Clear Sky Science · pt
Modelagem e aplicação da previsão de traço complexo da doença de Alzheimer baseada em aprendizado multi-tarefa
Por que esta pesquisa importa para famílias e pacientes
A doença de Alzheimer é um dos diagnósticos mais temidos do nosso tempo, e ainda assim os médicos têm dificuldade em prever quem vai declinar rapidamente, quem permanecerá estável por anos e quais sinais precoces realmente importam. Este estudo faz uma pergunta simples, porém poderosa: se olharmos várias medidas relacionadas ao Alzheimer — testes e exames cerebrais — em conjunto e as combinarmos com a informação genética de uma pessoa, a inteligência artificial moderna pode aprender padrões que nos ajudem a prever o curso da doença com maior precisão?
Muitas faces da mesma doença
Alzheimer não é apenas perda de memória. Os pacientes diferem em como se saem em testes cognitivos, em quão bem realizam tarefas do dia a dia e em como seus exames cerebrais se apresentam. Essas medições distintas — como escalas comuns de memória e raciocínio, questionários sobre funcionamento diário e PET scans de metabolismo cerebral ou acúmulo de beta-amiloide — sabem-se que são parcialmente influenciadas por genes. Importante, elas também compartilham algumas das mesmas origens genéticas. Métodos tradicionais de predição costumam focar em uma medida por vez, desprezando o fato útil de que esses traços estão relacionados. Os autores defendem que, assim como um médico que enxerga o quadro completo em vez de um único teste, os modelos deveriam aprender a partir de vários traços ao mesmo tempo.
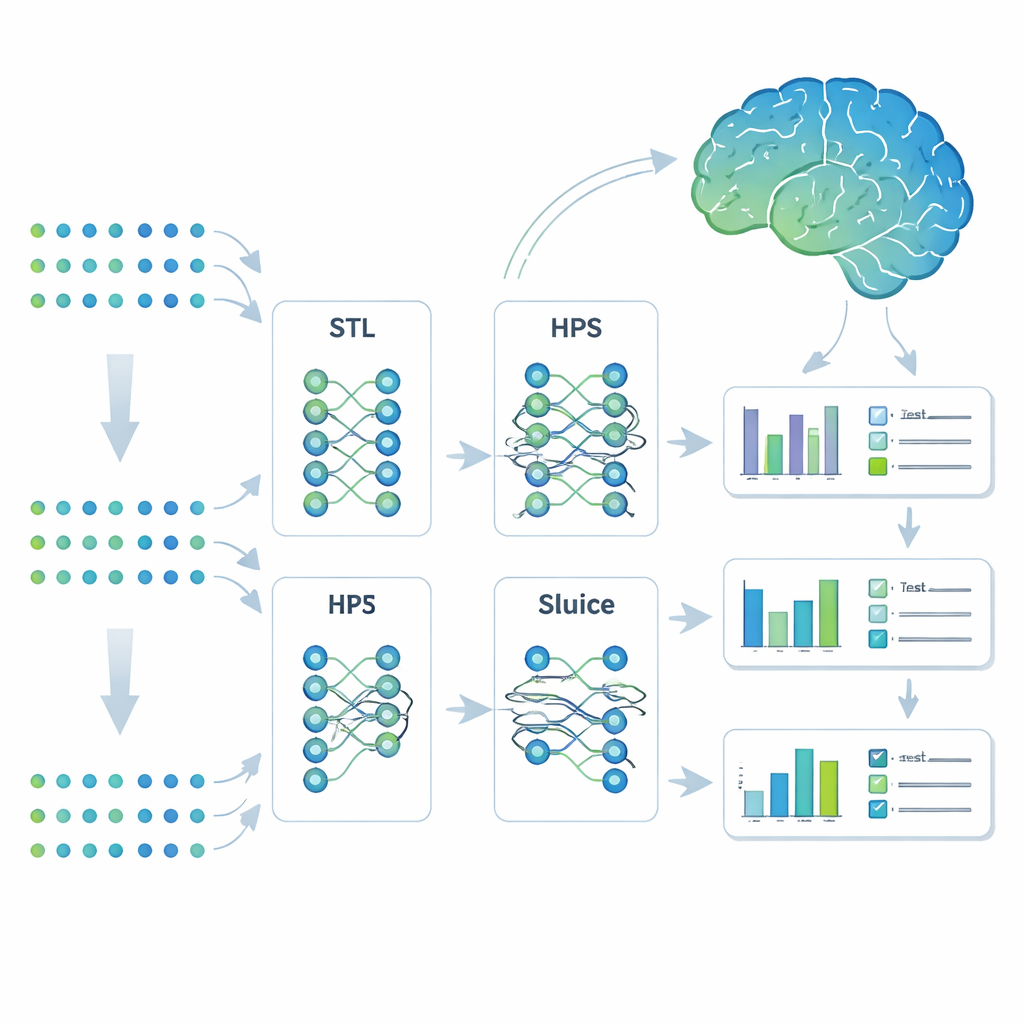
Ensinar um modelo a aprender várias tarefas relacionadas
Os pesquisadores recorreram a uma estratégia de aprendizado de máquina chamada aprendizado multi-tarefa. Em vez de construir modelos separados para cada desfecho, eles treinaram um único sistema para prever sete traços relacionados ao Alzheimer simultaneamente. Compararam quatro abordagens: modelos completamente separados (aprendizado single-task), um modelo compartilhado simples que só se divide no final (compartilhamento rígido de parâmetros), um desenho mais flexível em ramificações que pode separar tarefas em subgrupos, e um projeto altamente adaptável chamado Sluice Network, que pode ajustar com precisão quanto de informação é compartilhada em cada camada da rede. Todos os quatro modelos receberam as mesmas entradas genéticas; a diferença estava em como compartilhavam o que aprendiam entre os traços.
