Clear Sky Science · pt
Impressão digital DNS baseada na atividade do usuário
Por que suas visitas à web deixam uma trilha oculta
Cada vez que você navega na web, seu computador silenciosamente consulta um tipo especial de lista de endereços, chamada Sistema de Nomes de Domínio (DNS), para saber como alcançar cada site. Essas consultas não desaparecem. Ao longo de dias e semanas, elas formam um padrão sobre que tipos de sites você visita, quando e com que frequência. Este artigo mostra que esses padrões são distintivos o suficiente para atuar como uma impressão comportamental, permitindo que algoritmos poderosos diferenciem usuários — mesmo que seu endereço IP visível mude — o que cria tanto oportunidades para segurança quanto questões sérias sobre privacidade.
A lista telefônica da internet e seus hábitos
O DNS existe para traduzir endereços da web legíveis por humanos, como www.google.com, para os endereços IP numéricos que os computadores usam para se comunicar. A maioria das pessoas nunca pensa nisso, mas toda busca, transmissão de vídeo, verificação de e‑mail ou atualização de aplicativo dispara uma ou mais consultas DNS. Essas consultas são tipicamente tratadas por servidores DNS locais ou públicos e registradas como registros simples: qual endereço IP perguntou sobre qual domínio e quando. Colete registros suficientes e você obtém uma imagem detalhada dos tipos de serviços online de que um usuário depende, desde ferramentas de trabalho e armazenamento em nuvem até redes sociais e plataformas de streaming. Enquanto pesquisas anteriores usaram esses rastros para detectar malware ou identificar tipos de dispositivos, este estudo coloca uma pergunta mais direta: eles conseguem identificar usuários ou máquinas apenas a partir de seu comportamento recorrente no DNS?
Transformando cliques diários em uma impressão comportamental
Os autores baseiam‑se em um grande conjunto de dados DNS disponível publicamente, coletado de um provedor de internet local ao longo de três meses. A cada dia, eles agregam a atividade DNS de cada endereço IP ativo em um resumo compacto: contagens de consultas totais, quantos domínios diferentes foram contatados e, crucialmente, como esses domínios se distribuem em 75 categorias de conteúdo, como “Negócios Gerais”, “Software / Hardware” ou “Redes Sociais”. Eles mantêm apenas endereços IP que aparecem em pelo menos 80% dos dias, garantindo histórico suficiente por usuário, e removem cuidadosamente características redundantes ou quase vazias. Também aplicam ferramentas estatísticas para detectar campos altamente correlacionados, filtrar outliers extremos no volume de consultas e então comprimem os dados com análise de componentes principais para que a maior parte da variação útil seja preservada em muito menos dimensões. Ao visualizar os dados limpos com uma técnica chamada t‑SNE, eles constatam que muitos endereços IP formam aglomerados estreitos e bem separados — um sinal inicial de que a classificação automática pode ser viável.
Colocando modelos de aprendizado de máquina à prova
Com esse conjunto de dados processado em mãos, a equipe trata a identificação de usuários como um enorme problema de classificação: dado um dia de estatísticas DNS, decidir a qual dos 1.727 endereços IP ele pertence. Eles comparam uma gama de modelos, desde métodos clássicos como Naive Bayes e Random Forests até ferramentas mais avançadas como XGBoost e redes neurais profundas. Cada modelo é treinado e validado em diferentes versões dos dados (brutos, redimensionados, padronizados ou com redução de dimensionalidade) e avaliado pela frequência com que atribui corretamente a classe certa, junto com medidas de precisão e recall. Modelos tradicionais apresentam desempenho razoável — Random Forests alcançam cerca de 73% de acurácia, e o XGBoost supera 81% enquanto distingue corretamente mais de 99% de todas as classes. Mas os destaques são as redes neurais, especialmente uma rede neural convolucional (CNN) personalizada que trata o vetor de características como uma imagem unidimensional do comportamento diário.
