Clear Sky Science · pt
Corrigindo rótulos ruidosos via destilação comparativa: uma abordagem de adaptação de domínio
Por que dados bagunçados são um problema crescente
A inteligência artificial moderna prospera com dados, mas esses dados frequentemente estão errados, incompletos ou rotulados de forma inconsistente. Quando os rótulos são ruidosos — por exemplo, uma foto de um gato marcada como cachorro — os sistemas de aprendizado podem ser enganados, tornando-se menos precisos e menos confiáveis. Este artigo aborda esse problema do mundo real: como treinar sistemas de reconhecimento de imagens que ainda funcionem bem mesmo quando os rótulos de treinamento são falhos e as imagens vêm de ambientes diferentes, como lojas online versus fotos do mundo real.
Aprendendo entre mundos diferentes
Na prática, modelos de IA frequentemente aprendem a partir de um “mundo fonte” onde os rótulos são cuidadosamente verificados e depois precisam atuar em um “mundo alvo” onde os rótulos são escassos e sujeitos a erros. Por exemplo, objetos de escritório fotografados em estúdio são bem organizados e rotulados corretamente, enquanto fotos por webcam ou do cotidiano dos mesmos objetos são bagunçadas e etiquetadas de forma inconsistente. Métodos tradicionais de adaptação de domínio tentam reduzir essa lacuna alinhando estatísticas globais dos dois mundos. Entretanto, eles geralmente supõem que os rótulos do alvo, quando disponíveis, estão corretos — uma suposição arriscada que se desfaz em aplicações reais com tags crowdsourced, sensores de baixa qualidade ou ferramentas de anotação automática.
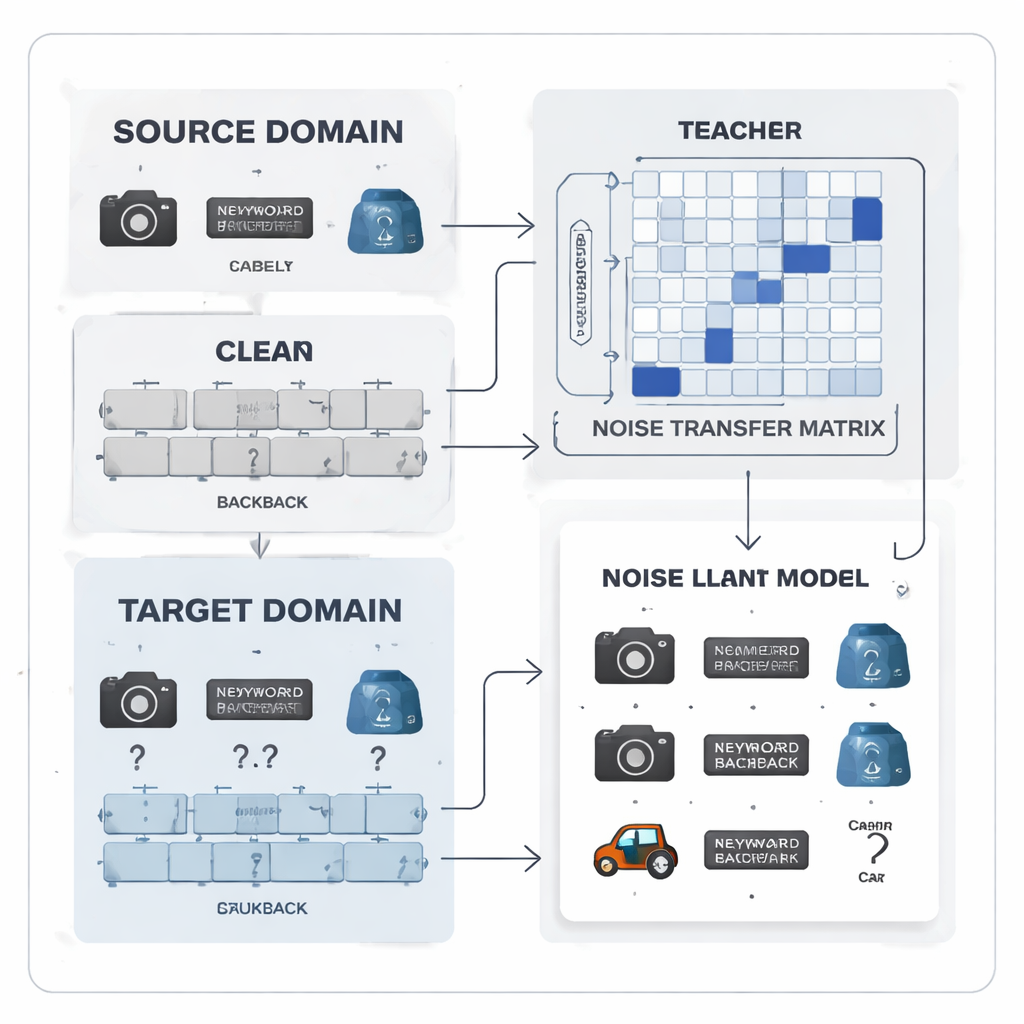
Transformando erros de rótulo em um padrão aprendível
Os autores propõem tratar o ruído nos rótulos não como caos aleatório, mas como um padrão aprendível. Eles introduzem uma “matriz de transferência de ruído”, uma tabela que captura quão provável é que cada classe verdadeira seja rotulada erroneamente como outra. Em vez de estimar essa tabela a partir de alguns exemplos perfeitos “âncora” — o que é irrealista quando os rótulos são ruidosos e as classes estão desequilibradas — a matriz é aprendida diretamente durante o treinamento. Para iniciar o aprendizado, o método constrói “protótipos” de