Testando ideias em genomas simulados
Antes de confiar em qualquer modelo em pacientes reais, a equipe construiu simulações detalhadas usando padrões genéticos reais extraídos da Alzheimer’s Disease Neuroimaging Initiative (ADNI), mas com desfechos que podiam controlar totalmente. Criaram cenários nos quais todos os traços compartilhavam as mesmas causas genéticas, onde os traços formavam grupos sobrepostos e onde cada traço tinha causas distintas. Também variaram a força dos sinais genéticos e a quantidade de ruído adicionada, imitando a realidade ruidosa dos dados humanos. Em quase todas as condições, a Sluice Network entregou as previsões mais precisas e manteve estabilidade mesmo quando os traços eram apenas fracamente relacionados. Modelos compartilhados mais simples funcionaram bem quando os traços tinham muitos fatores genéticos em comum, mas falharam quando esse compartilhamento era baixo, enquanto modelos completamente separados foram estáveis porém menos precisos no geral.
Dados do mundo real e o poder de agrupar genes
Os autores então aplicaram esses modelos aos dados reais da ADNI de 463 indivíduos, usando quase 3.800 marcadores genéticos extraídos de 56 genes previamente associados ao Alzheimer. Aqui eles adicionaram um elemento inspirado na biologia: em vez de alimentar a rede com milhares de marcadores genéticos individuais, agruparam primeiro os marcadores por gene e permitiram que a rede aprendesse um sinal “resumido” compacto para cada gene antes de prever os sete desfechos. Essa agregação a nível de gene aumentou o desempenho da maioria dos modelos e especialmente da Sluice Network, que aproximadamente dobrou sua correlação média com os desfechos reais. Os ganhos foram mais claros para medidas de imagem por PET e certas pontuações cognitivas e funcionais, sugerindo que efeitos genéticos sutis se tornam mais detectáveis quando combinados no nível do gene em vez de tratados como marcadores isolados.
