Clear Sky Science · pt
Modelo de previsão da qualidade do ar baseado em uma estrutura híbrida de deep learning
Por que previsões de ar mais limpo importam para você
Quando o smog cobre uma cidade, as pessoas precisam tomar decisões práticas: é seguro correr ao ar livre, mandar as crianças para a escola ou manter as fábricas em funcionamento? Essas decisões dependem da nossa capacidade de prever partículas de poluição muito pequenas chamadas PM2.5, que são pequenas o bastante para se alojarem profundamente nos pulmões. Este estudo apresenta um novo modelo computacional que usa avanços recentes em inteligência artificial para prever níveis de PM2.5 em cidades chinesas com mais precisão e rapidez do que muitas ferramentas existentes, potencialmente oferecendo ao público e aos formuladores de políticas alertas mais precoces e confiáveis.
Dos céus enevoados aos dados inteligentes
A poluição do ar tornou‑se uma ameaça persistente à saúde em muitas áreas urbanas, especialmente no norte da China, onde níveis altos de PM2.5 estão ligados a doenças respiratórias e cardiovasculares. As cidades agora operam redes densas de estações de monitoramento que registram PM2.5, outros poluentes e o clima local a cada hora. Métodos tradicionais de previsão dependem de matemáticas simplificadas ou de modelos físicos feitos manualmente, que têm dificuldade com a realidade desordenada e não linear de ventos giratórios, mudanças de temperatura e atividade humana. Em contraste, a nova abordagem, chamada CBLA, deixa os dados “falarem por si mesmos” ao treinar redes neurais modernas com vários anos de observações de Pequim e Guangzhou.
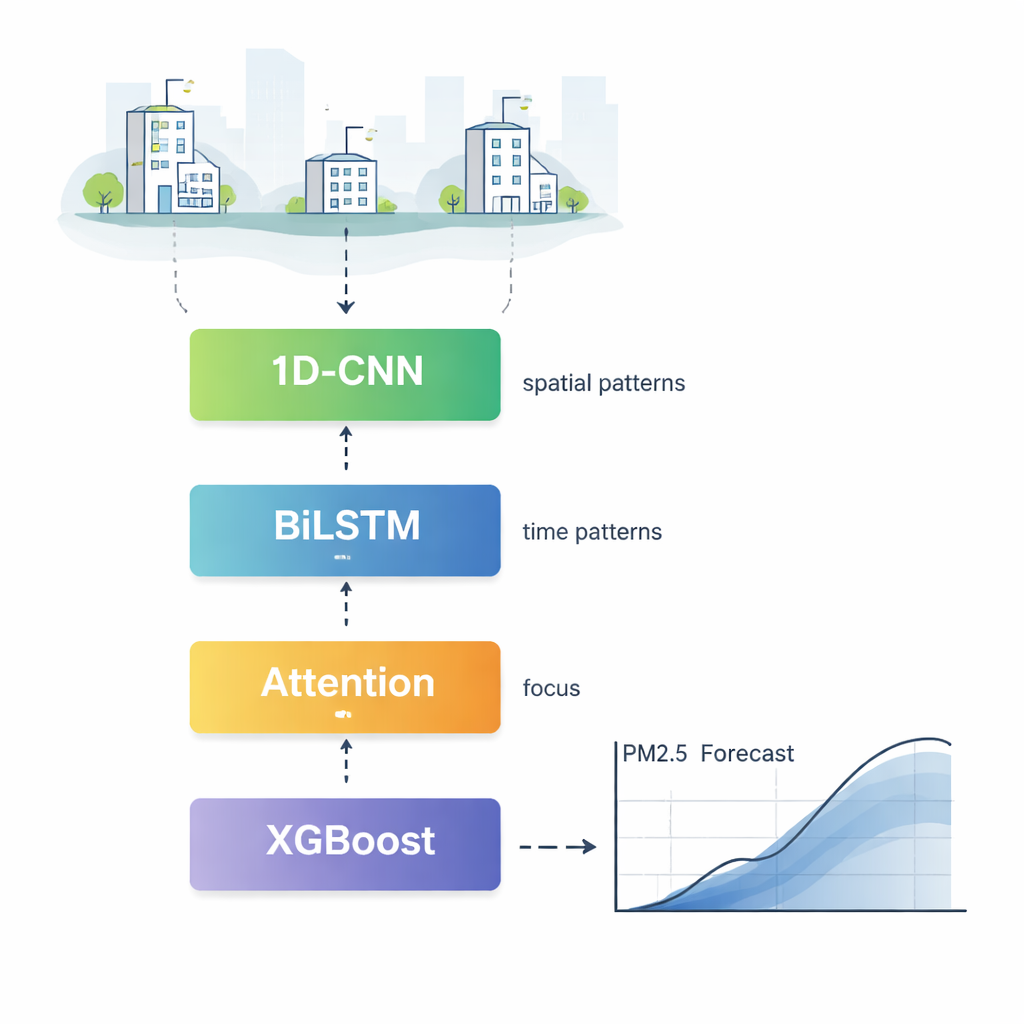
Como funciona o novo motor de previsão
