Clear Sky Science · pt
Gerando amostras limítrofes para testadores de aleatoriedade via otimização inteligente e algoritmos evolutivos
Por que o quase‑aleatório importa para a segurança cotidiana
Cada vez que você faz compras online, desbloqueia seu telefone ou envia uma mensagem privada, dados matemáticos invisíveis estão sendo sorteados para manter suas informações seguras. Esses dados aparecem como longas sequências de bits supostamente aleatórios usadas como chaves criptográficas. Se esses bits forem mesmo um pouco menos aleatórios do que deveriam, agentes determinados às vezes conseguem encontrar padrões para explorar. Este artigo explora uma nova maneira de fabricar sequências de teste “quase‑aleatórias” — dados que parecem extremamente aleatórios, mas escondem pequenas falhas — para que engenheiros possam submeter seriamente a prova os dispositivos que protegem nossa vida digital.
Quando números aleatórios não são suficientemente aleatórios
Sistemas de segurança modernos dependem de dois tipos de geradores de números aleatórios. Geradores verdadeiramente aleatórios extraem efeitos físicos imprevisíveis, como ruído eletrônico ou flutuações quânticas, enquanto geradores pseudoaleatórios usam algoritmos que transformam sementes curtas e aleatórias em sequências longas. Na prática, a qualidade de ambos depende, em última instância, da fonte física de imprevisibilidade, chamada fonte de entropia. Infelizmente, fontes de entropia reais são frágeis: variações de temperatura, envelhecimento do hardware ou erros de projeto podem reduzir silenciosamente sua aleatoriedade. Para detectar esses problemas, órgãos normativos como o NIST definem baterias de testes estatísticos que verificam se os bits de saída parecem suficientemente aleatórios. Dispositivos cada vez mais incorporam “testadores de aleatoriedade em tempo real” que monitoram sua própria saída enquanto funcionam. Ainda assim, não havia uma boa forma de gerar casos de falha realistas e difíceis de detectar para testar se esses verificadores embarcados realmente funcionam.
Projetando sequências que quase falham nos testes de aleatoriedade
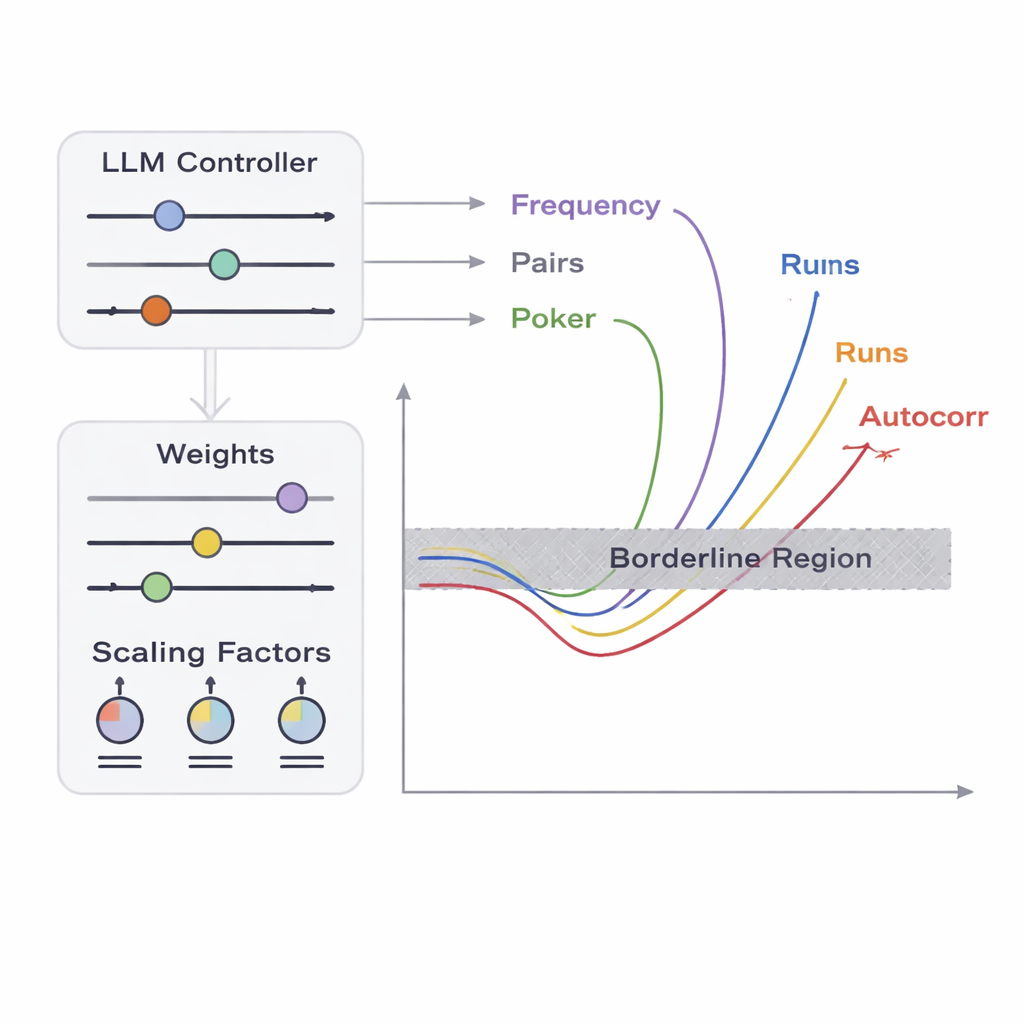
