Clear Sky Science · pt
Super-resolução de faces no mundo real baseada em redes adversariais geradoras e de alinhamento facial
Faces mais nítidas a partir de fotos borradas
Quem já tentou ampliar o rosto em um vídeo antigo de segurança ou numa foto pequena de rede social conhece a frustração: quanto mais se amplia, mais o rosto vira um borrão em blocos. Este artigo apresenta uma nova abordagem de inteligência artificial que pode transformar imagens faciais de baixa qualidade do mundo real em versões muito mais claras, preservando melhor a identidade e a expressão da pessoa. Isso tem implicações óbvias para câmeras de segurança, perícia fotográfica e até aplicativos cotidianos de melhoria de imagens.
Por que faces borradas são tão difíceis de corrigir
Fazer uma imagem pequena e desfocada de um rosto parecer nítida não é apenas uma questão de “adicionar pixels”. Métodos tradicionais dependiam de regras manuais ou padrões simples, e técnicas mais recentes de deep learning frequentemente aprendem a partir de imagens degradadas artificialmente: pega-se um rosto limpo em alta resolução, desfoca-se e reduz-se, e então ensina-se uma rede a reverter o processo. O problema é que imagens do mundo real — como as de câmeras de vigilância ou vídeos comprimidos — são degradadas de maneiras confusas e imprevisíveis. O desfoque, o ruído e os artefatos de compressão raramente casam com os exemplos sintéticos usados no treinamento, então modelos que se saem bem em laboratório frequentemente falham em filmagens reais. Pior: podem produzir rostos que parecem plausíveis, mas já não se parecem com a pessoa original.
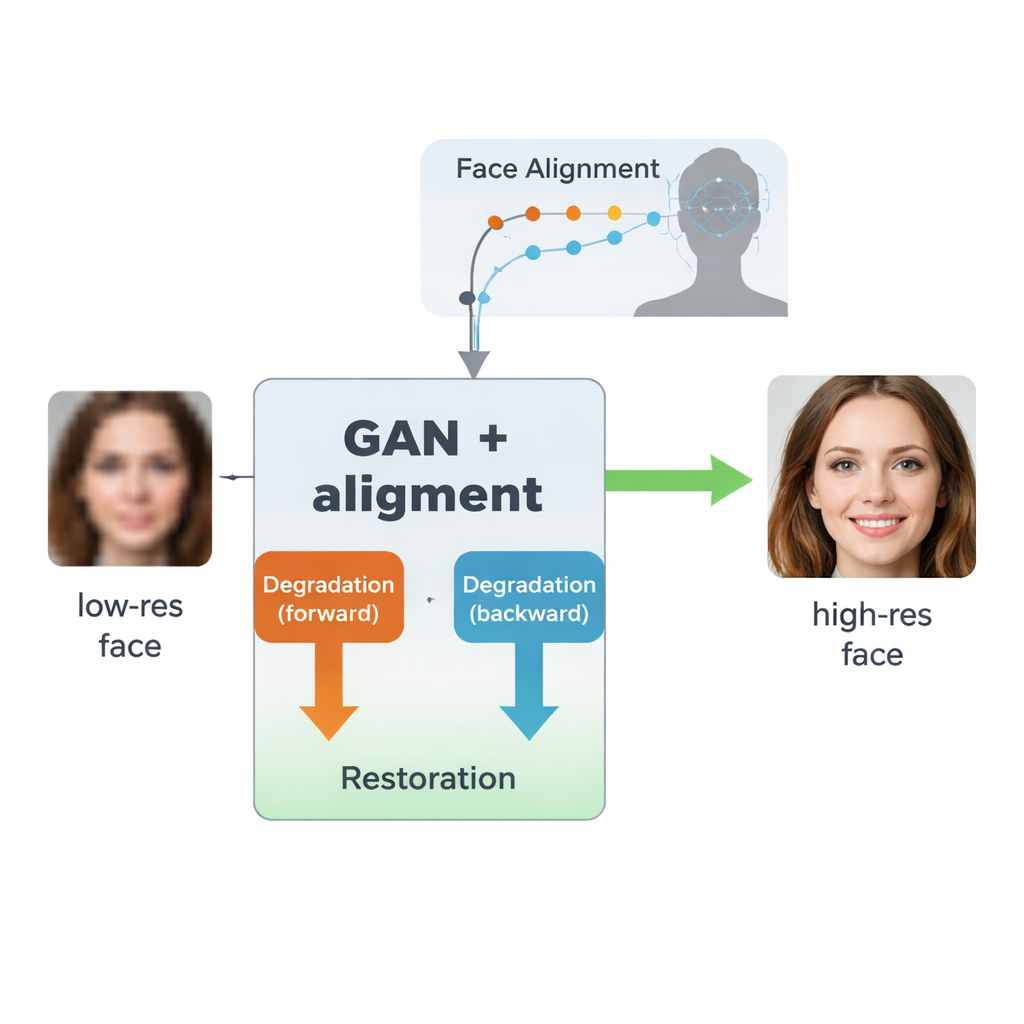
Um ciclo de aprendizado em duas direções para imagens do mundo real
