Clear Sky Science · pt
A construção e as técnicas refinadas de extração de grafos de conhecimento com base em grandes modelos de linguagem
Mapas mais inteligentes para decisões complexas
Decisões modernas em áreas de alto risco — como operações em grande escala, gestão de infraestrutura ou resposta a desastres — dependem de interpretar rapidamente enormes quantidades de informação fragmentada. Manuais, fluxos de sensores, relatórios e simulações contam partes da história, mas raramente estão organizados de forma que humanos ou computadores possam usar facilmente. Este artigo apresenta um método para transformar essa informação fragmentada em “mapas do conhecimento” vivos alimentados por grandes modelos de linguagem, para que planejadores e analistas possam fazer melhores perguntas e obter respostas mais rápidas e confiáveis.
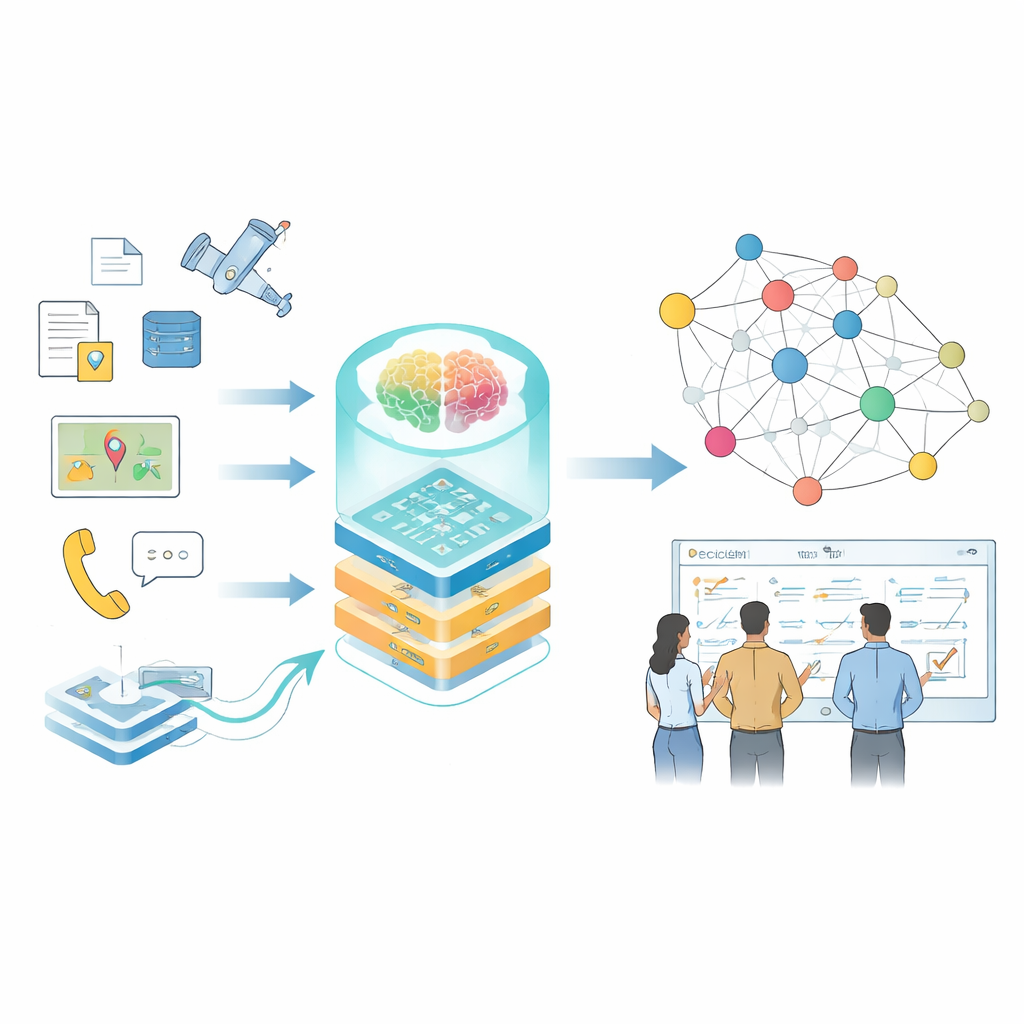
De fatos dispersos a conhecimento conectado
Os autores se concentram em grafos de conhecimento, uma forma de representar informação como uma teia de fatos conectados — quem fez o quê, com qual sistema, sob quais condições. Em contextos cotidianos, esses grafos já alimentam mecanismos de busca e sistemas de recomendação, mas domínios especializados apresentam problemas mais difíceis: os dados são sensíveis, a terminologia é densa, os formatos variam de relatórios em texto livre a registros de sensores, e as condições mudam rapidamente. Ferramentas tradicionais que dependem de regras escritas à mão ou modelos pequenos têm dificuldade de acompanhar, e modelos de linguagem de uso geral frequentemente interpretam mal termos técnicos ou deixam passar relações sutis que importam para decisões do mundo real.
