Clear Sky Science · pt
Detecção eficiente de intrusões no conjunto de dados TON-IoT usando abordagem híbrida de seleção de atributos
Por que proteger dispositivos inteligentes importa
Bilhões de aparelhos do dia a dia — de câmeras domésticas a sensores industriais — agora se comunicam pela internet, formando o que chamamos de Internet das Coisas (IoT). Embora essa conectividade traga conveniência e eficiência, ela também abre novas portas para invasores. O artigo resumido aqui aborda uma questão simples, porém crucial: como podemos identificar ataques nessas redes extensas de dispositivos de forma confiável, sem precisar de software de segurança pesado e consumidor de energia?
O desafio de detectar invasões digitais
Para estudar ataques a sistemas IoT, pesquisadores frequentemente usam grandes conjuntos de dados públicos que registram como o tráfego de rede se comporta durante operações normais e durante ataques cibernéticos. Um dos mais utilizados é o conjunto ToN-IoT, que captura tráfego real de um ambiente industrial de teste realista, incluindo muitos tipos de ataques como negação de serviço, ransomware, quebra de senhas e espionagem man-in-the-middle. Contudo, os autores mostram que esse conjunto de dados tem uma armadilha oculta: muitos ataques foram lançados a partir de faixas fixas de endereços IP e números de porta. Isso significa que um modelo pode “trapacear” aprendendo quem é o atacante, em vez de aprender como o comportamento malicioso se manifesta. Modelos assim podem obter pontuações muito altas em laboratório, mas falhar de forma significativa quando um invasor vem de um endereço novo.
De dados volumosos a uma visão enxuta do comportamento
Os dados de rede originais do ToN-IoT incluem 44 medições diferentes para cada conexão, variando desde informações de IP até detalhes de tráfego web e criptografado. Processar todas elas aumenta o tempo de computação e a necessidade de memória, o que é problemático para gateways e dispositivos de borda com recursos limitados. Os autores primeiro usam seu entendimento sobre como os ataques funcionam para eliminar atributos que são viesados (como endereços IP e números de porta) ou pouco úteis para distinguir ataques. Eles argumentam que a maioria das ameaças a IoT acaba se manifestando como padrões estranhos em quantos pacotes e bytes são enviados e recebidos e na duração das conexões — independentemente de quem está se comunicando com quem. Essa primeira etapa reduz o conjunto de atributos de 44 para sete estatísticas centrais de tráfego relacionadas ao volume e à duração.
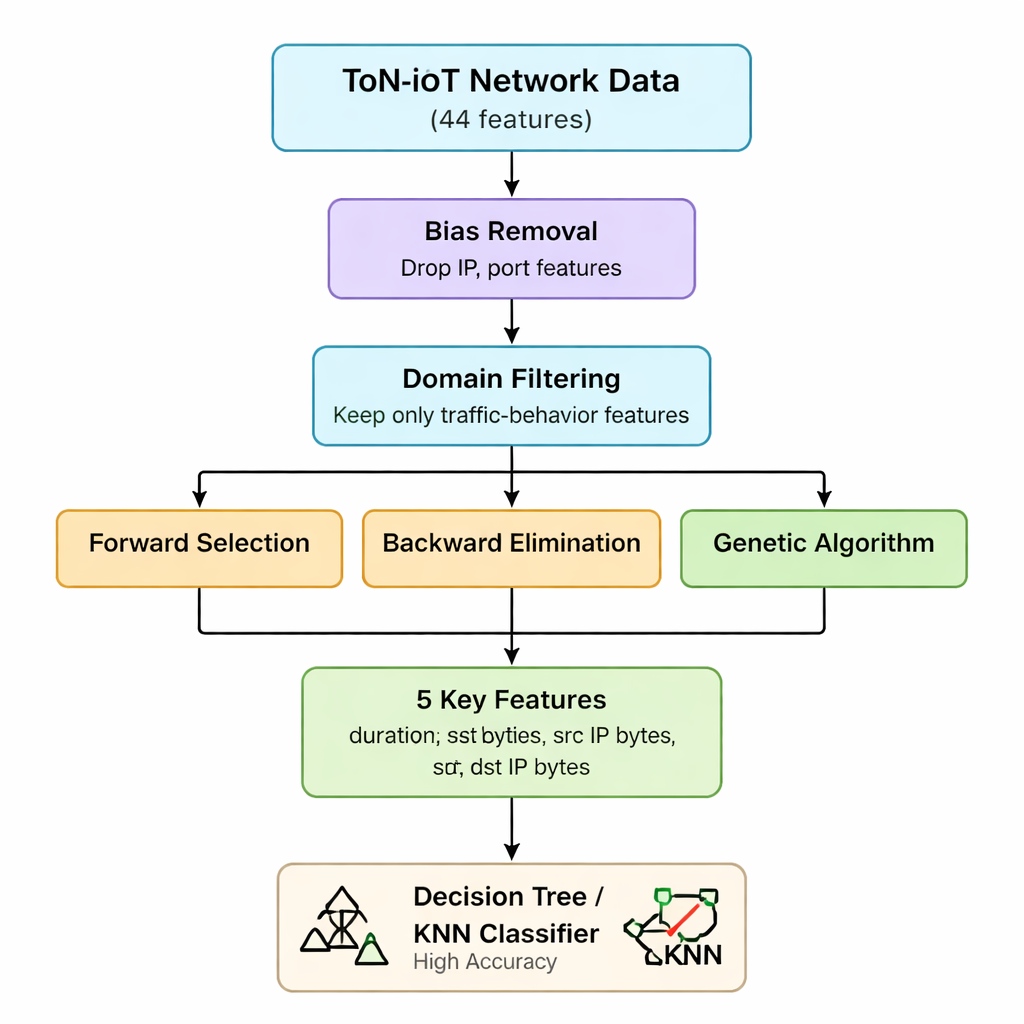
Seleção híbrida de atributos: três lentes sobre os mesmos dados
