Clear Sky Science · pt
MSRCTNet: uma nova rede tripla de cápsulas multiescala para remoção eficiente de quadros redundantes em vídeos de endoscopia por cápsula sem fio
Engolir uma câmera, afogar-se em imagens
Imagine diagnosticar doenças intestinais engolindo uma câmera do tamanho de uma vitamina que fotografa silenciosamente todo o seu trato digestivo. A endoscopia por cápsula sem fio já torna isso possível, mas cada exame produz cerca de 55.000 imagens, a maioria quase idêntica. Os médicos precisam vasculhar essa enxurrada visual para identificar pequenos sinais de sangramento, inflamação ou tumores. O estudo por trás do MSRCTNet faz uma pergunta simples, porém crucial: um sistema inteligente pode descartar com segurança os quadros semelhantes, para que os médicos vejam apenas o que realmente importa?
Por que imagens demais podem ser um problema
A endoscopia convencional exige um tubo flexível passado pela boca ou pelo reto, um procedimento que muitos pacientes acham desconfortável e que nem sempre alcança todo o intestino delgado. A endoscopia por cápsula resolve isso permitindo que uma cápsula‑câmera percorra o intestino, tirando fotos a cada segundo. A desvantagem é a sobrecarga: apenas cerca de 1% dos quadros trazem informação claramente útil, enquanto o restante repete principalmente as mesmas pregas de tecido. Revisar esse volume é lento e cansativo, aumentando o risco de que um clínico exausto perca uma lesão sutil. Métodos computacionais anteriores tentaram ajudar agrupando quadros similares, comprimindo dados ou confiando em pistas simples de cor e textura, mas muitas vezes falhavam quando a iluminação mudava, o intestino se movia de forma complexa ou anomalias raras apareciam em apenas alguns exemplos.
Uma maneira mais inteligente de detectar repetição
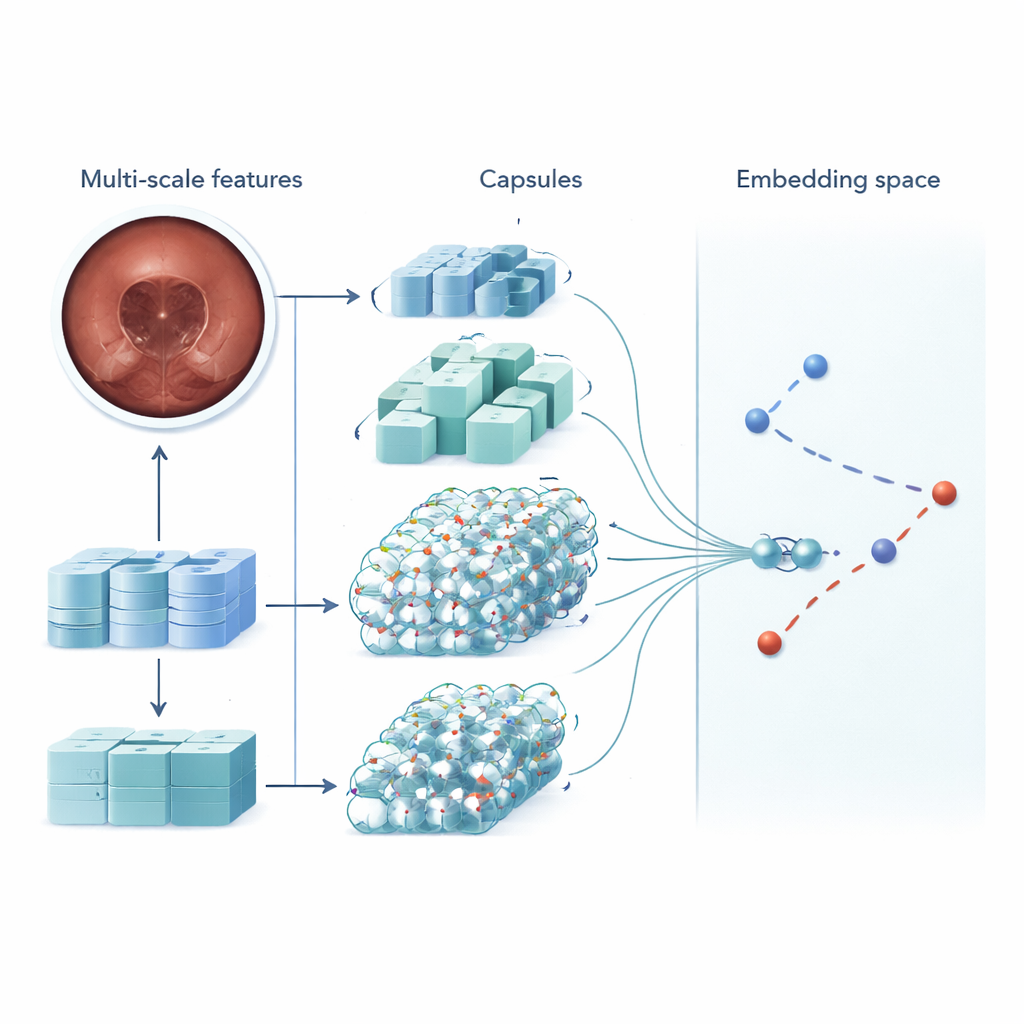