Do ponto de vista de um testador, falhas triviais — como saídas compostas só por zeros — são fáceis de identificar. O desafio real é detectar casos limítrofes: sequências quase indistinguíveis da aleatoriedade ideal, mas que falham por pouco em um ou mais testes estatísticos. Os autores enfocam cinco testes clássicos que analisam diferentes aspectos dos padrões de bits, incluindo a frequência de zeros e uns, o comportamento de pares de bits, a distribuição de certos padrões curtos, a correlação de bits com cópias deslocadas de si mesmos e a distribuição de comprimentos de corridas de bits idênticos. Eles definem uma “zona limítrofe” para cada teste: uma faixa estreita onde os dados apenas violam ligeiramente os limiares usuais de aceitação. Produzir uma sequência longa que caia simultaneamente dentro de todas essas faixas estreitas é extremamente improvável por acaso, porque os testes interagem de maneira complicada e não linear. É aí que entram a otimização e a IA.
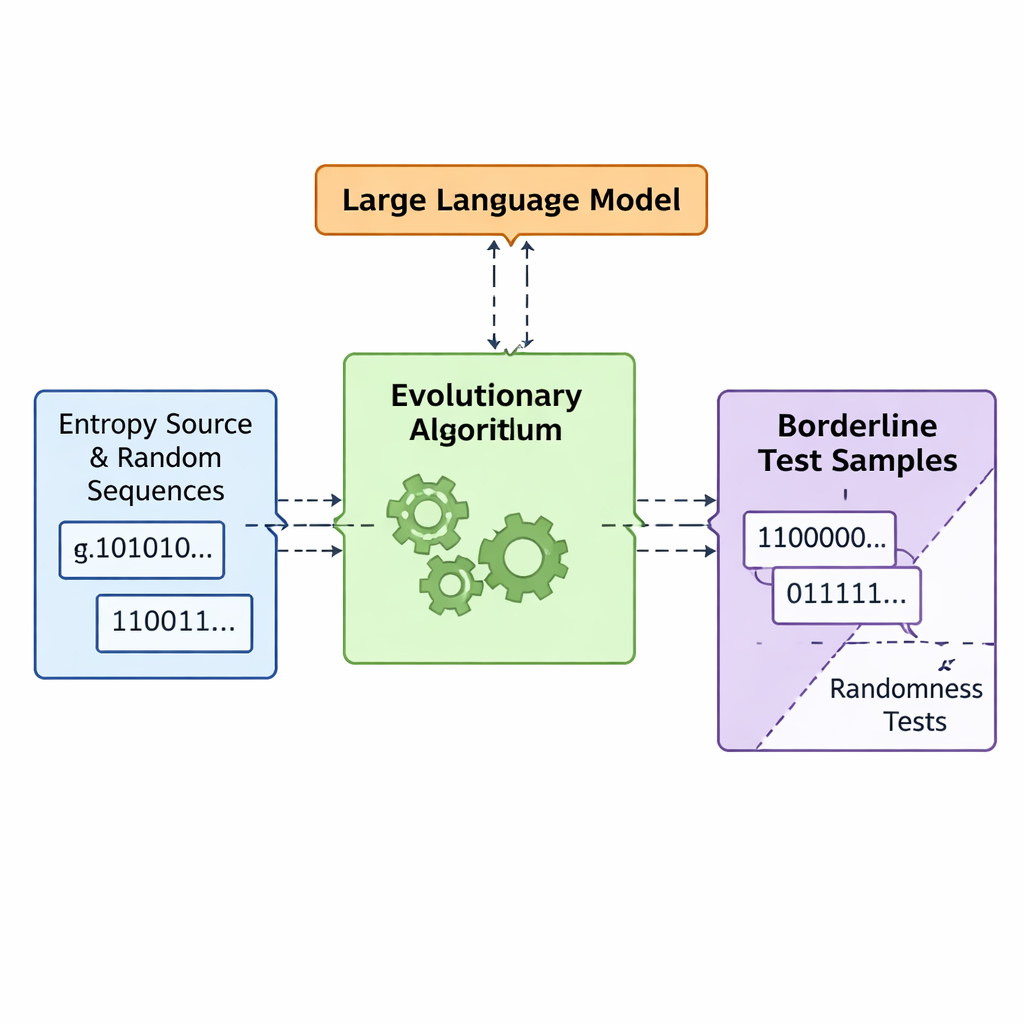
Deixe a evolução e modelos de linguagem co‑projetarem aleatoriedade defeituosa
A equipe apresenta um framework chamado APAM‑IGLLM que trata a geração de sequências como um problema de otimização de alta dimensionalidade. Cada sequência candidata é uma string de bits, e sua “aptidão” mede quão perto ela chega das zonas limítrofes dos cinco testes. Um algoritmo genético muta e recombina repetidamente essas sequências, mantendo aquelas que se aproximam da região alvo. Sobre isso, um grande modelo de linguagem (LLM) atua como uma espécie de treinador estratégico. A cada geração ele examina estatísticas resumidas da população e o histórico de curto prazo, então sugere ajustes em controles internos — pesos e fatores de escala que decidem o quanto cada teste influencia a aptidão. Isso cria um loop de feedback: o algoritmo genético explora o espaço de sequências possíveis, enquanto o LLM orienta a busca para que as cinco pontuações de teste convirjam para a interseção minúscula onde as sequências são apenas marginalmente não aleatórias.
Quão próximas da aleatoriedade perfeita dados falhos podem parecer?
