Clear Sky Science · pt
Aplicação de redes neurais profundas baseadas em enxame e modelos ensemble para reconstrução de dados de condutividade específica
Por que preencher lacunas de dados é importante
As águas costeiras são a linha de frente onde a atividade humana encontra o oceano. Cientistas monitoram a salinidade dessas águas por meio de uma medida chamada condutividade específica, que ajuda a revelar vazamentos de poluentes, mudanças no fluxo de águas doces e tendências ambientais de longo prazo. Mas sensores falham, tempestades cortam a energia e instrumentos têm limitações. O resultado são lacunas frustrantes em registros-chave — exatamente quando gestores e pesquisadores mais precisam de dados contínuos. Este estudo coloca uma pergunta prática: a inteligência artificial moderna pode "consertar" esses registros quebrados de forma confiável para que decisões costeiras se baseiem em informações completas e dignas de confiança?
Observando o sopro do Golfo
Os pesquisadores focaram no Golfo do México, um dos maiores ecossistemas marinhos do mundo e uma região sob forte pressão industrial e agrícola. Usaram medições de cinco estações do U.S. Geological Survey próximas ao rio Pascagoula e ao Mullet Lake, cada uma registrando a salinidade (por condutividade específica), temperatura e nível da água a cada 15 minutos. Uma estação, chamada E, tinha cerca de 5% dos dados de condutividade específica faltando — exatamente o tipo de problema que confronta redes de monitoramento do mundo real. Dados das quatro estações vizinhas formavam uma espécie de rede de segurança ambiental: mesmo quando a estação E ficava às cegas, as demais continuavam observando. A ideia central foi ensinar modelos computacionais a aprender como as cinco estações "respiram" em conjunto para que lacunas em um ponto pudessem ser inferidas a partir de registros completos nas outras.
Colocando algoritmos inteligentes à prova
Para enfrentar o problema, a equipe reuniu um conjunto de dez abordagens de modelagem diferentes. Em uma extremidade estavam ferramentas familiares, como regressão linear múltipla, que tentam traçar relações em linha reta entre entradas e saídas. No meio havia modelos mais flexíveis, como redes neurais clássicas, sistemas de lógica fuzzy e uma rede LSTM (long short‑term memory) especialmente usada para dados temporais. Também usaram um método auto‑organizador chamado group method of data handling (GMDH) e uma variante não linear (NGMDH) que pode construir fórmulas em múltiplas camadas por conta própria. Por fim, incluíram métodos baseados em árvores: um modelo de árvore de decisão única (CART) e duas abordagens "ensemble" — Random Forest e XGBoost — que combinam muitas árvores para tomar uma decisão final, como um painel de especialistas votando numa resposta.
Aprendizado profundo impulsionado por enxame
Treinar redes neurais profundas é notoriamente complicado: seus muitos botões e parâmetros podem facilmente ficar presos em configurações ruins. Para melhorá‑las, os autores emparelharam LSTM e NGMDH com um método de otimização recente inspirado em água turbulenta, chamado turbulent flow of water‑based optimization (TFWO). Nesse esquema, cada possível conjunto de parâmetros do modelo é imaginado como uma "partícula" movendo‑se em um padrão tipo redemoinho pelo espaço de todas as soluções. Ao longo de muitos ciclos, as partículas são empurradas em direção a regiões que produzem erros de predição menores. Essa busca em estilo enxame tornou ambos os tipos de redes neurais sensivelmente mais precisos que suas versões padrão, reduzindo seus erros médios em cerca de 6–11%. Ainda assim, mesmo esses modelos profundos aprimorados foram, em última análise, superados pelas abordagens baseadas em árvores.