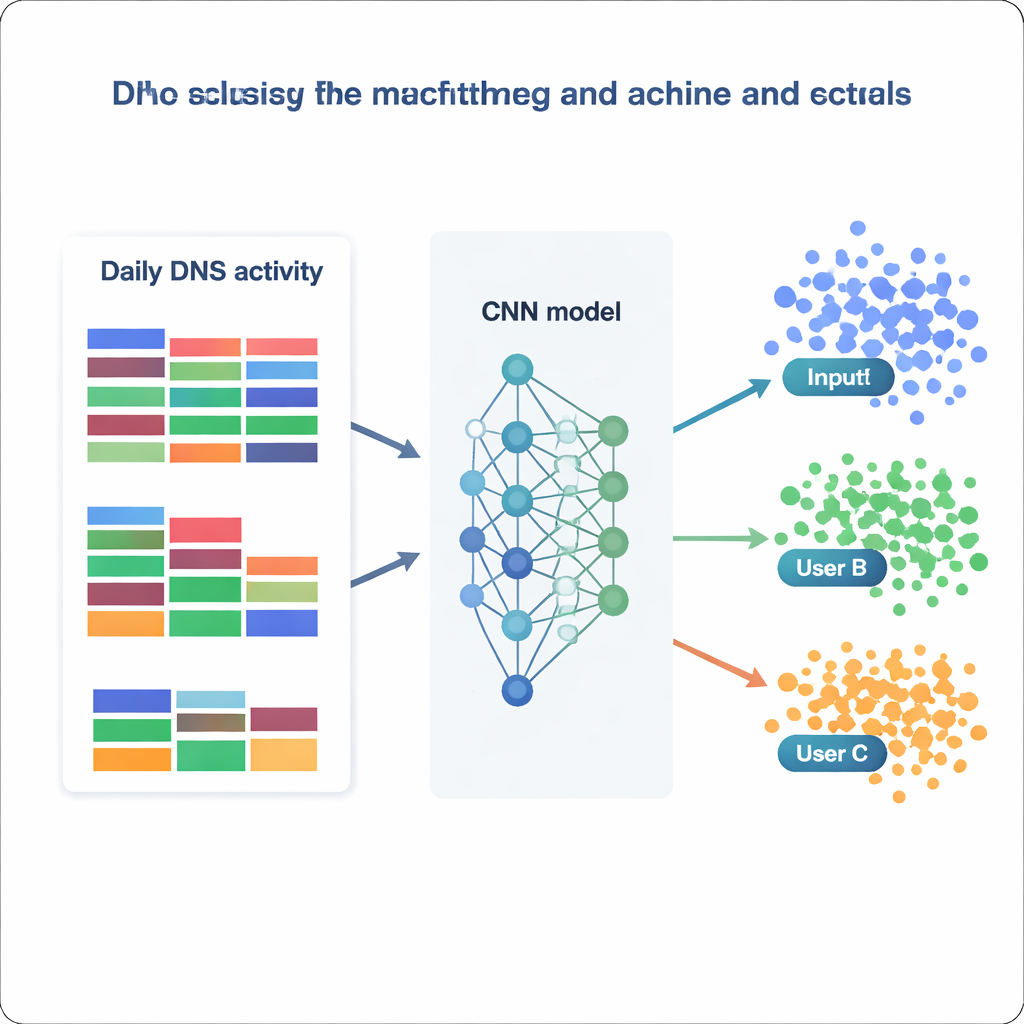
Quão bem um modelo pode saber “quem” você é?
A melhor CNN, treinada em dados normalizados, identifica corretamente o IP de origem em quase 87% dos dias reservados para teste e prevê com sucesso 1.694 dos 1.727 endereços IP distintos. Em termos práticos, isso significa que a maioria dos usuários — ou pequenos grupos ocultos atrás de um IP compartilhado — exibe padrões DNS estáveis e reconhecíveis ao longo do tempo. Ao examinar em quais características os modelos mais se apoiam, os autores encontram duas estratégias complementares. Alguns modelos se baseiam fortemente em categorias muito comuns, como negócios gerais ou serviços de software, capturando hábitos amplos. Outros, como o XGBoost, ganham poder extra com categorias raras, porém reveladoras, ligadas a segurança, política ou interesses nicho. Juntos, esses resultados mostram que mesmo estatísticas agregadas simples — sem olhar para a lista completa de nomes de domínio — podem codificar estrutura suficiente para reidentificar usuários com notável confiabilidade.
Promessas, limites e riscos para a privacidade
Para a aplicação da lei e defensores de redes, impressões digitais DNS podem se tornar uma ferramenta valiosa para rastrear reincidentes, identificar máquinas comprometidas ou detectar botnets que usam endereços IP alternados para evitar bloqueios. Ao mesmo tempo, o estudo destaca limites claros: impressões digitais de DNS são mais estáveis quando um IP público está vinculado a um único usuário, o que é mais realista em redes IPv6 modernas do que no mundo IPv4 atual, onde muitos usuários compartilham um endereço via NAT. Trocas frequentes de servidores DNS ou o uso de Wi‑Fi público também enfraquecem o sinal. Mais importante, o trabalho sublinha um risco de privacidade que é difícil para usuários comuns perceberem. Como o registro de DNS é em grande parte invisível e passivo, o rastreamento comportamental pode acontecer sem instalar cookies ou scripts intrusivos. Os autores liberam abertamente seu conjunto de dados e modelos, argumentando que pesquisas transparentes são necessárias para que a sociedade pondere os benefícios de segurança da impressão digital baseada em DNS frente ao seu potencial para vigilância silenciosa e decida quais proteções e políticas devem regular essa nova e poderosa forma de identificação online.
Citação: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Palavras-chave: Impressão digital DNS, rastreamento de usuários, privacidade na internet, segurança de rede, aprendizado de máquina