Clear Sky Science · pt
Detecção de spam por SMS entre idiomas usando aumento baseado em GAN para conjuntos de dados desbalanceados
Por que suas mensagens de texto ainda precisam de proteção
A maioria de nós confia que mensagens indesejadas serão silenciosamente movidas para uma pasta de spam, mas nos bastidores isso é um problema bem difícil. Spam verdadeiro é raro em comparação com mensagens do dia a dia, e aparece cada vez mais em várias línguas ao mesmo tempo. Este artigo apresenta uma nova forma de identificar spam perigoso por SMS combinando modelos de linguagem poderosos com um gerador inteligente de “dados falsos”, para que filtros possam aprender a partir de muito mais exemplos de mensagens maliciosas sem colocar sua privacidade em risco.
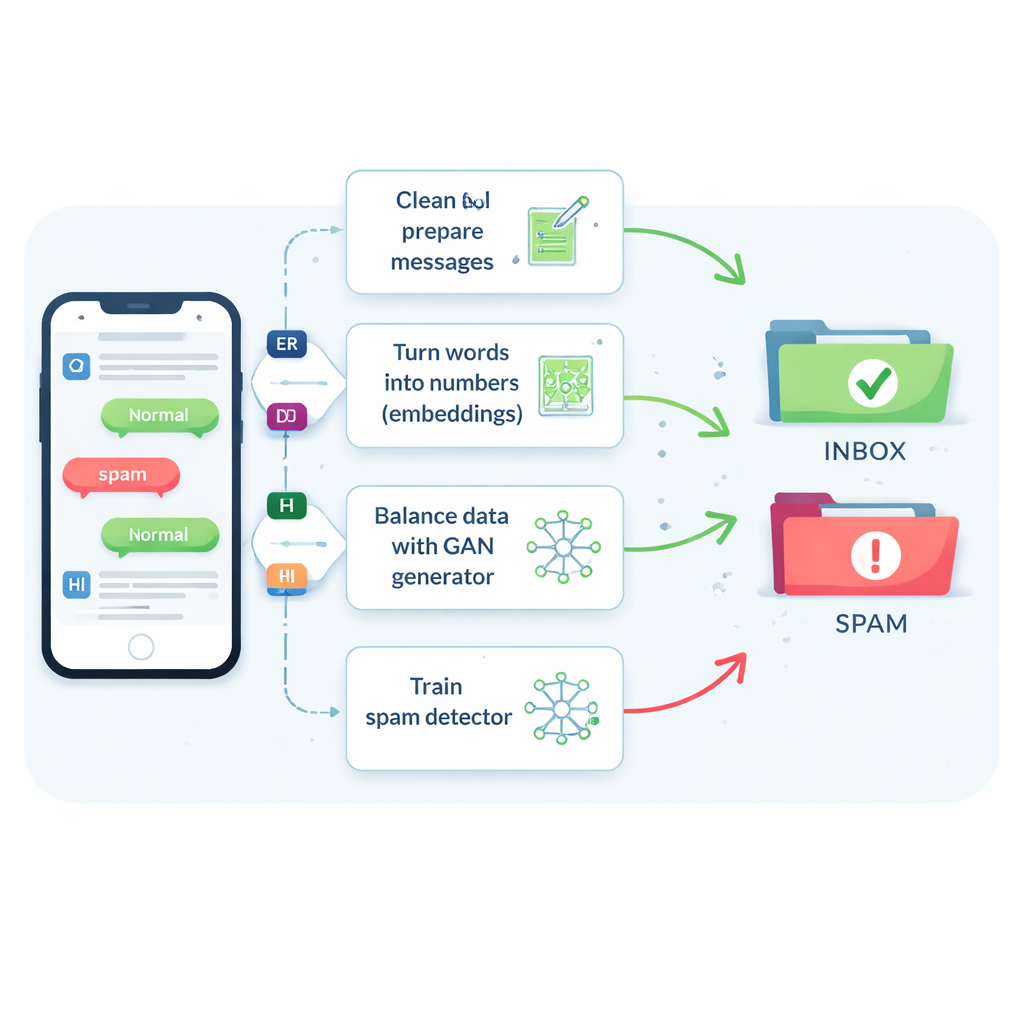
O problema do spam raro e mutante
Mensagens de spam representam cerca de uma em cada sete mensagens, ainda que perder mesmo uma pequena fração delas possa expor pessoas a golpes, malware e roubo de identidade. Filtros tradicionais têm dificuldades porque SMS são curtas, cheias de gírias e abreviações, e chegam em tempo real com pouco contexto adicional. Como resultado, muitos sistemas tendem a classificar mensagens como seguras, o que mantém os usuários satisfeitos mas deixa passar textos mais nocivos. Truques antigos que simplesmente duplicam mensagens de spam ou inventam novas alterando palavras ajudam um pouco, mas frequentemente confundem o filtro ou geram exemplos pouco realistas que não correspondem ao que criminosos realmente enviam.
