Clear Sky Science · pt
Pipeline de processamento de imagens para caracterização por IA de megalibraries de nanopartículas
Por que Partículas Minúsculas Precisam de Ajuda de Big Data
A ciência dos materiais moderna depende cada vez mais de fabricar e testar enormes quantidades de partículas minúsculas para descobrir catalisadores, baterias e outros materiais avançados melhores. Novos métodos agora podem crescer milhões de nanopartículas diferentes em um único chip, mas verificar a qualidade de cada uma por meio de um microscópio produz muito mais imagens do que qualquer humano pode revisar razoavelmente. Este artigo descreve como os pesquisadores construíram um pipeline automatizado de processamento de imagens e IA que classifica rapidamente imagens de nanopartículas como “boas” ou “ruins”, reduzindo custos de computação e acelerando experimentos enquanto mantém as decisões altamente confiáveis.
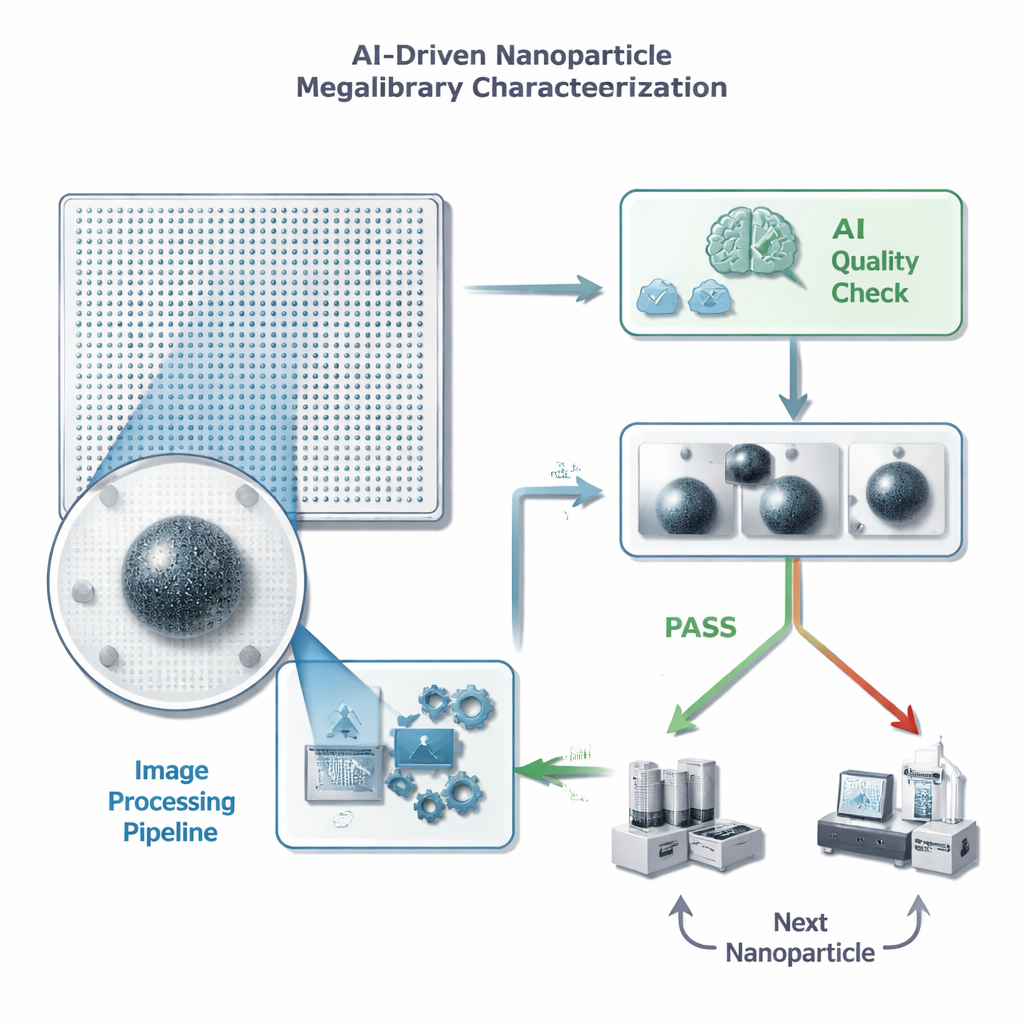
De Imagens Infinitas a Decisões Rápidas
Cada nanopartícula em um chip “megalibrary” ocupa uma posição conhecida e pode ser imageada por um microscópio eletrônico. Antes que os cientistas invistam tempo e medições de acompanhamento caras em qualquer partícula, precisam de uma checagem rápida de qualidade: existe exatamente uma partícula bem focalizada no quadro, sem elementos distrativos ou artefatos? Os autores enquadram isso como uma tarefa simples de aprovar/reprovar para um modelo de aprendizado de máquina, mas com limites rígidos sobre quanto tempo pode gastar por imagem — menos de meio segundo, porque um único chip pode conter milhões de partículas. Eles também enfatizam que falsos positivos são especialmente prejudiciais: se a IA aprovar por engano uma imagem ruim, isso desperdiça tempo e armazenamento em medições detalhadas inúteis, enquanto a eventual perda de uma partícula boa é menos danosa ao progresso geral.
