Clear Sky Science · pt
Críticos distribuicionais gêmeos sensíveis ao risco com um limite inferior de confiança lambda para aprendizado por reforço em controle contínuo
Ensinando Robôs a Serem Cautelosos
Muitos dos robôs e programas de jogos mais impressionantes atualmente dependem do aprendizado por reforço, um processo de treinamento por tentativa e erro no qual agentes de software aprendem coletando recompensas. Mas esses agentes frequentemente perseguem a maior pontuação possível enquanto ignoram o quão arriscadas são suas decisões, levando a um aprendizado instável e a acidentes ocasionais. Este artigo introduz um método chamado TDC-λ (Críticos Distribucionais Gêmeos com um Limite Inferior de Confiança Lambda) que ensina esses agentes não apenas a mirar alto, mas também a manter-se confiavelmente seguros enquanto aprendem.
Por Que a Estabilidade Importa em Máquinas de Aprendizado
Algoritmos padrão de controle contínuo, como os amplamente usados TD3 e Soft Actor–Critic (SAC), permitiram que robôs corressem, saltassem e se equilibrassem em simuladores complexos. Entretanto, esses métodos tipicamente avaliam cada ação usando um único número: uma estimativa de quanto de recompensa ela trará a longo prazo. Essa pontuação simples pode ser enganosa quando o processo de aprendizado é ruidoso, fazendo o sistema superestimar quão boas certas ações realmente são. O resultado é uma curva de aprendizado que pode parecer forte em média, mas oscilar fortemente entre execuções, o que é problemático se o mesmo algoritmo tiver de controlar máquinas físicas ou sistemas críticos de segurança.
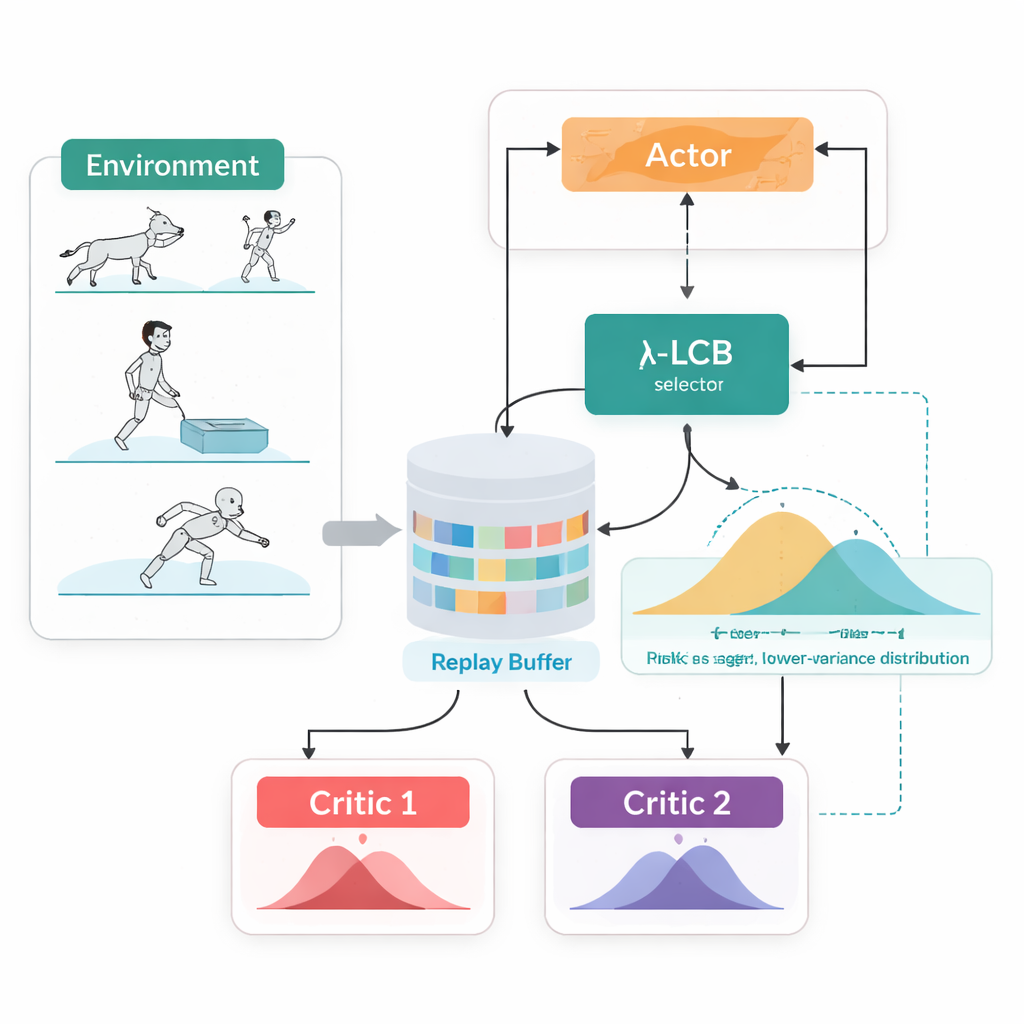
Olhando para Futuros Completos, Não para Números Únicos
O TDC-λ aborda esse problema mudando a forma como o agente avalia seu futuro. Em vez de prever apenas uma recompensa esperada para cada ação, ele aprende dois "críticos" separados que cada um produz uma distribuição completa sobre os possíveis retornos futuros. A partir dessas distribuições, o algoritmo calcula não apenas o resultado médio, mas também o grau de dispersão das possibilidades. Essa dispersão reflete incerteza ou risco. Usando uma regra simples, resumida