Os autores partem de um tipo de IA chamado rede adversarial generativa (GAN), que aprende a criar imagens realistas colocando duas redes neurais em competição: uma gera imagens, a outra avalia quão reais elas parecem. O projeto deles, inspirado por um modelo anterior chamado SCGAN, usa uma estrutura “semi-ciclo” com dois laços complementares. No laço direto, rostos reais em alta resolução são intencionalmente degradados por um ramo para produzir versões sintéticas em baixa resolução, e então restaurados por um ramo de restauração compartilhado. No laço inverso, rostos realmente de baixa qualidade do mundo real são melhorados por esse mesmo ramo de restauração e então degradados novamente por outro ramo para se assemelharem a imagens reais de baixa resolução. Ao forçar consistência em ambas as direções — degradar e depois restaurar, ou restaurar e depois degradar — o sistema aprende um modelo realista de como os rostos são danificados na prática e como reverter esse processo sem jamais precisar de pares perfeitamente correspondentes de imagens reais em baixa e alta qualidade.
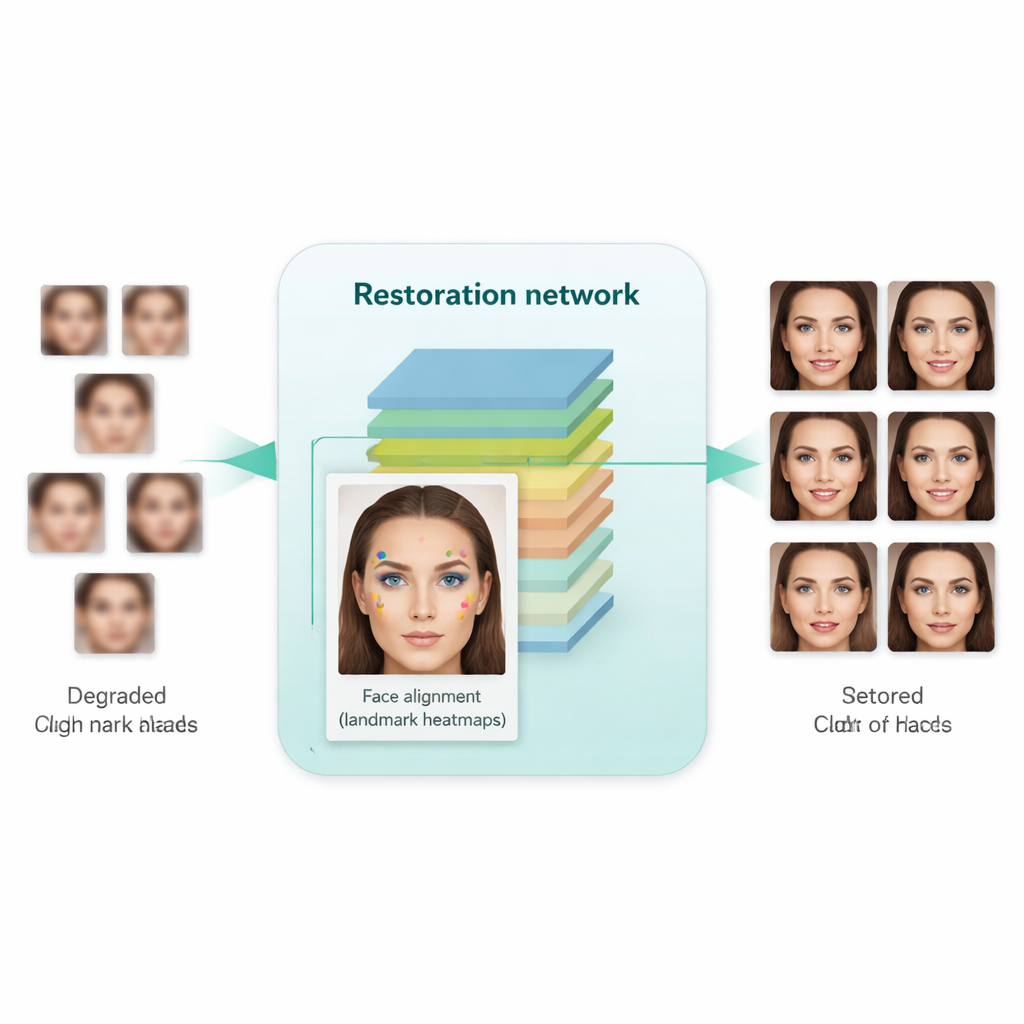
Ensinando à rede como um rosto realmente é
Uma inovação-chave neste trabalho é ensinar o sistema não apenas a deixar as imagens mais nítidas, mas a respeitar a estrutura subjacente do rosto humano. Para isso, os autores integram uma rede de alinhamento facial separada, originalmente projetada para localizar pontos de referência como cantos dos olhos, ponta do nariz e contorno da boca. Essa rede de alinhamento prevê “mapas de calor” que destacam onde cada referência deveria estar. Durante o treinamento, o modelo compara os mapas de calor da imagem restaurada com os de um rosto real em alta resolução da mesma pessoa e penaliza discrepâncias. Crucialmente, isso usa um modelo de alinhamento pré-treinado e não requer rótulos manuais de pontos para cada imagem de treinamento. O resultado é uma espécie de orientação geométrica: a rede de aprimoramento é orientada a posicionar olhos, nariz e boca nas posições e formas corretas, em vez de simplesmente pintar a borrão com texturas genéricas parecidas com rosto.
Quão bem isso funciona na prática?