categoria, impressões digitais médias de características para cada classe extraídas por um modelo pré-treinado forte. A similaridade entre esses protótipos é usada para inicializar a matriz, de modo que categorias confundíveis, como ferramentas de escritório semelhantes, fiquem mais fortemente conectadas desde o início, dando ao sistema uma capacidade inicial de corrigir rótulos.
Trabalho em equipe professor–aluno para sinais mais limpos
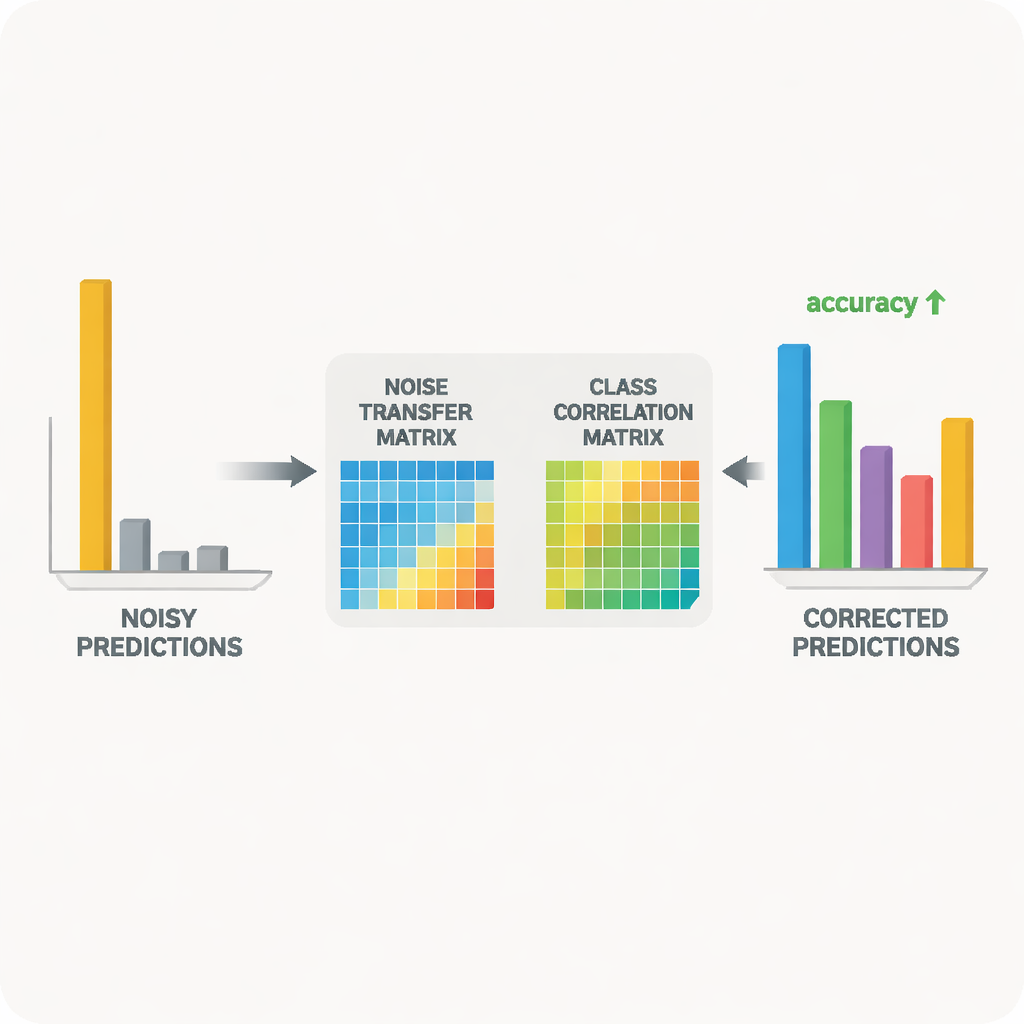
No centro do sistema está um par professor–aluno de redes neurais. O professor baseia-se em um grande modelo visual auto-supervisionado que aprendeu características visuais ricas a partir de enormes quantidades de dados não rotulados. O aluno é uma rede mais leve que deve ter bom desempenho nos dados alvo ruidosos. O professor produz scores de predição suaves que revelam o quão relacionadas as classes são; a partir desses scores, o método constrói uma matriz de correlação de classes que resume quais rótulos tendem a coocorrer. Essa matriz atua como um guia, orientando a matriz de transferência de ruído em direção a correções mais realistas. Ao mesmo tempo, o aluno é treinado para igualar o comportamento do professor por meio de um processo conhecido como destilação, enquanto o aprendizado contrastivo incentiva ambas as redes a fornecer representações internas semelhantes para diferentes vistas aumentadas da mesma imagem e representações distintas para objetos diferentes.
Mantendo as correções estáveis e evitando excesso de confiança
Permitir simplesmente que a matriz de transferência de ruído mude livremente pode torná-la instável ou excessivamente sensível a outliers. Para evitar isso, os autores usam um recurso matemático baseado na decomposição por valores singulares, que decompõe a matriz em direções básicas de alongamento. Ao penalizar o “volume” global implicado por essas direções, o método desencoraja distorções extremas que amplificariam o ruído. Outro problema surge quando o modelo fica excessivamente confiante, atribuindo quase toda a probabilidade a uma única classe; sob previsões tão pontiagudas, torna‑se difícil ajustar rótulos errados. Para contornar isso, o método adiciona uma forma de regularização de entropia, baseada na entropia de Tsallis, que mantém as probabilidades de predição mais suaves. Isso facilita que a matriz de transferência de ruído realoque parcialmente massa de probabilidade de uma classe incorreta para alternativas mais plausíveis.