como um limite inferior de confiança, o TDC-λ prefere o crítico que prevê um resultado mais seguro: aquele que pode ser ligeiramente menos otimista, mas é sustentado por evidências mais consistentes. Uma única configuração, o parâmetro de risco λ, ajusta suavemente quão cautelosa é essa seleção — desde comportar-se como um método convencional no estilo TD3 quando λ é zero até tornar-se mais conservador à medida que λ cresce.
Um Loop de Treinamento, Duas Formas de Agir
Outra característica prática do TDC-λ é que ele suporta tanto formas determinísticas quanto estocásticas de escolher ações dentro de um quadro unificado. Durante o treinamento, os usuários podem optar por uma política determinística clássica ou por uma política Gaussiana com tanh que amostra ações, promovendo exploração. Independentemente dessa escolha, os críticos distribuicionais gêmeos são treinados da mesma maneira, e a avaliação sempre usa a ação média determinística. Esse desenho aproveita descobertas anteriores de que um comportamento determinístico no teste muitas vezes tem desempenho tão bom quanto, ou melhor que, a amostragem, ao mesmo tempo em que permite políticas ricas e favoráveis à exploração durante o aprendizado.
Colocando o Método à Prova
Os autores avaliaram o TDC-λ em cinco tarefas populares de referência do MuJoCo, onde robôs simulados como HalfCheetah, Hopper, Ant, Walker2d e Humanoid devem aprender a se mover eficientemente. Nessas tarefas, o novo método igualou ou melhorou o desempenho final de linhas de base fortes, incluindo TD3, DDPG, SAC e uma abordagem avançada baseada em fluxo chamada MEOW, enquanto mostrava consistentemente menor variabilidade entre execuções repetidas. Em tarefas mais difíceis e de maior dimensão, como Humanoid, valores ligeiramente maiores de λ — indicando estimativas-alvo mais cautelosas — levaram aos melhores retornos de longo prazo e às bandas de desempenho mais estreitas. Experimentos adicionais em outros simuladores (PyBullet e NVIDIA Isaac) e diagnósticos que monitoram a variabilidade do sinal de aprendizado reforçaram a descoberta de que o TDC-λ torna o aprendizado mais estável sem torná-lo mais lento.
