Clear Sky Science · pt
Um método leve baseado em YOLOv8n para detecção de posturas humanas anômalas
Por que identificar posturas corporais incomuns é importante
Quedas, dor súbita no peito ou alguém desabar em um corredor frequentemente acontecem em segundos e, se não houver ninguém por perto, a ajuda pode chegar tarde demais. Este artigo apresenta um sistema de inteligência artificial compacto que pode monitorar vídeos comuns de câmeras de segurança ou de lares de cuidado e sinalizar automaticamente posturas perigosas e anômalas em tempo real. Ao tornar o software ao mesmo tempo preciso e leve, os pesquisadores buscam levar detecção confiável de quedas e eventos de saúde a dispositivos do dia a dia, desde monitores hospitalares até câmeras de baixo custo em residências de idosos.
De câmeras simples a uma vigilância mais inteligente
Sistemas modernos de monitoramento já usam visão computacional para detectar pessoas e acompanhar seus movimentos, mas posturas incomuns são especialmente difíceis de identificar. Uma pessoa pode parecer muito diferente ao ficar em pé, segurar o peito, vomitar ou estar no chão; esses eventos são breves, variados e frequentemente parcialmente ocultos por móveis ou por iluminação ruim. Algoritmos existentes podem ser bastante precisos, mas costumam