importa
Cada vez que você transmite um vídeo, usa a navegação no celular ou permite que um sistema de IA analise imagens médicas, hardware de computador especializado está silenciosamente realizando bilhões de pequenos cálculos por segundo. Uma grande parte dessas operações são multiplicações em números de ponto flutuante, a forma padrão como os computadores representam valores reais como 3,14159. Este artigo explora uma maneira mais inteligente de construir um desses componentes centrais: um multiplicador de alta velocidade e eficiência energética que aproveita ideias da antiga matemática védica para impulsionar o hardware digital moderno.
De truques matemáticos antigos a chips modernos
A aritmética de ponto flutuante sustenta o processamento digital de sinais, o processamento de imagens, as comunicações e os aceleradores de aprendizado profundo. Multiplicadores padrão precisam lidar com palavras binárias largas — 64 bits para dupla precisão — e fazê‑lo rapidamente sem desperdiçar área do chip ou energia. Abordagens tradicionais, como Booth, Karatsuba e multiplicadores em arranjo, equilibram compromissos entre velocidade, tamanho de hardware e complexidade de projeto. A matemática védica, um sistema de 16 regras aritméticas clássicas desenvolvido na Índia, inclui um método de multiplicação chamado Urdhva Tiryakbhyam, ou “vertical e cruzado”. Ele forma produtos parciais de maneira altamente paralela, o que pode reduzir o número de etapas intermediárias e o hardware necessário. Pesquisadores adaptaram recentemente essas ideias para circuitos digitais, mas os projetos existentes ainda carregam sobrecargas quando usados para operações de ponto flutuante em dupla precisão.
O que há de especial neste novo multiplicador
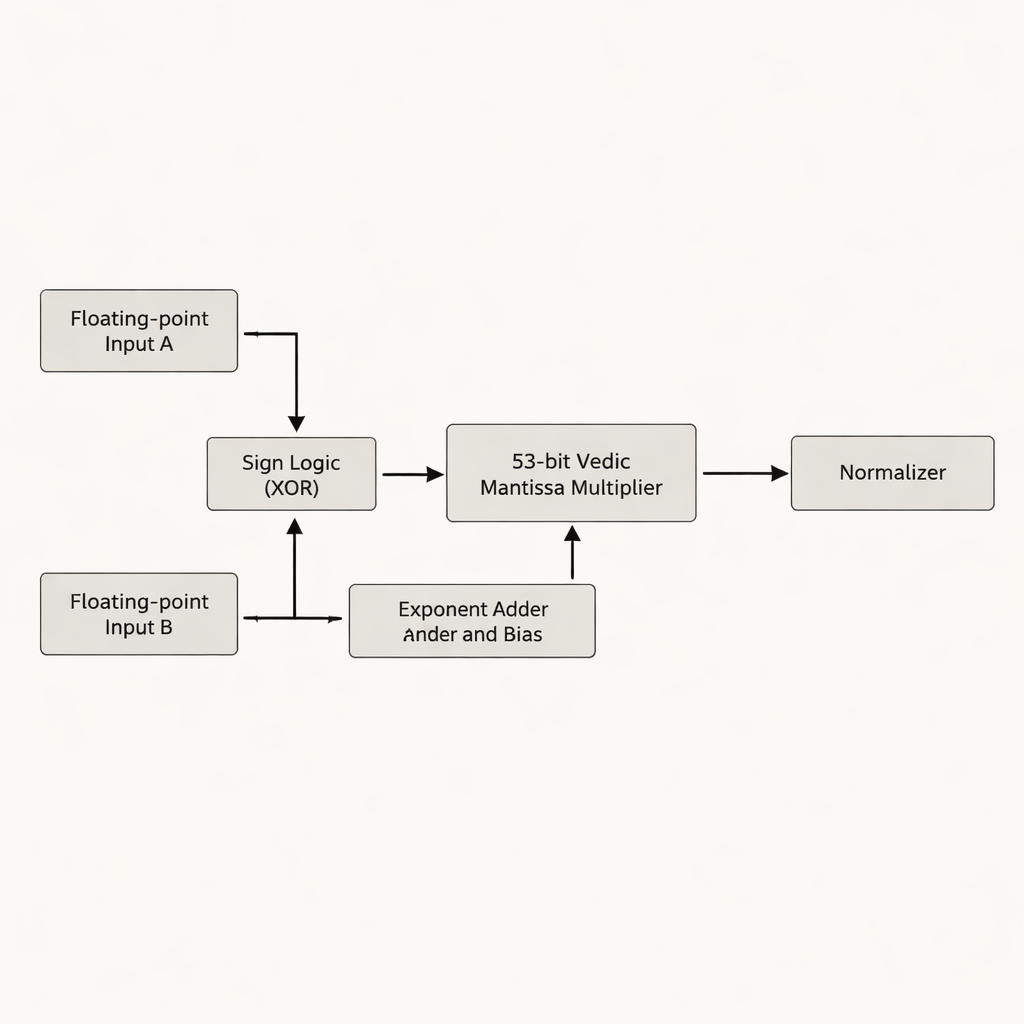
Os autores propõem um multiplicador de ponto flutuante de dupla precisão que foca na mantissa — a parte de um número em ponto flutuante que contém a maioria dos dígitos significativos. Em vez de preencher a mantissa de 52 bits para 54 bits, como muitos projetos anteriores fazem, eles trabalham com a verdadeira mantissa efetiva de 53 bits, evitando bits “ociosos” que consomem armazenamento e fiação extras no chip. O coração do projeto é um multiplicador