Ensinando uma nova especialidade aos grandes modelos de linguagem
Para tratar disso, o estudo ajusta finamente um modelo de linguagem base poderoso com um conjunto de dados específico e cuidadosamente projetado para o domínio. O conjunto de dados se apoia em comunicações de comando, manuais de equipamentos, cenários simulados e literatura especializada. Antes que esse material alcance o modelo, ele é fortemente dessensibilizado: coordenadas concretas tornam‑se localizações relativas, nomes de unidades viram códigos genéricos e lógicas sensíveis são parcialmente mascaradas preservando padrões gerais. Os dados são armazenados em um formato estruturado que descreve a situação mais ampla, as tarefas específicas (como planejamento, classificação de ameaças ou resposta a perguntas) e os vínculos entre elas. Essa estrutura permite que o modelo aprenda não apenas fatos isolados, mas também como diferentes tarefas compartilham contexto.
Camadas de adaptação para tarefas diferentes
Em vez de retreinar todos os parâmetros do modelo de linguagem — um processo caro e arriscado — os autores usam uma técnica chamada adaptação de baixa ordem (low‑rank adaptation), organizada em várias camadas que se concentram em aspectos distintos do problema. Uma camada captura terminologia e conceitos básicos, outra embute regras e restrições operacionais, e uma terceira se especializa em adaptar‑se a tarefas particulares, como planejamento ou avaliação de ameaças. Um componente de controle separado, a rede de “roteamento”, analisa cada entrada e decide qual combinação desses adaptadores leves o modelo deve usar. Esse desenho permite que o sistema troque de tarefa de forma eficiente, preservando tanto a habilidade linguística geral quanto a especialização no domínio.
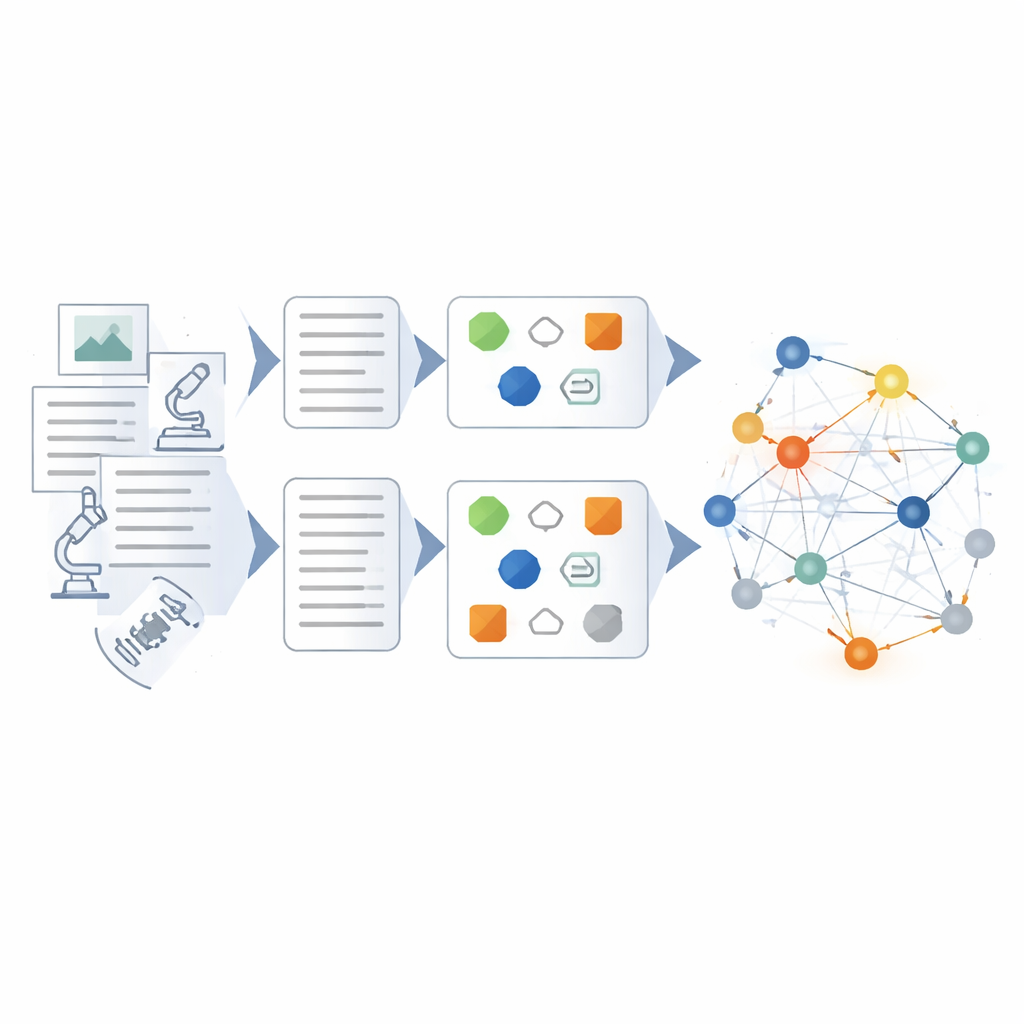
Construindo e verificando a teia do conhecimento
Sobre o modelo ajustado, os autores projetam um fluxo híbrido para construir o próprio grafo de conhecimento. Primeiro, os dados brutos são limpos e padronizados para que termos e formatos fiquem consistentes. Em seguida, métodos baseados em regras e templates elaborados por especialistas extraem entidades e eventos óbvios. O modelo de linguagem afinado