ser volumosos e lentos, exigindo hardware poderoso e ajuste cuidadoso. Os autores se concentram em tornar a detecção rápida e econômica em termos de recursos computacionais, de modo que possa rodar em placas gráficas comuns ou até em dispositivos embarcados, sem sacrificar a confiabilidade.
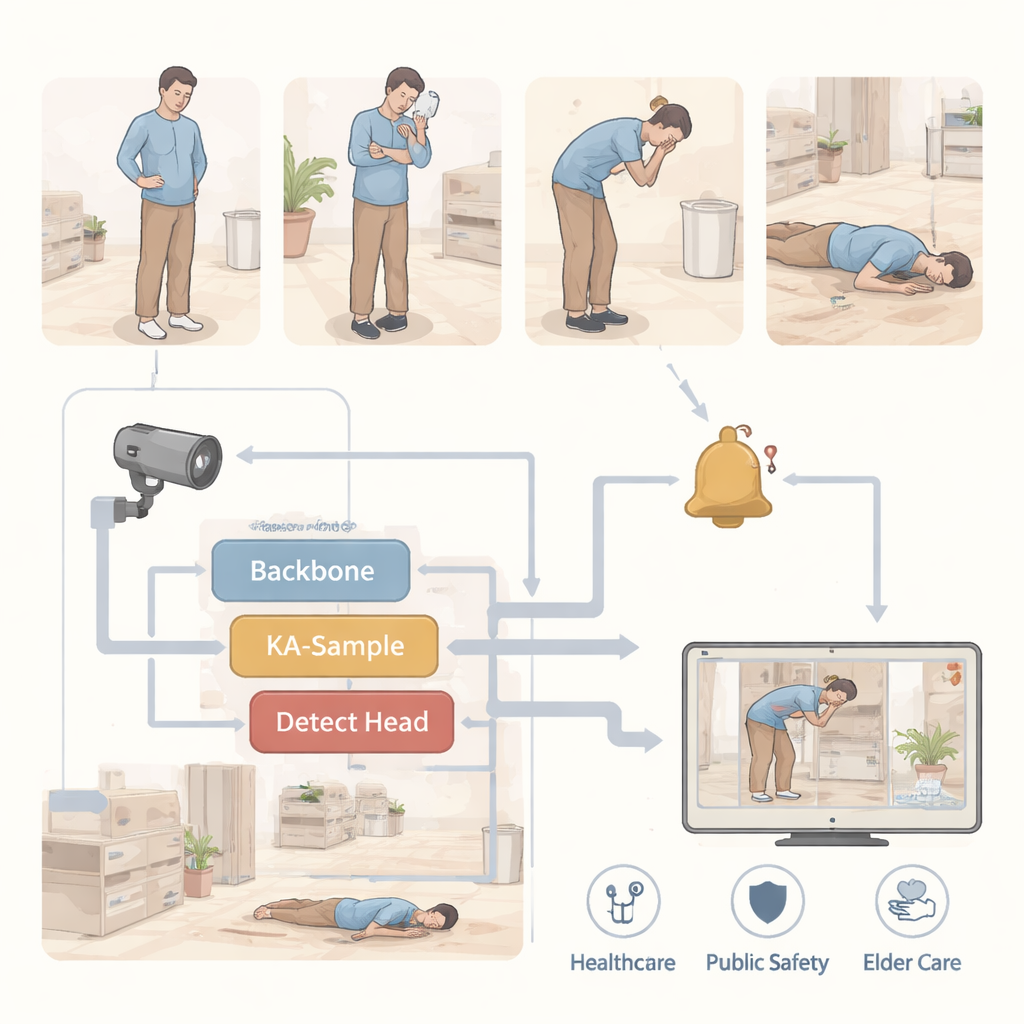
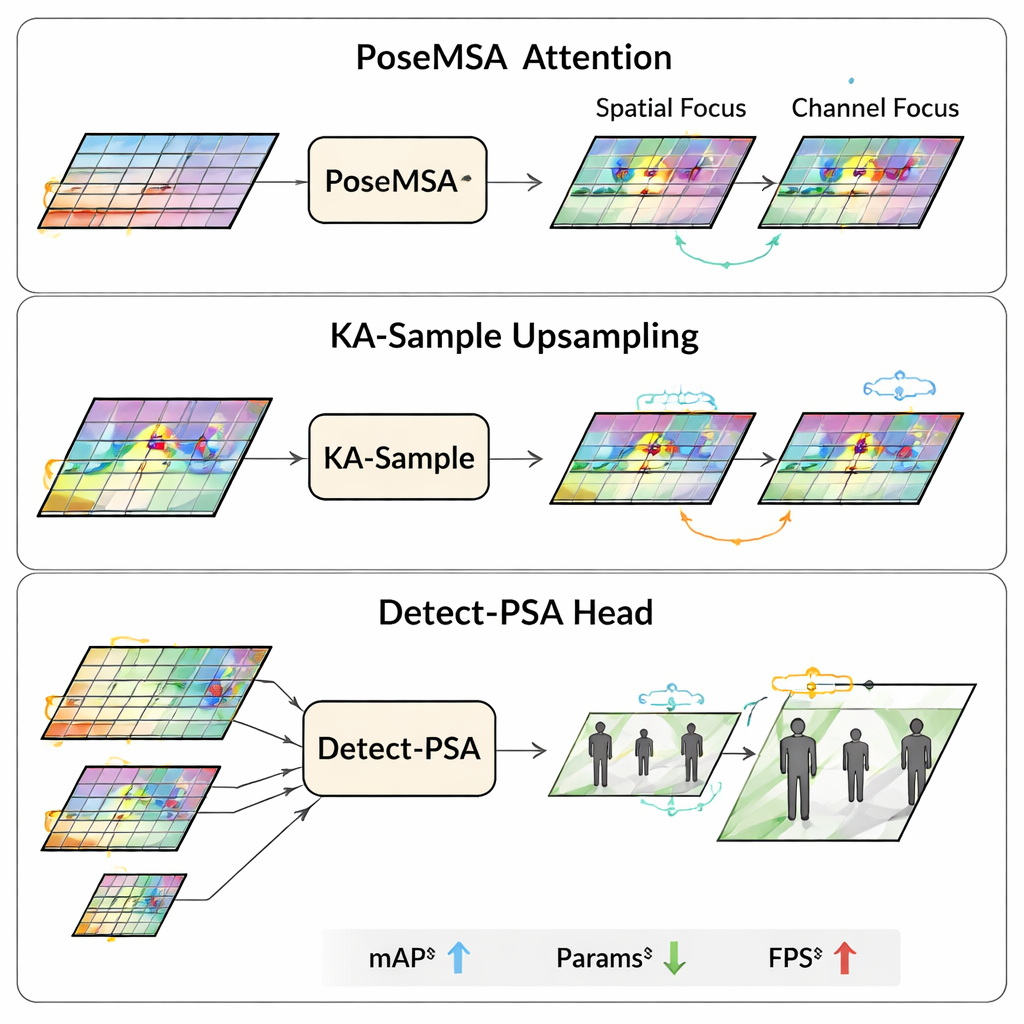
Um cérebro mais enxuto para reconhecer posturas de risco
O núcleo do trabalho é uma versão aprimorada de um modelo popular de detecção de objetos chamado YOLOv8n. Os pesquisadores constroem uma variante mais leve e focada que chamam de PSD‑YOLOv8n. Primeiro, eles adicionam um novo módulo de atenção, o PoseMSA, que ajuda a rede a se concentrar nas partes mais informativas do corpo da pessoa enquanto ignora fundos confusos. Isso é feito com operações enxutas que imitam olhar tanto através da imagem quanto pelas diferentes camadas de recursos, reforçando os sinais relevantes para a postura e mantendo baixo o número de cálculos. Em segundo lugar, eles redesenham como o modelo “aprofundara” detalhes usando um bloco de upsampling chamado KA‑Sample, que aprende a aguçar áreas ao redor de pontos corporais chave — como cabeça, torso e membros — para que posturas torcidas ou colapsadas se destaquem com mais clareza.