Ensinando máquinas a entender o significado das mensagens
Os autores começam comparando oito algoritmos de aprendizado diferentes, de ferramentas familiares como máquinas de vetores de suporte e árvores de decisão até redes neurais mais avançadas que leem texto como sequência, tais como redes LSTM (long short-term memory). Eles também testam cinco formas de transformar palavras em números que um computador possa usar. Contagens simples da frequência de cada palavra (conhecidas como bag-of-words ou TF–IDF) são rápidas, mas cegas para o significado. “Embeddings” mais recentes como Word2Vec e GloVe colocam palavras com significados semelhantes próximas umas das outras em um espaço numérico. Os mais avançados são modelos baseados em transformers como o BERT, que ajustam a representação de uma palavra dependendo da frase ao redor, ajudando o sistema a distinguir, por exemplo, um lembrete amigável de um golpe convincente.
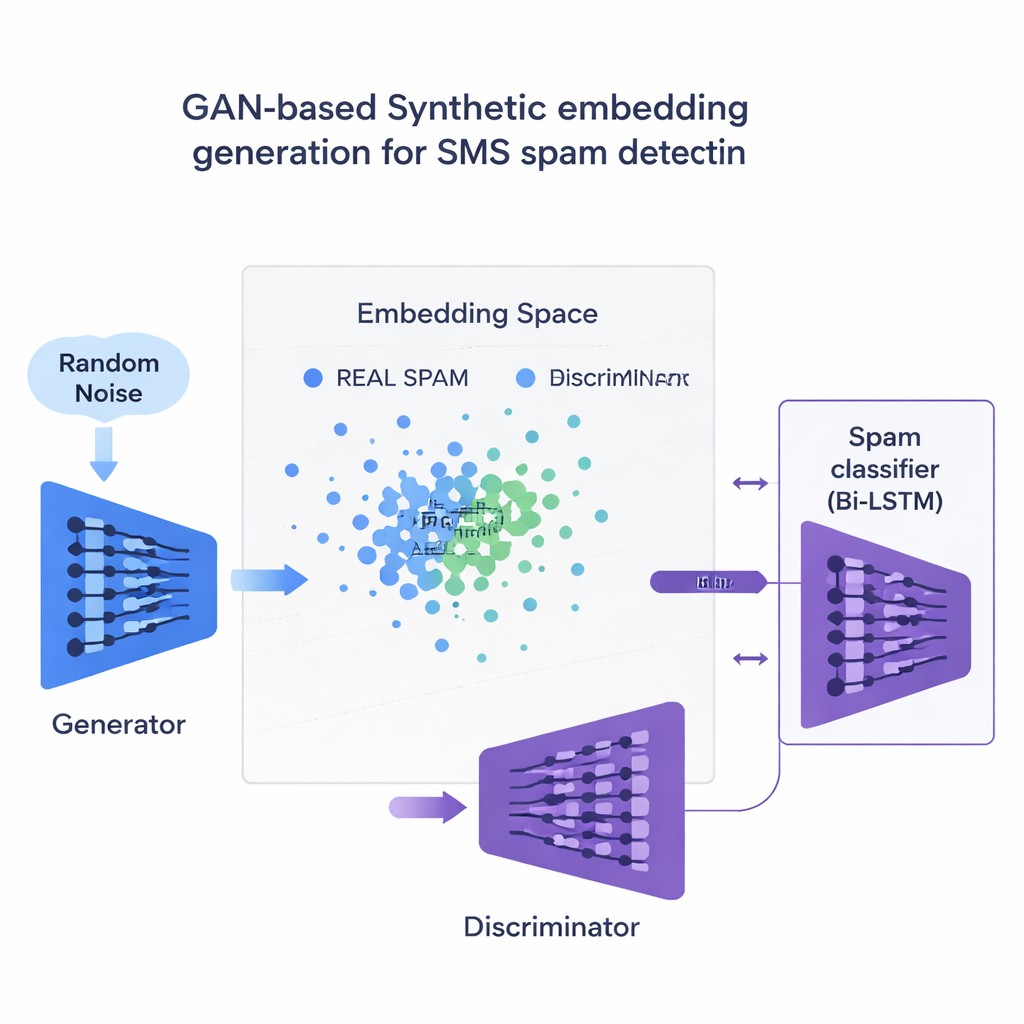
Usando spam “falso” inteligente para corrigir um conjunto de dados desequilibrado
A inovação central é como o estudo enfrenta a escassez de exemplos de spam. Em vez de gerar sentenças falsas completas, a equipe treina um tipo de rede neural chamada Generative Adversarial Network (GAN) diretamente sobre os embeddings numéricos de mensagens de spam. Uma parte do GAN, o gerador, aprende a criar pontos sintéticos semelhantes ao spam nesse espaço de alta dimensão, enquanto outra parte, o discriminador, aprende a distingui-los dos reais. Através dessa rivalidade, o gerador produz novos embeddings de spam realistas que expandem o conjunto de treinamento. Uma verificação de qualidade baseada em similaridade garante que apenas exemplos sintéticos que se assemelhem de perto ao spam genuíno sejam mantidos, reduzindo o risco de dados sem sentido que poderiam enganar o classificador.
Resultados entre línguas e dispositivos