intervém para lidar com trabalhos mais complexos: resumir relatórios confusos em sínteses concisas, identificar atores e equipamentos-chave e inferir relações como cadeias de causa e efeito ou coordenação entre unidades. Cada fato extraído é pontuado sob vários ângulos — quão bem se encaixa em padrões conhecidos, quão fortemente se conecta a outros fatos e se alinha a caminhos de raciocínio em vários passos através do grafo. Apenas resultados de alta confiança são adicionados, e os de baixa confiança são sinalizados para revisão.
Ganho comprovado em precisão e confiabilidade
A equipe avalia sua abordagem em três tarefas centrais que refletem necessidades do mundo real: responder a perguntas complexas sobre regras e equipamentos, propor planos de ação para situações dadas e classificar diferentes cenários de ameaça por gravidade. Nessas tarefas, o modelo adaptado supera consistentemente sistemas gerais bem conhecidos, incluindo modelos de ponta com treinamento muito mais genérico. Ele responde mais perguntas corretamente, produz planos mais realistas e classifica ameaças com maior precisão. O grafo de conhecimento resultante é tanto grande quanto altamente conectado, com mais de 90% dos fatos armazenados passando em rigorosas verificações de confiança e ajudando planejadores a tomar decisões sólidas mais rapidamente.
Por que isso importa daqui para frente
Para o leitor leigo, a mensagem principal é que modelos de linguagem podem deixar de ser apenas bons oradores e virar analistas cuidadosos e especializados — se forem treinados com os dados certos, restritos por regras claras e constantemente verificados quanto à qualidade. Este trabalho mostra como fazer isso em um domínio sensível e de rápida mudança, protegendo informações privadas. A estrutura não só organiza conhecimento disperso em uma teia utilizável, como também mantém essa teia atualizada e confiável, oferecendo um roteiro para futuros sistemas de suporte à decisão em qualquer área onde acertar decisões complexas realmente importe.
Citação: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Palavras-chave: grafo de conhecimento, grande modelo de linguagem, suporte à decisão, adaptação ao domínio, dessensibilização de dados