Limpeza da Imagem Antes que a IA Olhe
Em vez de jogar imagens brutas e ruidosas do microscópio diretamente em uma rede neural grande e complexa, a equipe projetou um pipeline de processamento de imagem personalizado que “limpa” as fotos antes. O pipeline remove ruído de fundo, realça bordas, recorta apertadamente em torno da partícula e então reduz a imagem para um tamanho bem menor. Crucialmente, esse pré-processamento torna características tênues mais fáceis de ver e imita a aparência de uma imagem com maior ampliação sem realmente reimaginar a amostra. O resultado é uma imagem compacta e de alto contraste que pode ser alimentada a uma rede neural relativamente simples, reduzindo tanto o tempo de treinamento quanto as necessidades de armazenamento, ao mesmo tempo em que preserva os detalhes que importam para julgamentos de qualidade.
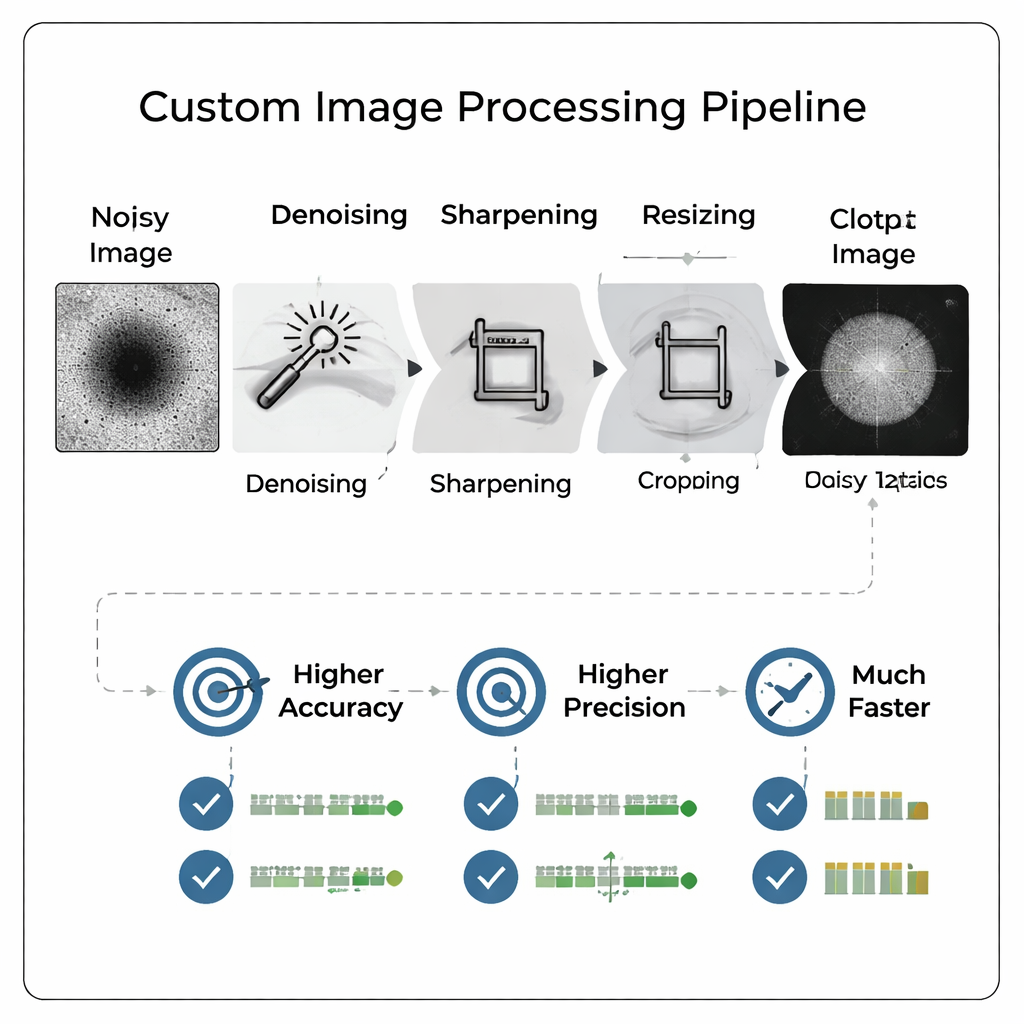
Imagens Mais Inteligentes Superam Modelos Maiores
Os pesquisadores compararam rigorosamente muitas variantes do pipeline e resoluções, treinando no fim 800 modelos diferentes para ver como tamanho e processamento da imagem afetam o desempenho. Eles descobriram que imagens cuidadosamente processadas em resoluções moderadas (como 128×128 pixels) permitiram que uma pequena rede neural convolucional superasse um modelo anterior muito maior que havia sido descoberto por busca automatizada de arquitetura e treinado em imagens completas de 512×512. A acurácia melhorou em mais de 13 pontos percentuais, enquanto o recall — a capacidade de capturar corretamente as partículas boas — aumentou em mais de 18 pontos percentuais. A precisão, a medida-chave para evitar esforço desperdiçado em partículas ruins, alcançou cerca de 96%, e a métrica combinada de desempenho preferida pelos autores também melhorou.
Fazer Mais com Muito Menos Dados