Comprovando a ideia em coleções reais de imagens
Os pesquisadores testaram sua abordagem em dois benchmarks amplamente usados para reconhecimento de objetos entre domínios: Office‑31 e Office‑Home, que incluem imagens de itens de escritório comuns em múltiplos estilos, como fotos de produto, clip art e instantâneos do mundo real. Em uma variedade de tarefas “treinar em um estilo, testar em outro”, seu método igualou ou superou algoritmos líderes, especialmente nos casos mais difíceis em que o desvio entre domínios é maior. Estudos detalhados mostraram que cada componente — o controle de volume para a matriz de ruído, a orientação pela correlação de classes e o alisamento por entropia — contribuiu com ganhos mensuráveis. Visualizações da matriz aprendida e do espaço de características confirmaram que, ao longo do treinamento, exemplos mal rotulados foram gradualmente puxados para suas categorias corretas e que as distribuições de imagem fonte e alvo ficaram melhor alinhadas.
O que isso significa para sistemas de IA do dia a dia
Para um público não especialista, a principal conclusão é que este trabalho torna modelos de IA mais tolerantes a erros humanos e de máquinas na rotulação de dados, especialmente quando esses modelos precisam sair de condições limpas de laboratório para ambientes reais mais bagunçados. Ao aprender explicitamente como os rótulos tendem a errar e usar um modelo professor potente para guiar as correções, o método pode limpar sinais de treinamento ruidosos e produzir classificadores mais precisos e robustos. Embora a abordagem exija computação adicional, ela aponta para um futuro em que grandes conjuntos de dados imperfeitos coletados “na natureza” possam ser aproveitados de forma mais segura e eficaz, reduzindo nossa dependência de anotações manuais minuciosas.
Citação: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Palavras-chave: rótulos ruidosos, adaptação de domínio, destilação de conhecimento, classificação de imagens, aprendizado semi-supervisionado