Caixas mais nítidas e decisões mais claras
Reconhecendo que posturas anômalas frequentemente se confundem com o entorno — pense em uma pessoa estendida parcialmente sob uma mesa — os autores também reformulam a etapa final de decisão, conhecida como detection head. O módulo Detect‑PSA deles combina informações de múltiplas escalas e aplica uma forma baseada em probabilidade de desenhar caixas delimitadoras. Em vez de estimar uma borda rígida única para onde começa e termina uma pessoa, o sistema representa cada lado da caixa como uma pequena distribuição de posições prováveis e depois faz uma média. Essa abordagem torna os contornos mais estáveis quando membros estão em perspectiva, ocluídos ou esticados no chão, produzindo caixas que se aproximam mais do ground truth desenhado por humanos em cenas desafiadoras.
Colocando o sistema à prova
Para avaliar o desempenho do projeto na prática, a equipe criou uma coleção de imagens dedicada, o SSHDataset, construída a partir de vídeos internos em múltiplos ângulos mostrando pessoas em quatro estados: normal, dor no peito, vômito e queda. Após rotulagem manual cuidadosa e aumento de dados, eles treinaram o PSD‑YOLOv8n e uma série de modelos concorrentes sob configurações idênticas. Em medidas padrão de precisão, seu método alcançou uma pontuação de detecção de 97,8% com um limiar de sobreposição comum e manteve desempenho sólido mesmo sob critérios mais rigorosos. Ao mesmo tempo, utilizou cerca de dois milhões de parâmetros e um arquivo de pesos de 4,5 megabytes — aproximadamente um terço a menos de parâmetros e mais de um terço menos de cálculo que o YOLOv8n original — enquanto rodava a mais de 80 quadros por segundo. Testes em um conjunto de dados público independente de detecção de quedas mostraram que os ganhos se mantiveram em novos dados, com melhorias particularmente fortes na identificação de quedas reais.
O que isso significa para a segurança do dia a dia
Em termos simples, o estudo entrega um “salva‑vidas” digital compacto que pode monitorar vídeo ao vivo e perceber de maneira confiável quando a posição corporal de alguém indica perigo. Ao reformular cuidadosamente como o modelo foca em regiões do corpo, reconstrói detalhes finos e desenha caixas ao redor das pessoas, os autores alcançam uma combinação rara de alta precisão, velocidade e tamanho reduzido. Tal sistema poderia ser incorporado a monitores hospitalares, hubs domésticos inteligentes ou câmeras em espaços públicos para disparar alertas oportunos sobre quedas ou sofrimento súbito, mesmo em ambientes com objetos e iluminação variada. À medida que a abordagem for refinada e estendida para sequências de vídeo mais longas e novos ambientes, ela pode sustentar uma nova geração de guardiões discretos e sempre ativos que ajudam a manter pessoas vulneráveis mais seguras sem exigir supervisão humana constante.
Citação: Li, G., Zhang, J., Ji, Q. et al. A lightweight YOLOv8n-based method for human abnormal posture detection. Sci Rep 16, 7222 (2026). https://doi.org/10.1038/s41598-026-37903-2
Palavras-chave: detecção de quedas, postura humana, visão computacional, IA leve, cuidados com idosos