Clear Sky Science · pt
Uma arquitetura leve de rede neural convolucional para detecção de violência em sequências de vídeo
Vigiando Multidões Para Que Humanos Não Precisem
De shows e arenas esportivas a estações de metrô e shoppings, câmeras agora monitoram quase todo espaço lotado. Ainda assim, a maior parte desses fluxos de vídeo continua sendo observada por olhos humanos cansados que podem facilmente perder os primeiros sinais de uma briga ou de um pisoteamento. Este artigo explora como uma forma enxuta e rápida de inteligência artificial pode vasculhar vídeo ao vivo em busca de comportamento violento em tempo real, mesmo em hardware de baixo custo, ajudando a equipe de segurança a reagir rapidamente antes que a situação saia do controle.
Por Que Detectar Violência em Vídeo é Tão Difícil
À primeira vista, pedir a um computador para diferenciar "briga" de "sem briga" soa simples: basta detectar pessoas se batendo. Na prática, o problema é complicado. A iluminação pode ser ruim ou mudar de repente, multidões podem obstruir a visão e as câmeras ficam instaladas em ângulos diversos. Um show lotado parece caótico mesmo quando nada perigoso acontece, enquanto uma luta de boxe parece violenta mas é perfeitamente normal dentro do ringue. Sistemas tradicionais de visão analisavam padrões de movimento e contornos feitos manualmente quadro a quadro e, embora funcionassem em laboratório, muitas vezes eram lentos demais ou imprecisos demais para redes de vigilância ocupadas no mundo real.
Um Cérebro Mais Magro para Fluxos de Câmera
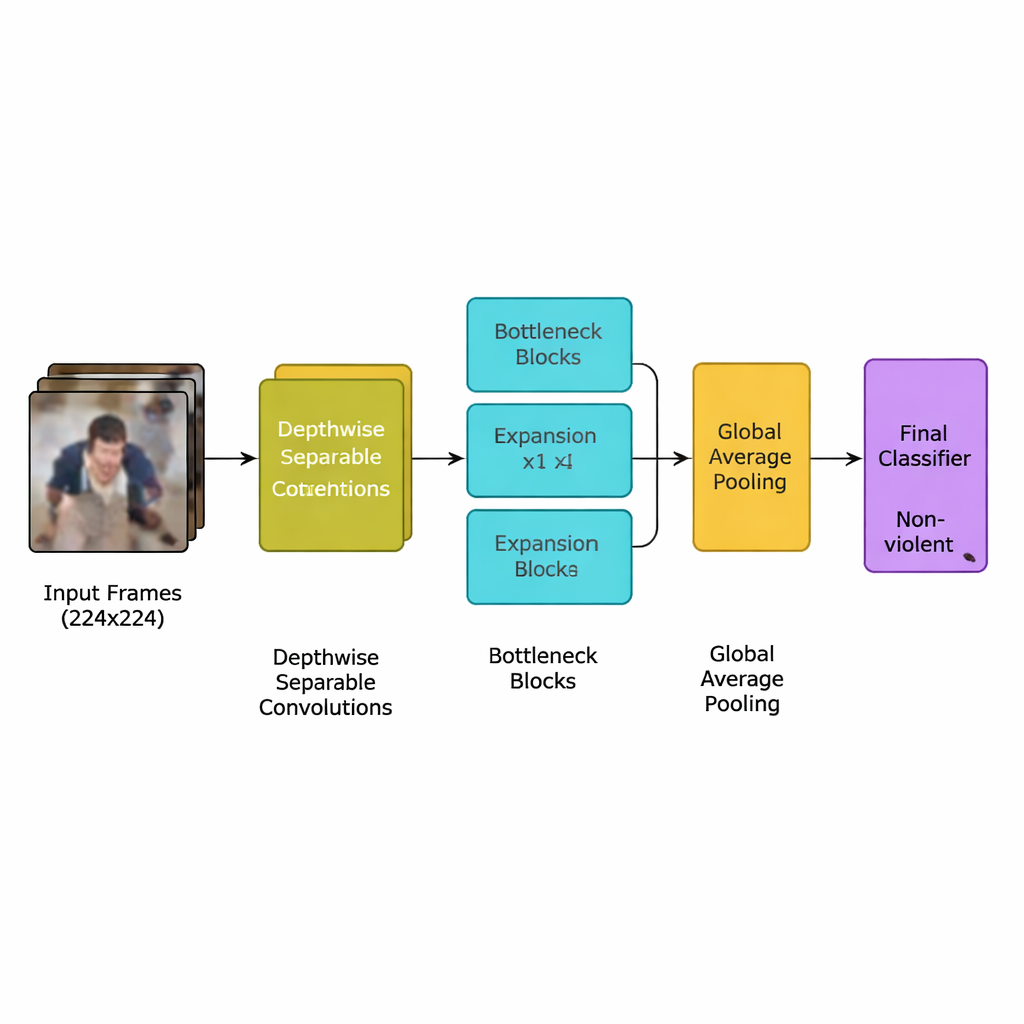
Os autores apresentam um novo modelo de deep learning projetado especificamente para essa tarefa: uma rede neural convolucional (CNN) leve derivada de uma família eficiente de modelos conhecida como MobileNetV2. Em vez de usar muitas camadas pesadas que exigem processadores gráficos potentes, a rede se apoia em convoluções separáveis por profundidade—cálculos pequenos e direcionados que reduzem drasticamente o número de operações. Ela também usa blocos de "gargalo invertido", que expandem brevemente e depois comprimem a informação para preservar pistas de movimento importantes enquanto descartam redundâncias. Sobre isso, a equipe adiciona um mecanismo de atenção chamado squeeze‑and‑excitation, que ajuda a rede a focar em padrões de movimento no espaço e no tempo mais típicos de incidentes violentos, ao mesmo tempo em que ignora detalhes de fundo distrativos.
Do Vídeo Bruto a Alertas de Violência