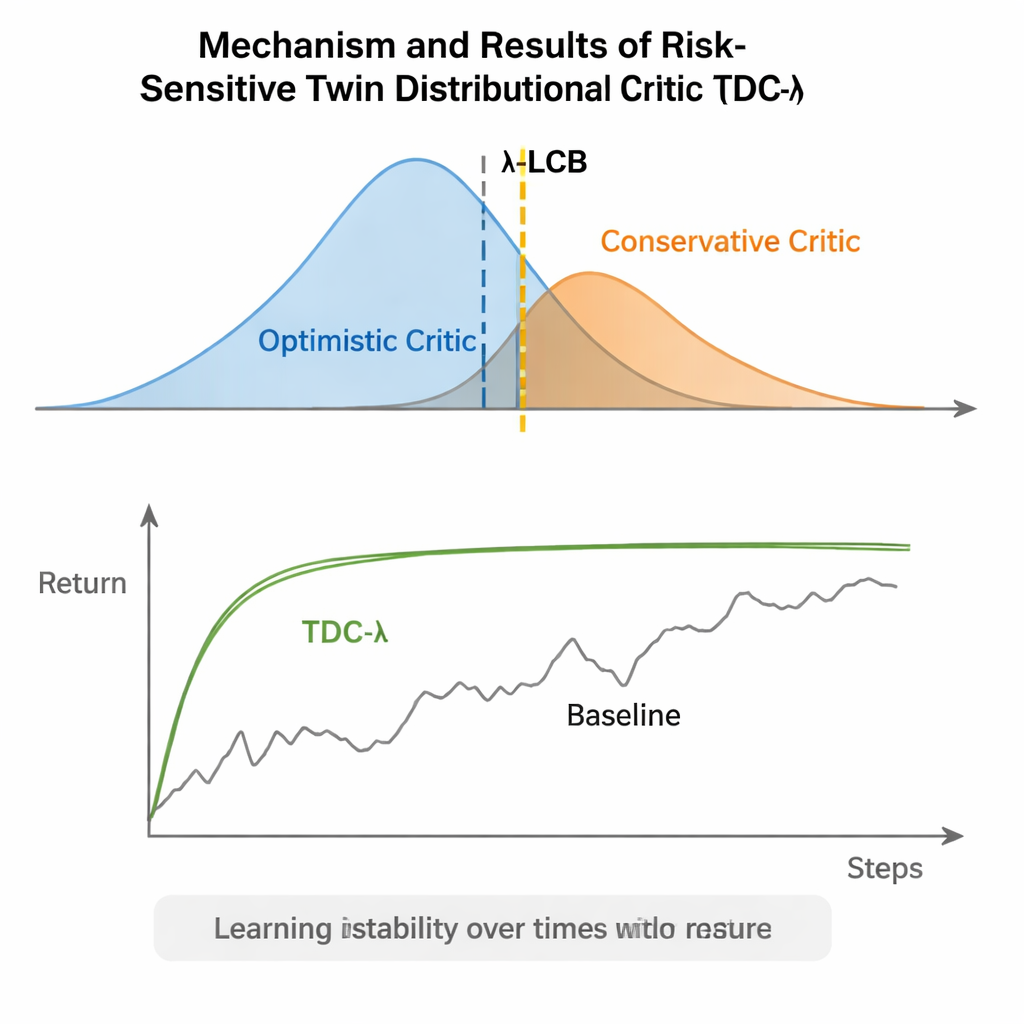
Um Botão Simples para um Aprendizado Mais Seguro
Em termos práticos, o TDC-λ dá aos sistemas de aprendizado por reforço uma "margem de segurança" ao decidir quanto confiar em seu próprio otimismo. Ao aprender distribuições completas de possíveis resultados e então inclinar-se para o crítico mais seguro usando o botão λ, o algoritmo reduz oscilações bruscas no treinamento enquanto preserva alto desempenho final. Para os praticantes, isso oferece uma maneira prática de construir controladores mais confiáveis para robôs e outros sistemas de controle contínuo: comece com um λ moderadamente conservador e ajuste-o com base em quão volátil o processo de aprendizado parece. A mensagem mais ampla é que moldar com cuidado aquilo a partir do que o agente aprende — seus alvos de treinamento — pode entregar grande parte da robustez frequentemente atribuída a arquiteturas mais complexas, tornando o aprendizado por reforço avançado mais estável e mais acessível.
Citação: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Palavras-chave: aprendizado por reforço, controle contínuo, aprendizado sensível ao risco, críticos distribuicionais, robótica