Clear Sky Science · pt
Incerteza e histórico de recompensas têm efeitos distintos nas decisões após vitórias e derrotas
Por que vitórias e derrotas não nos ensinam da mesma forma
Cada dia tomamos decisões com base em vitórias e derrotas passadas, seja ao escolher uma ação ou ao decidir a rota para o trabalho. Ainda assim, humanos e animais costumam aprender mais com o sucesso do que com o fracasso. Este artigo explora por que esse desequilíbrio não é apenas uma peculiaridade, mas uma estratégia adaptativa moldada por como nossos cérebros acompanham o histórico de recompensas e a incerteza. Ao estudar ratos em um ambiente mutável e parcialmente imprevisível, os pesquisadores revelam regras ocultas que determinam quando vitórias importam mais do que derrotas — e como essas regras diferem entre machos e fêmeas.
Um mundo em mudança para ratos sedentos
Para investigar essas regras, a equipe treinou ratos com restrição hídrica em uma tarefa de escolha dinâmica. Em cada tentativa, os ratos iniciavam uma rodada e então escolhiam entre duas alavancas. Uma alavanca tinha maior probabilidade de oferecer uma gota de água açucarada, mas qual alavanca era “melhor” e o quanto ela era melhor mudava em blocos ao longo da sessão. Alguns blocos tornavam a alavanca superior muito óbvia (um lado recompensava na maior parte do tempo, o outro quase nunca), enquanto outros blocos eram mais confusos, com chances de recompensa mais próximas ou até iguais nas duas alavancas. Essa configuração em constante mudança imita a vida real, onde o que funcionou ontem pode não funcionar hoje.
Seguir vencedores, ignorar algumas derrotas
Ao longo de centenas de sessões, os ratos tendiam a repetir uma escolha após uma vitória ("win-stay") com mais frequência do que mudavam após uma derrota ("lose-shift"). Isso confirmou uma forte inclinação a aprender com o sucesso. O padrão ficou especialmente claro quando os ratos tiveram tempo dentro de um bloco para descobrir qual alavanca costumava ser melhor. Nesses ensaios posteriores, eles não apenas permaneceram mais após vitórias, mas também eram menos propensos a abandonar a alavanca melhor após uma perda rara. Essa estratégia os ajudou a continuar explorando a opção mais recompensadora em vez de serem enganados por um resultado ruim ocasional que pode ocorrer mesmo com uma boa escolha. Os machos mostraram esse viés de forma mais acentuada que as fêmeas: eram mais propensos a permanecer após vitórias e menos propensos a mudar após derrotas.
Sinais ocultos: incerteza e histórico de recompensa
Para entender os cálculos invisíveis por trás desse comportamento, os autores usaram modelos de aprendizado por reforço — algoritmos de computador que atualizam expectativas com base no feedback. Eles focaram em dois sinais internos. O primeiro foi uma medida de "histórico de incerteza": uma média dos níveis recentes de surpresa, que captura o quão imprevisíveis os resultados vinham sendo. Quando esse número era alto, o ambiente era efetivamente mais turvo. O segundo foi um "estado global de recompensa", um resumo suavizado de quão rico ou pobre o ambiente recente parecia no geral. Juntos, esses sinais permitiam aos ratos estimar tanto o quão ruidoso o mundo estava quanto quão bem as coisas vinham indo ultimamente, e ajustar quanto peso dar à vitória ou à derrota mais recente.