Ensembles assumem a liderança
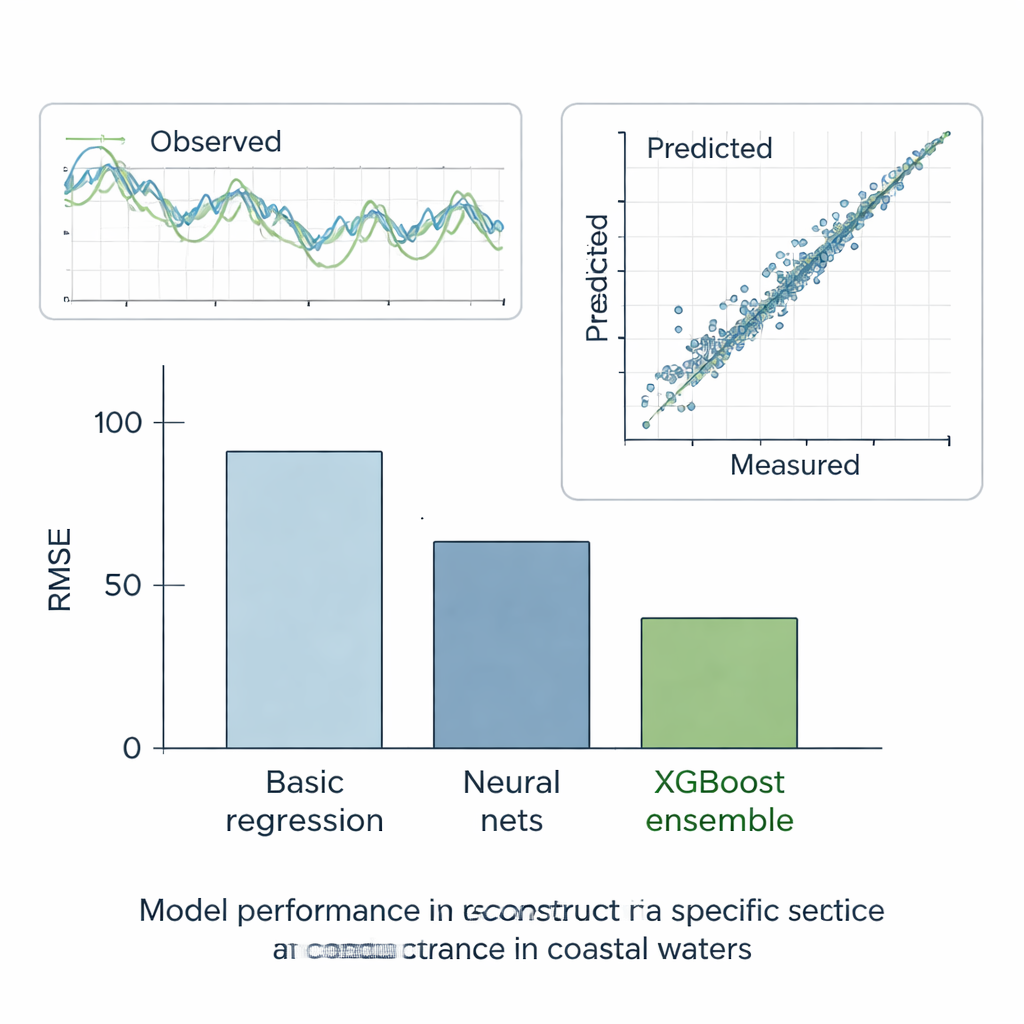
Os autores testaram rigorosamente todos os métodos em seis cenários. Em cinco casos "e se", ocultaram trechos de registros por outra forma completos e verificaram quão bem cada modelo podia reconstruir os valores faltantes. No caso final, do mundo real, pediram aos modelos que preenchessem as lacunas reais na estação E usando os dados das vizinhas. Ao longo desses testes, o método mais simples de linha reta apresentou o pior desempenho, enquanto modelos padrão de aprendizado de máquina se saíram muito melhor, reduzindo o erro aproximadamente pela metade. Árvores de decisão, que automaticamente dividem os dados em grupos mais homogêneos, melhoraram ainda mais. Mas o claro vencedor foi o ensemble XGBoost: ao construir centenas de árvores que corrigem os erros das anteriores, alcançou erro extremamente baixo e uma correspondência quase perfeita entre a condutividade específica prevista e a medida. Suas reconstruções seguiram de perto as séries temporais observadas e reproduziram o comportamento estatístico geral dos registros de qualidade da água.
O que isso significa para as zonas costeiras e além
Para não especialistas, a mensagem principal é direta: IA bem projetada pode preencher de forma confiável as peças faltantes de registros de qualidade da água costeira, especialmente quando estações vizinhas fornecem contexto. Embora redes neurais avançadas sejam poderosas, este estudo mostra que métodos ensemble baseados em árvores como o XGBoost são ainda mais precisos e, na prática, podem ser a melhor escolha para reparar conjuntos de dados ambientais. Com ferramentas robustas de preenchimento de lacunas, cientistas podem acompanhar melhor mudanças sutis na salinidade costeira, identificar eventos de poluição e apoiar decisões de gestão sem serem prejudicados por falhas inevitáveis de sensores. As mesmas estratégias podem ser adaptadas a muitos outros problemas de engenharia e ambientais em que fluxos de dados são ricos, ruidosos e ocasionalmente incompletos.
Citação: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Palavras-chave: qualidade da água costeira, condutividade específica, aprendizado de máquina, reconstrução de dados ausentes, XGBoost