Clear Sky Science · pt
Pesquisa sobre módulos plug-and-play de aprimoramento de correlação de rótulos em aprendizado profundo multilabel
Ensinando máquinas a lidar com tags demais
Lojas online, arquivos jurídicos e bases de dados médicas dependem de softwares que possam rapidamente etiquetar cada novo documento com os rótulos corretos. Mas sistemas modernos frequentemente enfrentam dezenas de milhares, ou até milhões, de possíveis etiquetas — de categorias de produto a assuntos médicos — enquanto cada texto precisa de apenas um punhado delas. Este artigo apresenta um novo complemento, chamado Label Correlation Enhancement Network (LCENet), que ajuda modelos de aprendizado profundo existentes a aproveitar melhor o modo como os rótulos aparecem juntos nos dados reais, levando a marcações de texto mais precisas e mais rápidas.
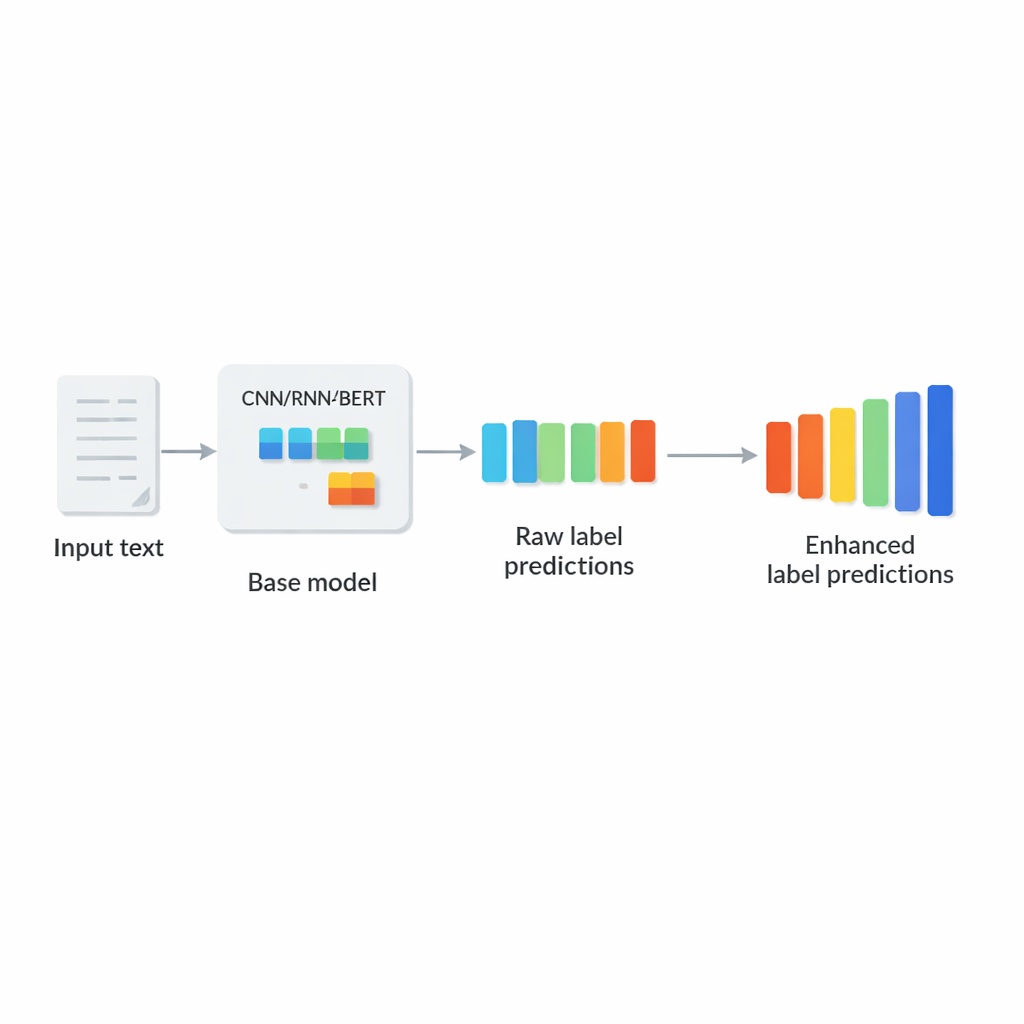
Por que rotular em escala web é tão difícil
Muitas aplicações do mundo real se enquadram no que pesquisadores chamam de classificação de texto multilabel extrema: dado uma descrição curta ou um documento longo, o sistema deve escolher um pequeno subconjunto de rótulos relevantes a partir de um catálogo enorme. Exemplos incluem atribuir categorias a produtos em um site de comércio eletrônico, indexar artigos biomédicos com termos MeSH, casar anúncios com páginas da web ou mapear textos legais a códigos jurídicos detalhados. Esses cenários compartilham três desafios: a lista de rótulos é extremamente grande, a maioria dos rótulos é rara e qualquer texto usa apenas alguns rótulos. Técnicas tradicionais ou dividem o problema em muitos classificadores pequenos ou comprimem os rótulos em vetores de dimensão reduzida, mas frequentemente dependem de contagens simples de palavras e não conseguem captar totalmente o significado ou as relações entre rótulos.