O sistema completo segue um pipeline claro. Primeiro, os fluxos de vídeo são quebrados em quadros, e apenas a cada quinto quadro é mantido para remover quase‑duplicatas preservando movimentos súbitos que frequentemente sinalizam uma briga. Os quadros são redimensionados para um padrão de 224×224 pixels, levemente desfocados para reduzir ruído de fundo e então aleatoriamente espelhados ou rotacionados durante o treinamento para que o modelo aprenda a lidar com diferentes pontos de vista das câmeras. Essas imagens preparadas alimentam a CNN leve, que converte gradualmente pixels brutos em padrões de comportamento de multidão de nível mais alto. Após uma etapa final de pooling que resume cada quadro, um pequeno classificador emite uma decisão simples: violento ou não violento. Como o modelo usa apenas cerca de 1,94 milhão de parâmetros—menos que seus antecessores MobileNet e MobileNetV2—ele pode rodar em tempo real em dispositivos modestos colocados perto das câmeras em vez de em um centro de dados distante.
Testando o Sistema
Para verificar se esse projeto compacto poderia competir com redes mais volumosas, os pesquisadores o treinarem e avaliaram em dois benchmarks amplamente usados. O Real‑Life Violence Situations Dataset contém 2.000 clipes curtos raspados do YouTube mostrando cenas cotidianas e brigas reais em locais variados. O Hockey Fight Dataset oferece 1.000 clipes de jogos profissionais de hóquei, divididos entre jogo normal e brigas no gelo. Nesses conjuntos, o modelo proposto rotulou corretamente cerca de 97% dos clipes em cenários da vida real e 94% nos vídeos de hóquei, igualando ou superando CNNs maiores como InceptionV3 e VGG‑19 enquanto usava muito menos computação. Testes cruzados entre os dois datasets—treinar em um e testar no outro—mostraram que o sistema ainda teve desempenho razoável, sugerindo que captura padrões gerais de movimento em vez de memorizar um único ambiente.
O Que Isso Significa para a Segurança do Dia a Dia
Para não especialistas, a conclusão principal é que agora é possível construir sistemas de câmera que sinalizam automaticamente probabilidade de violência de forma rápida e econômica, sem necessidade de servidores gigantes ou atenção humana constante. O estudo mostra que uma rede neural cuidadosamente aparada e ajustada pode monitorar várias transmissões ao mesmo tempo, enviar alertas ao detectar comportamento perigoso e ainda rodar em hardware de baixa potência adequado para hubs de transporte público, escolas, hospitais e vias urbanas. Embora desafios permaneçam—como lidar com cenas muito escuras, lotação intensa ou incorporar pistas sonoras—o trabalho aponta para um futuro em que câmeras inteligentes atuam como sensores incansáveis de alerta precoce, ajudando equipes de segurança a proteger pessoas com maior eficácia enquanto reduz o fardo sobre os observadores humanos.
Citação: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Palavras-chave: detecção de violência, vigilância por vídeo, CNN leve, MobileNetV2, segurança pública