Os pesquisadores treinaram seu sistema em uma grande coleção de rostos de alta qualidade e em um conjunto separado de rostos genuinamente de baixa qualidade provenientes de bases de dados do mundo real. Eles então testaram tanto em benchmarks sintéticos (onde imagens limpas de referência estão disponíveis) quanto em imagens do mundo real (onde apenas o realismo visual e medidas estatísticas podem ser usadas). Em comparação com métodos anteriores — incluindo ferramentas conhecidas como Real-ESRGAN, GFPGAN e o SCGAN original — a nova abordagem produziu imagens que não só pareciam mais naturais e menos distorcidas, mas também levaram a melhor desempenho em tarefas práticas. Quando as imagens aprimoradas foram processadas por detectores faciais padrão e por um modelo popular de reconhecimento facial (FaceNet), a precisão de detecção e verificação melhorou de maneira perceptível, indicando que detalhes relacionados à identidade foram melhor preservados. Ao mesmo tempo, métricas automáticas de qualidade sugeriram que os rostos gerados estavam mais próximos, em distribuição, de fotos reais em alta resolução.
O que isso significa para o uso cotidiano
Em termos simples, este trabalho mostra que é possível obter rostos mais nítidos e mais confiáveis a partir de imagens de baixa qualidade combinando duas ideias: aprender um modelo realista de como imagens são degradadas no mundo real e usar informações de marcos faciais para manter a estrutura do rosto intacta. Em vez de meramente “chutar” um rosto com melhor aparência, o sistema é guiado a reconstruir a pessoa correta com olhos, boca e formato geral mais claros. Isso torna o método especialmente promissor para aplicações como segurança, perícia e restauração de acervos, onde tanto a clareza visual quanto a identidade correta são críticas e onde versões originais em alta qualidade raramente estão disponíveis.
Citação: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Palavras-chave: super-resolução de faces, redes adversariais generativas, alinhamento facial, reconhecimento facial, restauração de imagem