O CBLA age como uma equipe em camadas de especialistas que analisam os dados de poluição de ângulos diferentes antes de votar em uma previsão final. Primeiro, um componente conhecido como rede convolucional unidimensional escaneia medições de muitas estações de monitoramento para identificar padrões que se repetem no espaço, como a forma como a fumaça tende a se espalhar de um bairro para outro. Em seguida, uma rede de memória bidirecional lê históricos de poluição para frente e para trás no tempo, aprendendo como os níveis de hoje dependem tanto de condições recentes quanto de condições um pouco mais antigas. Um mecanismo de atenção então destaca as horas e características mais influentes, permitindo que o modelo foque mais, por exemplo, no pico acentuado de ontem e em ventos fortes do que em leituras distantes e menos relevantes.
Adicionando o tempo para afinar o quadro
A poluição não se move isoladamente; ela se desloca com o tempo atmosférico. Para incorporar essa informação de forma limpa, os autores adicionam um segundo estágio que alimenta tanto a previsão preliminar da rede neural quanto dados meteorológicos detalhados — como velocidade do vento, umidade e temperatura — em um poderoso algoritmo baseado em árvores chamado XGBoost. Esse estágio funciona como um meteorologista experiente conferindo a estimativa inicial com o tempo atual, ajustando a previsão para cima ou para baixo. Testes mostram que essa combinação reduz os erros típicos de previsão e melhora o quão bem a saída do modelo segue as medições do mundo real, especialmente durante acúmulos súbitos de poluição e eventos de limpeza do ar.
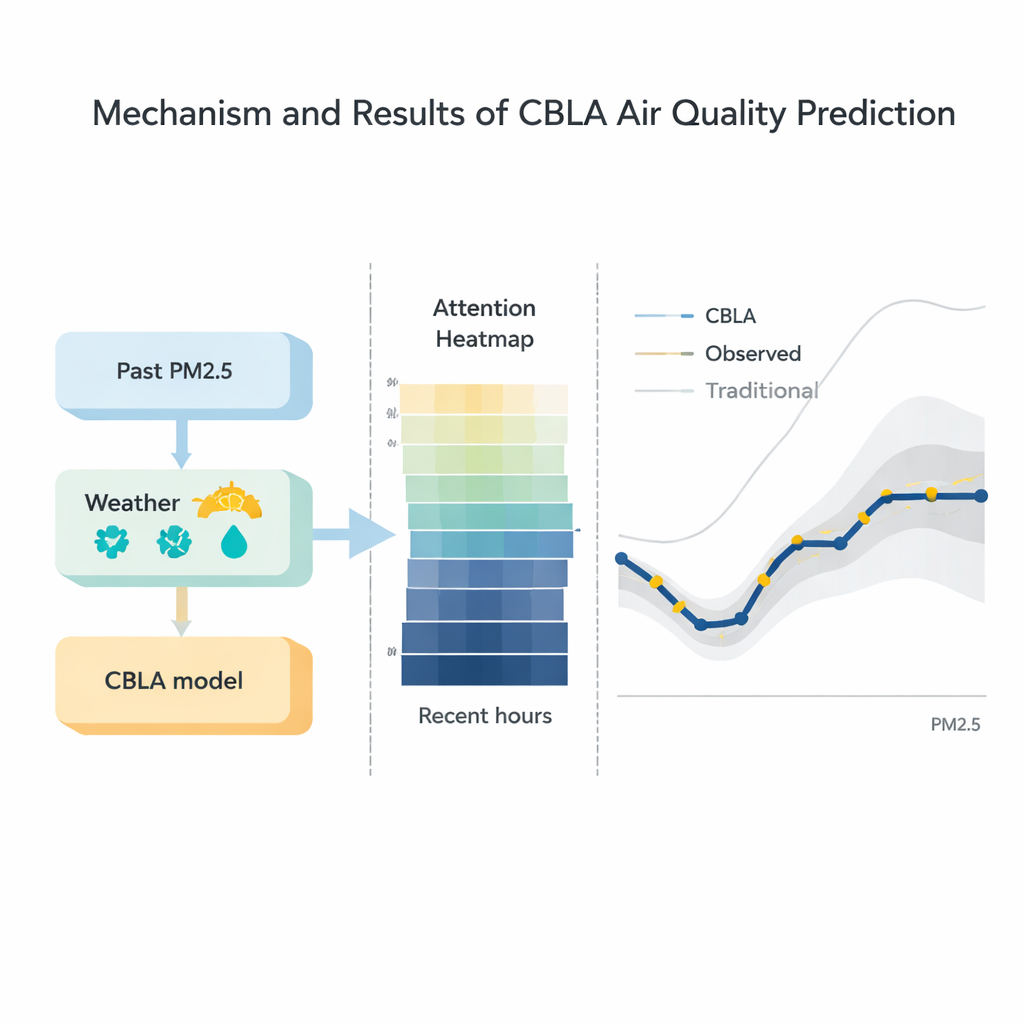
Testando contra modelos rivais