MSRCTNet (Multi‑Scale Capsule Triplet Network) é um sistema de aprendizado profundo projetado para atuar como um filtro inteligente para vídeos de cápsula. Em vez de tratar cada imagem apenas como uma fotografia plana, o sistema analisa padrões em múltiplas escalas simultaneamente — texturas finas do revestimento intestinal e formas mais amplas da parede intestinal — enquanto usa um mecanismo de atenção para enfatizar os detalhes mais informativos. Esses recursos enriquecidos são então encaminhados para uma camada estilo cápsula que preserva como as partes da imagem se relacionam espacialmente, como a orientação e a disposição de pregas ou lesões. Por fim, um módulo de similaridade especializado compara tríades de quadros — uma imagem de referência, uma que deveria ser similar e outra que deveria ser diferente — para aprender uma representação na qual quadros verdadeiramente redundantes formam aglomerados apertados e quadros distintivos ficam separados.
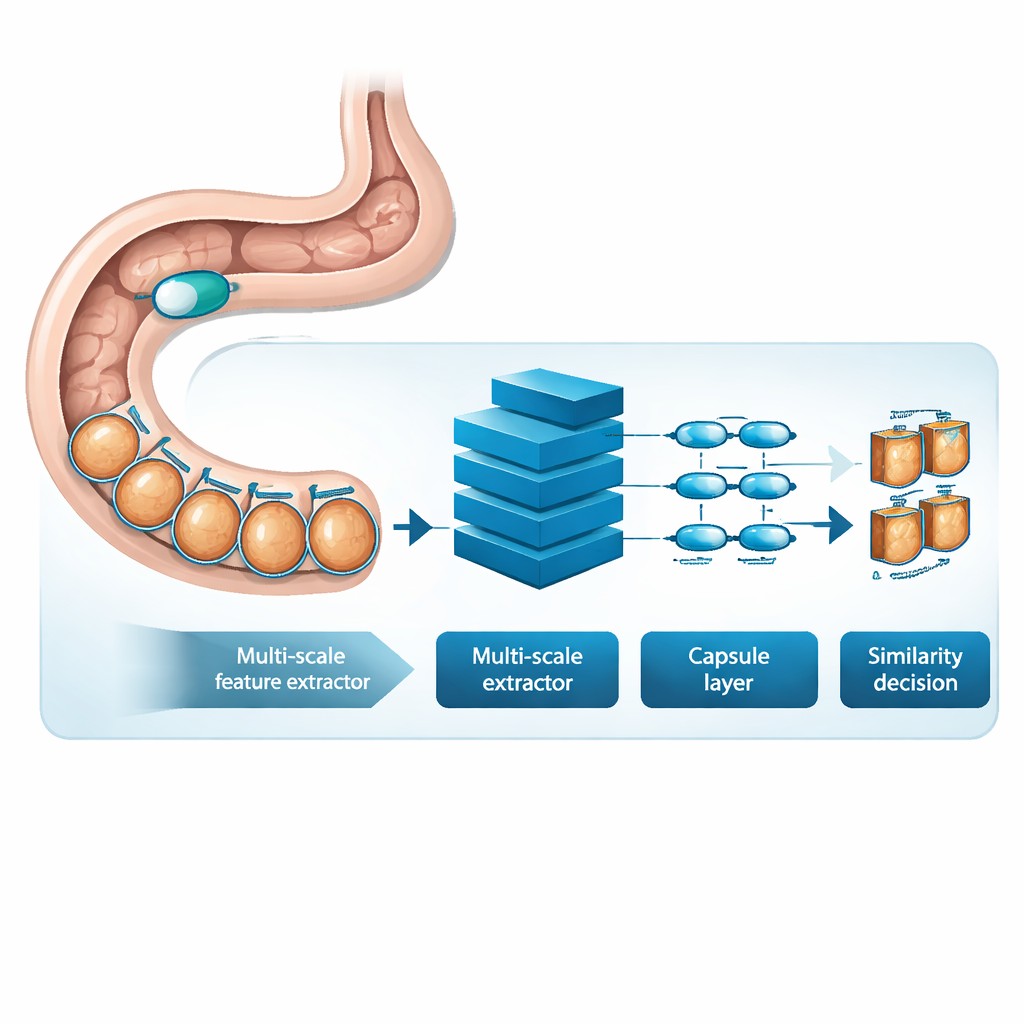
Aprendendo com exames reais de pacientes
Para testar o MSRCTNet, os pesquisadores reuniram um grande conjunto de dados com 257.362 imagens de 60 exames por cápsula realizados em um hospital na China. As imagens incluíam tecido normal, regiões obscurecidas por bolhas e anomalias claras, como sangramento e inflamação, todas rotuladas por clínicos experientes. O sistema foi treinado para julgar se pares de quadros eram similares ou não, usando uma combinação de dois objetivos de aprendizado: um que aproxima quadros da mesma categoria e afasta os de categorias diferentes, e outro que ensina a rede a declarar diretamente se um par é similar. Uma vez treinado, o modelo revisa o vídeo três quadros por vez e decide quais das imagens vizinhas são realmente redundantes. Aplicando regras simples a essas decisões de similaridade, ele descarta vistas repetidas enquanto mantém quadros-chave representativos.
Velocidade, precisão e menos problemas perdidos