O que os modelos profundos padrão ainda deixam passar
Abordagens modernas de aprendizado profundo, como redes convolucionais, redes recorrentes e modelos baseados em Transformer como o BERT, melhoraram muito a compreensão de texto ao aprender representações semânticas ricas. Ainda assim, quase todos eles fazem uma simplificação crucial na etapa final: uma vez que o texto é codificado em um vetor, eles prevêem cada rótulo de forma independente. Na prática, entretanto, os rótulos interagem fortemente. Um artigo médico rotulado com “diabetes” tem maior probabilidade de também envolver “resistência à insulina”, e um dispositivo rotulado como “smartphone” costuma estar relacionado a “eletrônicos” e “dispositivos de comunicação”. Ignorar esses padrões faz com que os modelos não usem rótulos de alta confiança para apoiar outros mais fracos, e podem até gerar combinações que não fazem sentido juntas.
Um plug-in que aprende relações entre rótulos
Os autores propõem o LCENet como um módulo leve, plug-and-play, que se posiciona após qualquer classificador de texto profundo existente. Em vez de mudar como o modelo base lê o texto, o LCENet pega as pontuações brutas de rótulos que ele produz e as passa por um “gargalo” compacto que força o sistema a descobrir uma representação de baixa dimensão onde rótulos relacionados se agrupam. Funções de ativação não lineares permitem então que o módulo capture associações complexas de ordem superior, não apenas ligações pareadas simples. Uma conexão residual, ou de atalho, envia as pontuações originais diretamente à saída junto com as pontuações corrigidas, o que estabiliza o treinamento e garante que o complemento não possa facilmente piorar o desempenho. Crucialmente, o LCENet reduz o número de parâmetros extras de algo que cresceria com o quadrado do número de rótulos para um crescimento muito mais administrável e linear, de modo que permanece viável mesmo para centenas de milhares de rótulos.
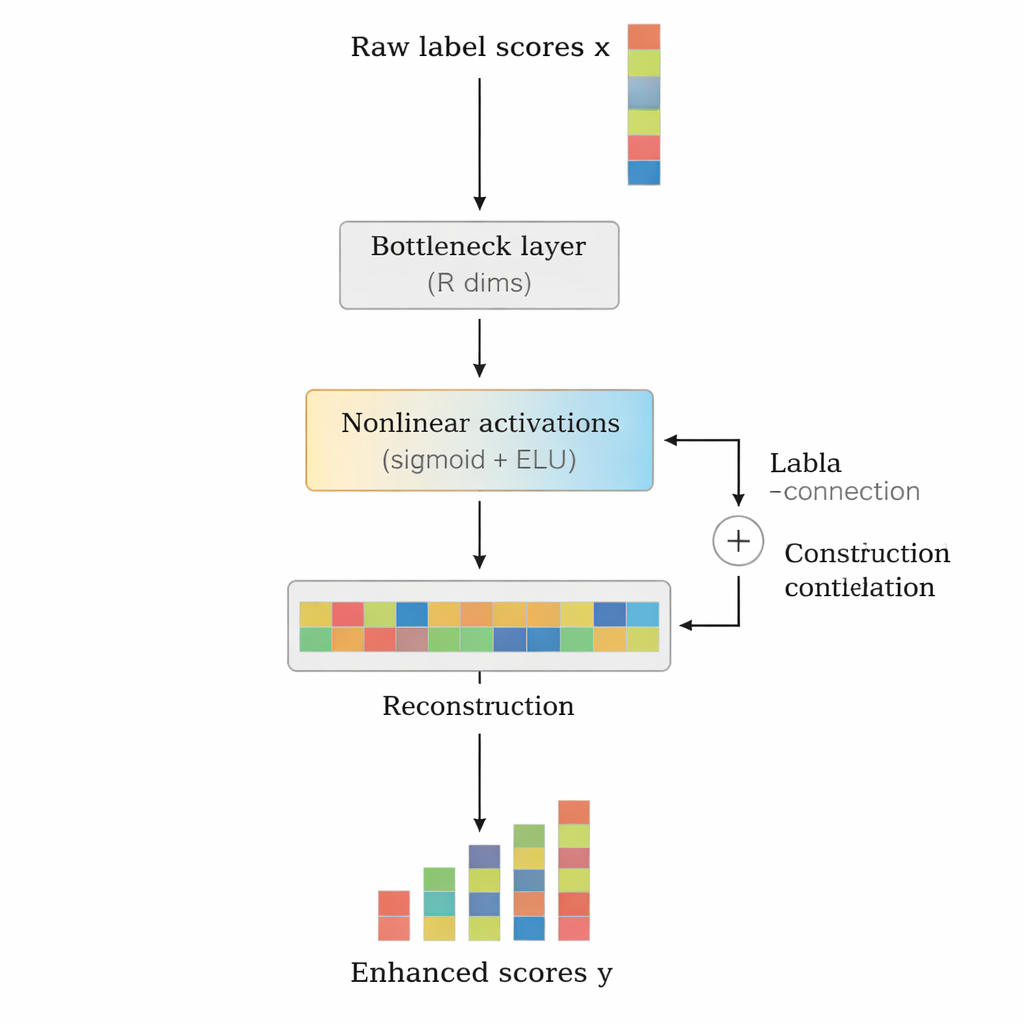
Demonstrando os benefícios através de modelos e conjuntos de dados