Os pesquisadores compararam o CBLA com uma ampla gama de alternativas, desde técnicas clássicas como regressão e modelos de séries temporais ARIMA até híbridos sofisticados de deep learning que combinam redes gráficas e transformers. Em três conjuntos de dados reais, o CBLA produziu consistentemente o menor erro médio e o melhor ajuste aos níveis observados de PM2.5. Importante, atingiu precisão comparável a alguns dos modelos modernos mais avançados enquanto exigia apenas cerca de um terço do tempo de treinamento deles em hardware padrão. Visualizações do mecanismo de atenção revelaram que o modelo naturalmente dá maior peso às poucas horas mais recentes de dados e a fatores fisicamente relevantes, como velocidade do vento e níveis passados de PM2.5, oferecendo uma janela sobre como suas decisões se alinham com a intuição meteorológica.
O que isso significa para a vida cotidiana
Em termos práticos, o estudo mostra que combinar cuidadosamente várias técnicas de IA pode gerar uma ferramenta de previsão de poluição que não é apenas mais precisa, mas também mais rápida e mais fácil de interpretar. Gestores municipais poderiam usar tal modelo para emitir avisos de saúde, ajustar restrições de tráfego ou reduzir preventivamente as horas de atividade industrial antes de picos perigosos de smog. Para os residentes, previsões melhores significam orientações mais claras sobre quando usar máscaras, ligar purificadores de ar ou manter as crianças em ambientes internos. Embora o trabalho se concentre em cidades chinesas e em PM2.5, a mesma estrutura pode ser adaptada para outras regiões e poluentes, apontando para um futuro em que previsões guiadas por dados ajudam milhões a respirar um pouco melhor.
Citação: Yin, C., Li, W., Li, T. et al. Air quality prediction model based on deep learning hybrid framework. Sci Rep 16, 7084 (2026). https://doi.org/10.1038/s41598-026-37896-y
Palavras-chave: previsão da qualidade do ar, PM2.5, deep learning, poluição urbana, meteorologia