Os pesquisadores testam 120 combinações diferentes de modelos, embeddings e métodos de balanceamento de dados, tanto em um conjunto de SMS em inglês quanto em uma versão multilíngue traduzida para francês, alemão e hindi. Em toda a linha, embeddings contextuais como o BERT superam abordagens antigas de contagem de palavras. A melhor configuração — um LSTM bidirecional alimentado com embeddings BERT e treinado com exemplos de spam gerados por GAN — atinge uma pontuação F1 em torno de 97,6% em mensagens em inglês e 94,4% no conjunto multilíngue, superando ligeiramente os sistemas atuais de ponta. Crucialmente, isso acontece mantendo alarmes falsos extremamente baixos, um requisito importante para que senhas de uso único e alertas bancários não sejam ocultados dos usuários. O estudo também compara essa estratégia de GAN com ferramentas de balanceamento mais comuns como SMOTE e ADASYN, concluindo que o GAN produz dados de treinamento mais limpos e realistas e desempenho geral ligeiramente melhor.
O que isso significa para usuários comuns
Para não especialistas, a conclusão é que filtros de spam estão começando a entender o significado e o contexto das suas mensagens, não apenas palavras isoladas, e podem ser “treinados” com dados sintéticos cuidadosamente elaborados em vez de ver mais de seus textos reais. Ao trabalhar diretamente no espaço onde o significado da mensagem é codificado, o método proposto dá aos sistemas de segurança uma imagem mais rica de como o spam se manifesta em várias línguas, sem inundá‑los com falsificações atrapalhadas. Isso torna mais provável que mensagens perigosas sejam capturadas e as legítimas entregues, oferecendo uma proteção mais forte e adaptável para usuários móveis à medida que golpistas continuam a mudar de tática.
Citação: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Palavras-chave: detecção de spam por SMS, aumento de dados com GAN, embeddings de texto BERT, cibersegurança multilíngue, phishing móvel