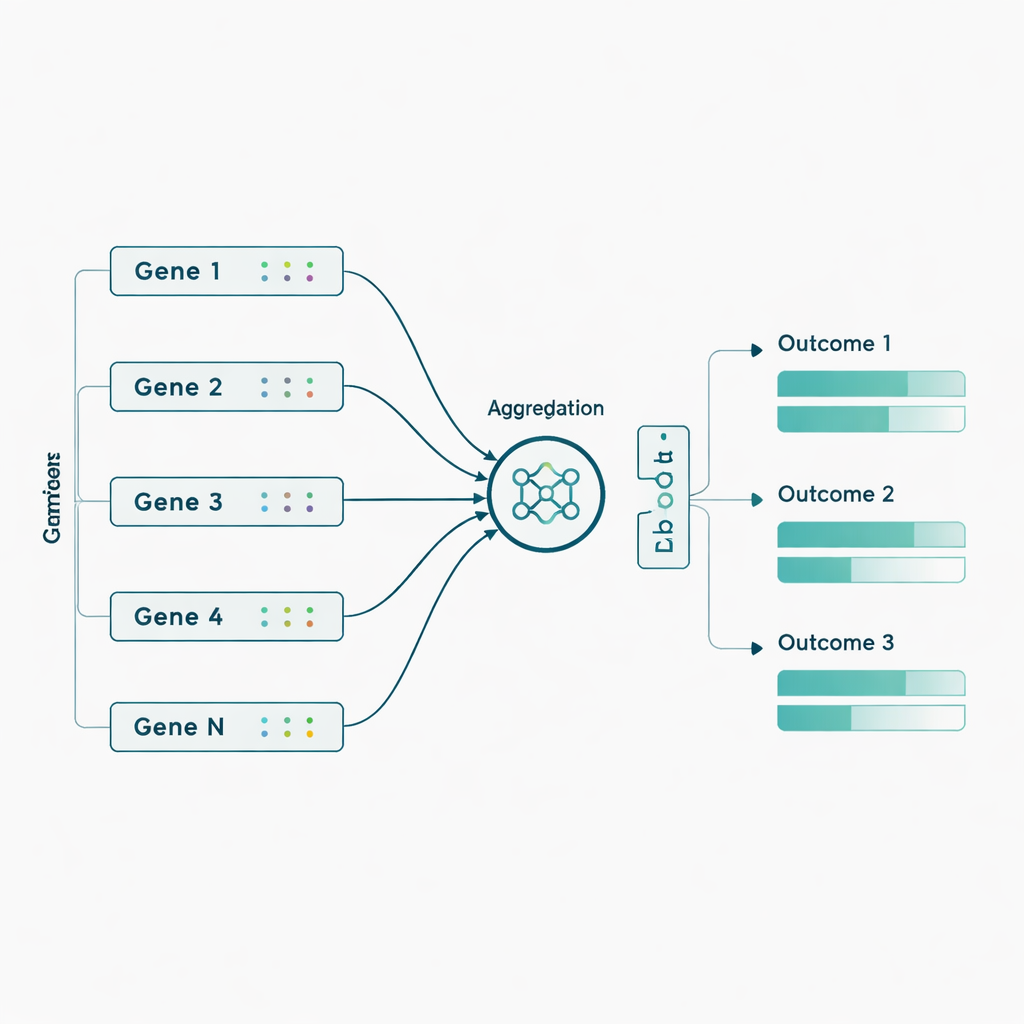
O que isso significa para futuras previsões e cuidados
Para um não especialista, a mensagem é que modelos de IA mais inteligentes e flexíveis podem extrair mais insights dos mesmos dados genéticos e clínicos aprendendo a partir de vários desfechos relacionados ao mesmo tempo e respeitando como a biologia está organizada em genes. Embora os ganhos atuais sejam modestos e ainda distantes de um teste clínico, a abordagem aponta para ferramentas mais confiáveis para estimar o perfil de risco de uma pessoa, acompanhar a progressão provável e, talvez, personalizar monitoramento ou intervenções. Em doenças complexas como o Alzheimer, onde muitos efeitos genéticos pequenos interagem, métodos que compartilham informação entre traços e agregam sinais fracos podem oferecer um panorama mais claro e informativo do que as pontuações tradicionais que analisam um traço de cada vez.
Citação: Zhou, W., Xue, Z., Liang, J. et al. Modeling and application of alzheimer’s disease complex trait prediction based on multi-task learning. Sci Rep 16, 7749 (2026). https://doi.org/10.1038/s41598-026-37820-4
Palavras-chave: Genética da doença de Alzheimer, aprendizado multi-tarefa, previsão por aprendizado profundo, biomarcadores de neuroimagem, agregação a nível de gene