védico de 53 bits baseado em Urdhva Tiryakbhyam, disposto em uma hierarquia de blocos construtores menores: unidades de 3 bits formam unidades de 6 bits, que constroem unidades de 12 bits, 13 bits, 26 bits e 52 bits, todas combinadas no estágio final de 53 bits. A arquitetura separa o trabalho em três fases principais — cálculo do sinal, adição e viés do expoente, e multiplicação da mantissa seguida de normalização — correspondendo ao padrão IEEE‑754 de ponto flutuante enquanto reduz circuitos redundantes.
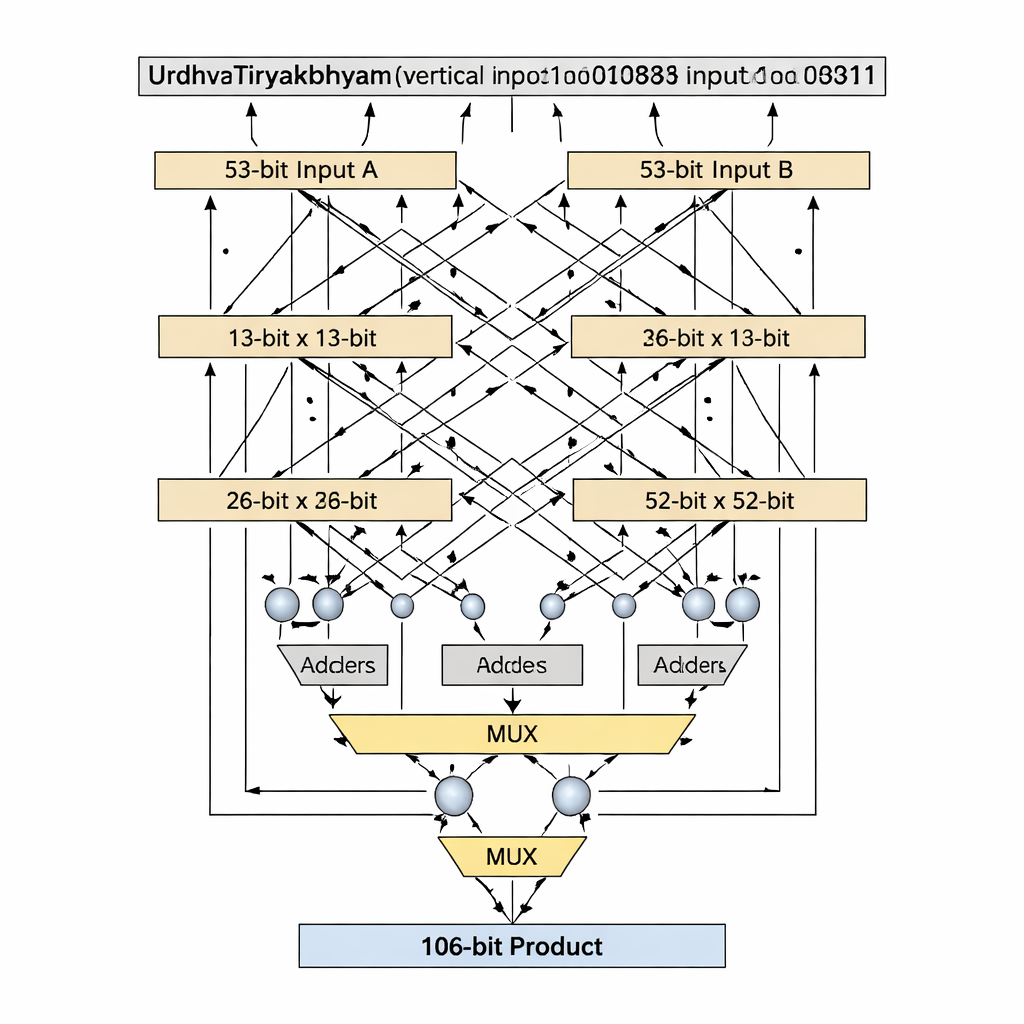
Blocos de tamanho primo para um hardware mais limpo
Uma inovação chave é como o projeto trata larguras de bits que são números primos, como 13 e 53, que não se dividem igualmente em blocos do mesmo tamanho. Decomposições védicas padrão assumem entradas divididas uniformemente, mas isso se torna desconfortável ou desperdiçador para comprimentos primos. Os autores introduzem um algoritmo de “bit primo” que reutiliza inteligentemente um multiplicador védico menor de (n−1) bits, mais somadores, multiplexadores e uma única porta lógica extra, para emular um multiplicador de n bits sem preenchimento. Para o estágio de 13 bits, as entradas são divididas em seções de 1 bit e 12 bits; produtos parciais são criados usando um multiplicador védico de 12 bits, seleção condicional (por multiplexadores) com base nos bits mais significativos e um pequeno número de somadores. O mesmo padrão escala para 53 bits com um núcleo de 52 bits. Essa decomposição sob medida encurta o caminho crítico — a cadeia mais longa de lógica que um sinal deve percorrer — enquanto mantém baixo o número de elementos lógicos.
Ganho medido em velocidade, tamanho e consumo
O projeto foi descrito em Verilog e implementado em um FPGA Xilinx Zynq usando as ferramentas Vivado. Entre multiplicadores védicos de 13, 26, 52, 53 e 64 bits, a unidade proposta de 53 bits mostra um equilíbrio favorável entre atraso, uso de lógica (tabelas de busca e pinos de E/S) e potência estimada. Em comparação com multiplicadores de dupla precisão anteriores baseados em Booth, Karatsuba e outros arranjos védicos, a nova arquitetura reduz significativamente o atraso no pior caso e a quantidade de recursos FPGA necessários, sem aumentar a complexidade do circuito de ponto flutuante circundante. Como a multiplicação da mantissa é mais rápida e a profundidade lógica é menor, a atividade de comutação é reduzida, o que aponta para um produto potência‑atraso melhor mesmo que comparações diretas de potência entre tecnologias sejam difíceis de fazer.