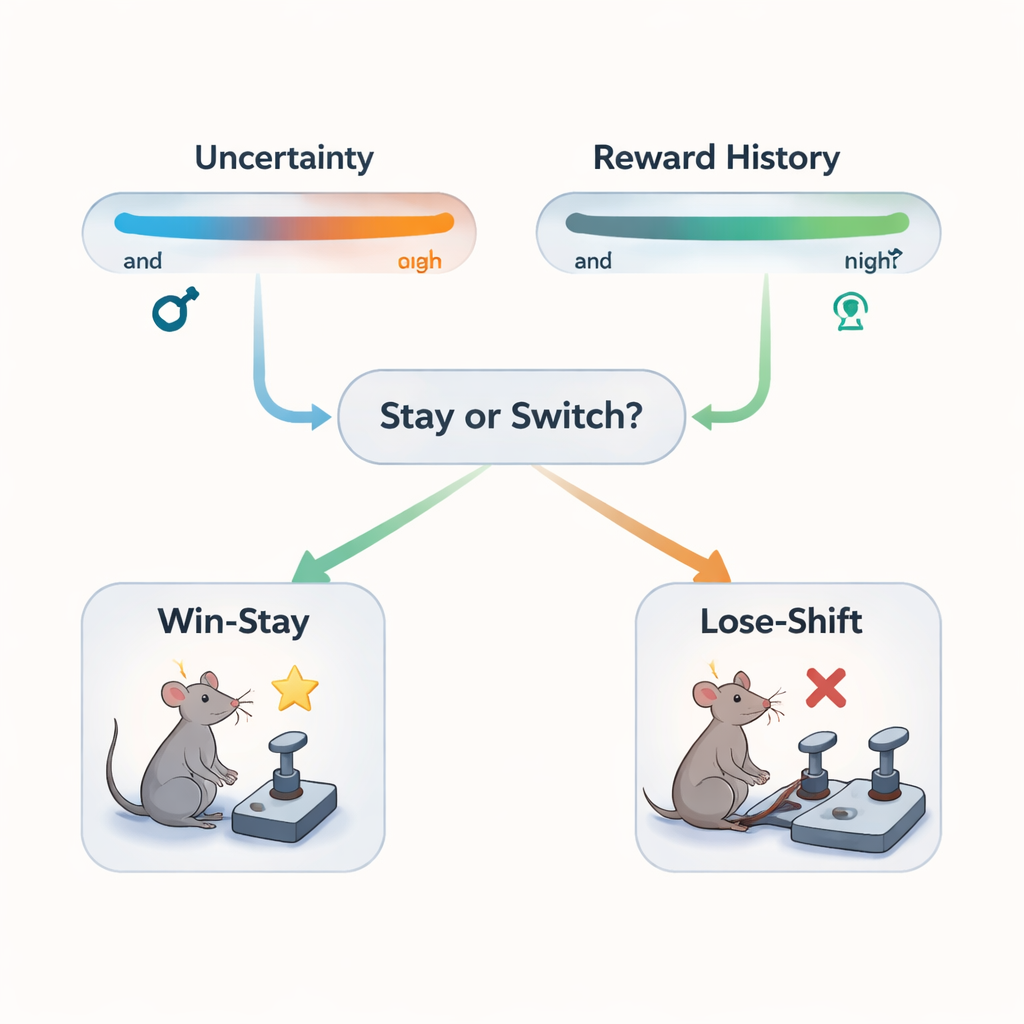
Quando imprevisibilidade e abundância moldam escolhas
Os dois sinais internos influenciaram o comportamento de maneiras distintas e às vezes específicas por sexo. Os ratos eram mais propensos a permanecer após uma vitória e menos propensos a abandonar a alavanca melhor quando a incerteza era baixa — isto é, quando o padrão do ambiente estava mais claro. Sob alta incerteza, eles tendiam a mudar de uma boa alavanca após uma perda, sugerindo que condições confusas podem desencadear comportamento mais cauteloso. Enquanto isso, um alto estado global de recompensa, refletindo uma sequência geralmente boa de resultados, encorajava os ratos a continuar permanecendo após vitórias e reduzia a tendência de mudar após derrotas, mesmo quando o ambiente era um pouco ruidoso. As decisões baseadas em vitórias dos machos foram especialmente moldadas por seu histórico de incerteza, enquanto as fêmeas se apoiaram de forma mais consistente no estado global de recompensa.
O que isso significa para decisões do dia a dia
Para o público geral, a mensagem central é que “aprender mais com vitórias do que com derrotas” não é simplesmente otimismo excessivo. O estudo mostra que ratos — e provavelmente humanos — ajustam dinamicamente o quanto dão atenção a vitórias e derrotas com base em quão previsível e quão recompensador o mundo tem parecido recentemente. Quando as regras parecem claras e as recompensas são abundantes, pode ser sensato confiar nas vitórias e desconsiderar falhas ocasionais. Quando as coisas parecem caóticas ou escassas, dar mais peso às derrotas pode ajudar a evitar escolhas ruins. O trabalho também revela que machos e fêmeas podem seguir as mesmas regras de tarefa usando equilíbrios internos ligeiramente diferentes entre incerteza e histórico de recompensa, um insight que pode ajudar a explicar diferenças sexuais na vulnerabilidade a condições como dependência ou depressão, nas quais o aprendizado a partir de recompensa e punição se altera.
Citação: Kalhan, S., Magnard, R., Zhang, Z. et al. Uncertainty and reward histories have distinct effects on decisions after wins and losses. Sci Rep 16, 6795 (2026). https://doi.org/10.1038/s41598-026-37554-3
Palavras-chave: aprendizado por reforço, tomada de decisão, incerteza, histórico de recompensas, diferenças sexuais