Um dos resultados mais impressionantes é que o processamento importa mais do que o tamanho bruto da imagem. Quando a equipe comparou modelos treinados em imagens simplesmente “reduzidas” versus aqueles usando o pipeline personalizado completo, as imagens processadas venceram consistentemente — mesmo quando encolhidas a tamanhos extremamente pequenos como 16×16 pixels. De fato, o melhor modelo usando imagens processadas de 16×16 superou o melhor modelo usando imagens não processadas de 128×128 em quase todas as métricas. O pipeline também ajudou mais em ampliações mais baixas do microscópio, onde as imagens normalmente são mais difíceis de interpretar. Como imagens em ampliação menor são mais rápidas de adquirir, isso significa que os laboratórios podem escanear chips mais rapidamente sem sacrificar a qualidade das decisões.
Decisões Mais Rápidas para Laboratórios Autônomos
Ao combinar processamento de imagem inteligente com um modelo de IA enxuto, os autores reduziram tempos de treinamento de muitas horas em um supercomputador para menos de um minuto em um único processador gráfico. Uma vez treinado, o sistema pode processar e classificar uma nova imagem em cerca de 75 milissegundos, bem abaixo da meta de 500 milissegundos e muito mais rápido que um revisor humano. Em termos práticos, isso se traduz em triagem rápida e confiável de megalibraries de nanopartículas, ajudando pesquisadores a direcionar instrumentos caros para os candidatos mais promissores. À medida que os laboratórios avançam para sistemas de descoberta mais automatizados e “autônomos”, abordagens como esta — limpar os dados primeiro, depois aplicar IA enxuta — oferecem uma maneira poderosa de transformar fluxos de imagens avassaladores em insight científico acionável.
Citação: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
Palavras-chave: nanopartículas, processamento de imagens, aprendizado de máquina, descoberta de materiais, microscopia eletrônica