Impactos na IA e no processamento de sinais
Para testar o projeto em uma carga de trabalho real, os autores integraram seu multiplicador védico de dupla precisão no motor de convolução de uma Rede Neural Convolucional, onde operações de multiplicar‑e‑acumular dominam o tempo de execução. Substituir multiplicadores convencionais IEEE‑754 e védicos anteriores pelo novo projeto reduziu o atraso da convolução, diminuiu o consumo de energia e reduziu o tempo de inferência, tudo isso mantendo a mesma acurácia de classificação. Vantagens similares são esperadas em outras tarefas intensivas em computação, como filtragem digital, detecção de bordas e fluxos de processamento de imagens médicas, onde multiplicadores mais rápidos aumentam diretamente a vazão e podem permitir que dispositivos operem mais frios ou com baterias menores.
O que isso significa para a tecnologia do dia a dia
Em termos simples, o artigo mostra que tomar emprestada uma ideia engenhosa de multiplicação da matemática védica e alinhá‑la cuidadosamente aos formatos binários modernos pode gerar um multiplicador menor, mais rápido e mais eficiente em energia do que projetos padrão. Esse bloco de construção aprimorado pode ser incorporado a processadores, chips de processamento de sinais e aceleradores de IA, levando a análises de dados mais rápidas, dispositivos mais responsivos e potencialmente menor consumo de energia em sistemas que vão de smartphones a scanners médicos. Os autores também apontam direções futuras, incluindo lógica reversível para uso de energia ainda menor e integração em unidades de processamento maiores, sugerindo que essa união entre aritmética antiga e hardware moderno está apenas começando.
Citação: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Palavras-chave: Multiplicador védico, Aritmética de ponto flutuante, Projeto em FPGA, Processamento digital de sinais, Redes neurais convolucionais