Para verificar se suas falhas artificiais parecem realistas, os autores comparam suas sequências geradas com benchmarks amplamente usados. Eles calculam tanto a entropia de Shannon quanto a min‑entropia, medidas de quão imprevisível cada byte aparenta ser, e encontram valores em torno de 7,6–8 bits por byte — muito próximos do máximo teórico de 8 e semelhantes a fontes comerciais de aleatoriedade por hardware e ao próprio beacon público de aleatoriedade do NIST. Também executam a suíte completa de testes estatísticos NIST SP 800‑22 e observam que suas sequências limítrofes passam e falham em um padrão quase idêntico ao de dados verdadeiramente aleatórios de alta qualidade. Em outras palavras, para ferramentas padrão essas amostras parecem essencialmente normais, embora tenham sido deliberadamente projetadas para ficar próximas a múltiplos limiares de falha. Isso as torna entradas “adversariais” ideais para verificar quão robustos são os testadores de aleatoriedade embarcados.
O que isso significa para a segurança no mundo real
Do ponto de vista do público geral, este trabalho oferece uma nova forma de checar a segurança das máquinas de números aleatórios que sustentam a criptografia. Em vez de testar dispositivos apenas com aleatoriedade claramente falha ou claramente saudável, os engenheiros agora podem sobrecarregá‑los com sequências cuidadosamente criadas e quase corretas que imitam falhas sutis de hardware ou deriva ambiental. Se um testador de aleatoriedade em tempo real perder esses casos limítrofes, isso indica um possível ponto cego que deve ser corrigido antes que o dispositivo seja usado em bancos, comunicações seguras ou sistemas de blockchain. Ao usar busca evolucionária guiada por um modelo de linguagem, os autores fornecem uma ferramenta prática para gerar esses dados de teste exigentes, ajudando a elevar os alicerces ocultos da segurança digital para níveis maiores de confiabilidade.
Citação: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Palavras-chave: geradores de números aleatórios, fontes de entropia, algoritmos evolutivos, modelos de linguagem de grande porte, testes criptográficos