Clear Sky Science · pt
Uma análise comparativa do desempenho de grandes modelos de linguagem no exame de especialidade em odontologia
Por que chatbots inteligentes importam para os dentistas do futuro
A inteligência artificial está mudando rapidamente a forma como médicos e dentistas aprendem e trabalham. Uma das ferramentas mais visíveis é o chatbot conversacional alimentado por grandes modelos de linguagem — o mesmo tipo de tecnologia por trás de muitos assistentes de IA populares. Este estudo fez uma pergunta simples, mas importante: se estudantes de odontologia usassem essas ferramentas para se preparar para um exame de especialidade altamente competitivo em radiologia oral e maxilofacial, quão bem as máquinas realmente se sairiam?
Testando a IA em um exame real
Para descobrir, os pesquisadores recorreram ao Exame de Ingresso em Especialização em Odontologia (DUS) na Turquia, que ajuda a determinar quem pode ingressar em programas de treinamento avançado. A partir de edições anteriores deste exame nacional, selecionaram 208 questões de múltipla escolha cobrindo tópicos que especialistas em radiologia precisam dominar, desde física da radiação e técnicas de imagem até tumores mandibulares e doenças dos seios da face. A maior parte das questões era apenas em texto, mas um conjunto menor exigia interpretar imagens radiográficas, refletindo o trabalho diagnóstico do mundo real.
Sete chatbots enfrentam o mesmo desafio
A equipe então apresentou cada questão, em turco, a sete chatbots de IA amplamente usados e baseados em diferentes grandes modelos de linguagem: duas versões do ChatGPT, além de Gemini, Copilot, DeepSeek, Claude e Grok. Cada pergunta foi inserida com cuidado e separadamente para evitar qualquer contaminação entre conversas. Um segundo pesquisador comparou cada resposta de IA com o gabarito oficial e marcou-a como correta ou incorreta. Por fim, os autores usaram testes estatísticos padrão para comparar os modelos no geral e dentro de áreas temáticas específicas.
Quem teve a melhor pontuação — e onde eles vacilaram
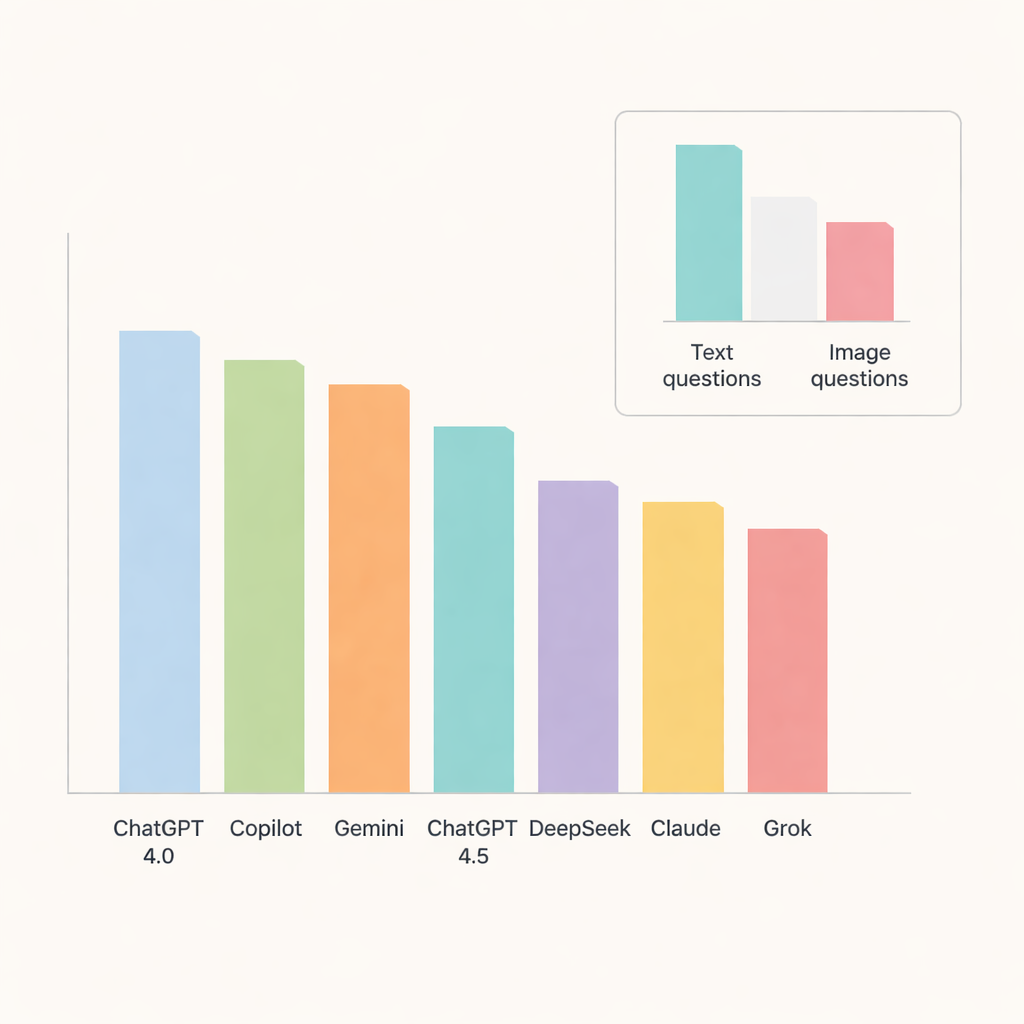