Nos dados de teste, o MSRCTNet lidou corretamente com a redundância de quadros em cerca de 96% dos casos, com uma taxa de alarme falso abaixo de 3% e uma taxa de quadros perdidos inferior a 0,2%. Na prática, para um exame de 50.000 quadros isso corresponde a perder menos de 100 quadros potencialmente relevantes — pouco suficiente para que imagens vizinhas ainda forneçam contexto a seis quadros por segundo. Em comparação com várias técnicas anteriores baseadas em agrupamento, análise de movimento ou redes neurais mais simples, o MSRCTNet foi tanto mais preciso quanto mais robusto quando os dados eram desbalanceados, ou seja, quando imagens normais superavam em muito as lesões raras. O sistema também foi rápido: aproximadamente 0,02 segundos por quadro, ou cerca de 15 minutos para reduzir um exame completo a cerca de 2.500 quadros‑chave, um volume muito mais manejável para revisão humana.
O que isso significa para pacientes e médicos
Para os pacientes, o avanço descrito neste artigo não altera a cápsula que engolem, mas pode tornar o exame mais eficaz. Ao cortar automaticamente imagens quase duplicadas sem limiares ajustados manualmente ou heurísticas frágeis, o MSRCTNet permite que os clínicos concentrem sua atenção em um resumo conciso e rico em informação da jornada pelo intestino. A abordagem preserva achados clinicamente importantes enquanto reduz a fadiga e o tempo no console de leitura, potencialmente tornando os exames por cápsula não invasivos mais atraentes e mais amplamente utilizados. Em essência, o método transforma uma torrente de imagens em um roteiro cuidadosamente selecionado de destaques, aproximando a promessa da inteligência artificial do atendimento cotidiano das doenças digestivas.
Citação: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Palavras-chave: endoscopia por cápsula sem fio, sumarização de vídeo médico, aprendizado profundo, remoção de quadros redundantes, imagens do trato gastrointestinal