Para testar se o LCENet é realmente geral, os autores o acoplaram a quatro modelos profundos bem diferentes, incluindo arquiteturas baseadas em CNN e em BERT, assim como sistemas projetados especificamente para cenários biomédicos e de rótulos extremos. Eles avaliaram essas combinações em três conjuntos de benchmark públicos: um corpus jurídico europeu (EUR-Lex), um conjunto de produtos da Amazon (AmazonCat-13K) e uma coleção massiva da Wikipedia com mais de meio milhão de rótulos (Wiki-500K). Em todos os modelos, conjuntos de dados e seis métricas focadas em ranqueamento, o LCENet melhorou o desempenho de forma consistente, às vezes elevando a precisão top-1 em mais de cinco pontos percentuais no maior conjunto. Curvas de treinamento mostraram ainda que o LCENet frequentemente reduz pela metade o número de passos de treinamento necessários para atingir uma dada acurácia, porque a estrutura adicional de correlação de rótulos fornece sinais de aprendizado mais claros desde o início.
Por que isso importa para sistemas do dia a dia
Para praticantes que já dependem de modelos profundos para etiquetar textos, o LCENet oferece uma forma prática de aumentar a precisão e a velocidade de treinamento sem redesenhar seus sistemas ou coletar novos tipos de anotações. Ele trata o espaço de rótulos em si como uma fonte de conhecimento, aprendendo quais tags tendem a ocorrer juntas ou a se excluir mutuamente, e então ajustando as previsões de acordo. Embora desenvolvido para texto, a mesma ideia de aprimorar previsões usando relações aprendidas entre as saídas pode ser aplicada a imagens, dados multimodais e outras tarefas de predição estruturada. Em termos simples, o LCENet ajuda as máquinas a “lembrar” como os rótulos se relacionam, para que adivinhem menos como caixas isoladas e mais como um humano conhecedor que entende como conceitos se encaixam.
Citação: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Palavras-chave: classificação de texto multilabel extrema, correlação de rótulos, aprendizado profundo, classificação de texto, redes neurais