Entre todos os chatbots, o ChatGPT 4.0 se destacou, respondendo cerca de 91% das questões corretamente. Copilot e Gemini seguiram de perto, com precisão em torno da faixa média-alta dos 80%, enquanto ChatGPT 4.5, DeepSeek, Claude e Grok ficaram um pouco atrás. Quando os pesquisadores aprofundaram os tópicos, os modelos se saíram especialmente bem em patologia oral e doenças das glândulas salivares, onde a acurácia se aproximou ou excedeu 90%. Em contraste, anatomia radiográfica e calcificações de tecidos moles foram notavelmente mais difíceis, reduzindo as pontuações entre os sistemas e indicando áreas nas quais a IA ainda tem dificuldade com detalhes finos.
Imagens continuam mais difíceis que palavras
Um teste chave foi saber se os chatbots conseguiam lidar com imagens tão bem quanto com texto. Nesse ponto, as limitações ficaram claras. A precisão caiu acentuadamente nas questões baseadas em imagens, mesmo para os modelos de melhor desempenho. ChatGPT 4.0, Gemini e Copilot lideraram essa categoria, mas ainda assim responderam corretamente apenas cerca de dois terços das questões visuais. DeepSeek teve o pior desempenho em imagens, com pouco mais de um terço corretas. Para a maioria dos modelos, a diferença entre o desempenho em texto e em imagem foi grande o suficiente para ser estatisticamente significativa, ressaltando que interpretar imagens médicas permanece uma tarefa difícil para as IAs de uso geral atuais.
O que isso significa para estudantes e pacientes
A conclusão do estudo é que chatbots modernos podem ser auxiliares poderosos na educação odontológica, especialmente para revisar fatos e praticar questões no estilo de exames em radiologia. No entanto, mesmo os sistemas mais fortes cometem erros suficientes — particularmente em tópicos visualmente exigentes ou altamente específicos — para que não possam substituir com segurança o julgamento de especialistas. Para estudantes e clínicos, essas ferramentas são melhores vistas como parceiros inteligentes de estudo ou auxiliares de decisão, não como autoridades autônomas. Usadas com cautela e supervisão apropriadas, podem acelerar o aprendizado e ampliar o acesso a explicações de alta qualidade, enquanto a responsabilidade final pelo diagnóstico e tratamento permanece firmemente com profissionais treinados.
Citação: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Palavras-chave: educação odontológica, inteligência artificial, grandes modelos de linguagem, radiologia oral e maxilofacial, exames médicos