Em seguida, a equipe aplica três métodos “wrapper” diferentes que treinam repetidamente um modelo enquanto adicionam, removem ou recombinam atributos para ver qual subconjunto realmente importa mais. A seleção forward constrói a partir de um conjunto vazio, mantendo um atributo apenas se ele aumentar a acurácia. A eliminação backward começa com os sete atributos e remove aqueles cuja exclusão não prejudica a acurácia. Um algoritmo genético explora muitas combinações em paralelo, evoluindo subconjuntos melhores ao longo de gerações. Todos os três são testados usando um classificador simples de árvore de decisão, com a acurácia como métrica. Ao intersectar os resultados, os autores chegam a um núcleo estável de cinco atributos: duração da conexão, bytes enviados, bytes recebidos e as contagens correspondentes de bytes no nível IP. Essas cinco variáveis capturam efetivamente surtos anormais ou desequilíbrios no tráfego que sinalizam muitos tipos diferentes de ataque.
Modelos leves que ainda têm bom desempenho
Com esse conjunto de dados reduzido e focado no comportamento, os pesquisadores avaliam o quão bem modelos simples de aprendizado de máquina conseguem diferenciar tráfego seguro de ataques. Usando apenas as cinco características escolhidas, uma árvore de decisão alcança 98,6% de acurácia na classificação binária “ataque vs normal” e 97,2% de acurácia ao distinguir entre múltiplas categorias de ataque. Um modelo k-nearest neighbor tem desempenho similar, e métodos de ensemble mais complexos, como random forests ou gradient boosting, oferecem apenas ganhos pequenos enquanto exigem mais computação e memória. Crucialmente, os autores confirmam por testes estatísticos que as características escolhidas são genuinamente informativas, em vez de artefatos da forma como os dados foram coletados. Eles observam, contudo, que ataques sutis man-in-the-middle — projetados para se misturar aos fluxos normais — continuam mais difíceis de detectar, indicando que trabalhos futuros podem precisar de sinais de protocolo ou temporização mais ricos para esses casos.
O que isso significa para a segurança no mundo real
Para não especialistas, a principal conclusão é que nem sempre é preciso usar modelos gigantes ou dezenas de medições técnicas para proteger sistemas IoT. Ao eliminar pistas que funcionam apenas em uma configuração de laboratório e focar, em vez disso, em um punhado de comportamentos de tráfego, os autores mostram que algoritmos simples e rápidos ainda podem detectar a maioria dos ataques com alta confiabilidade. A versão reduzida do conjunto ToN-IoT com cinco atributos é mais fácil de processar em dispositivos com recursos limitados na borda da rede, tornando-a prática para roteadores, gateways e pequenos hubs que precisam reagir a ameaças em tempo real. Em suma, o estudo sugere um caminho para detecção de intrusões mais confiável e aplicável aos dispositivos inteligentes cotidianos que cada vez mais nos cercam.
Citação: Dharini, N., Janani, V.S. & Katiravan, J. Efficient detection of intrusions in TON-IoT dataset using hybrid feature selection approach. Sci Rep 16, 7763 (2026). https://doi.org/10.1038/s41598-026-37834-y
Palavras-chave: segurança IoT, detecção de intrusões, aprendizado de máquina, seleção de atributos, tráfego de rede