Clear Sky Science · pt
DMSCA: atenção dinâmica multiescala canal-espacial para representação de recursos aprimorada em redes neurais convolucionais
Ensinando Computadores a Prestar Mais Atenção
Sistemas modernos de reconhecimento de imagens conseguem identificar gatos, sinais de trânsito e tumores em exames—mas nem sempre sabem em que se concentrar dentro de uma imagem. Este artigo apresenta uma nova maneira de ajudar esses sistemas a focalizar as partes mais importantes de uma imagem, melhorando a precisão e tornando-os mais confiáveis nas condições desordenadas do mundo real. O método, chamado Atenção Dinâmica Multiescala Canal-Espacial (DMSCA), conecta-se a redes neurais convolucionais existentes e as ajuda a perceber tanto o “o quê” quanto o “onde” em uma imagem de forma mais inteligente.
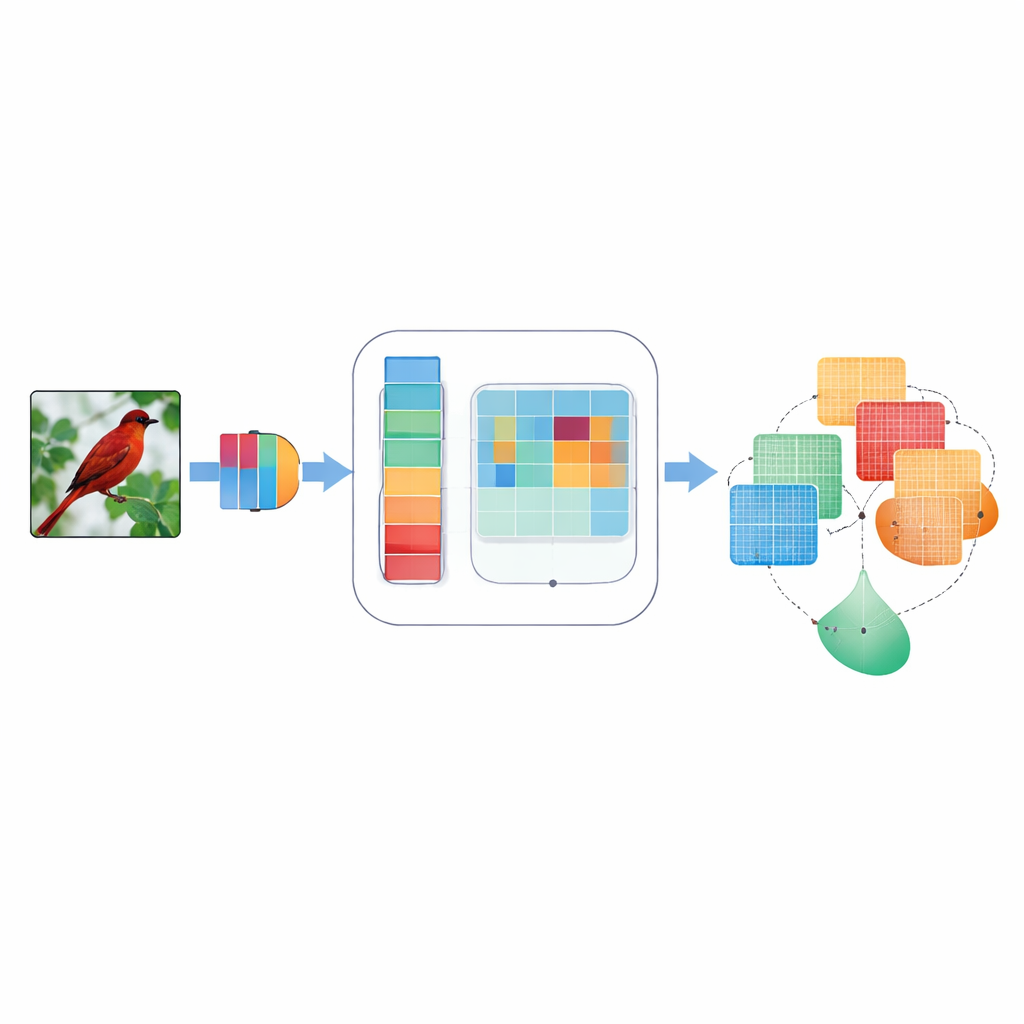
Por que Focar é Importante para a Visão de Máquina
Redes neurais convolucionais, os pilares por trás de muitas aplicações de visão, normalmente tratam cada sinal interno como igualmente importante. Isso significa que a borda sutil da asa de um pássaro e um pedaço de céu podem receber atenção semelhante, mesmo que apenas um deles ajude a identificar a espécie. Métodos de “atenção” anteriores tentaram corrigir isso ponderando alguns sinais internos mais do que outros—seja através de canais semelhantes a cores, seja através da disposição bidimensional da imagem. Mas esses métodos frequentemente usavam regras fixas e projetadas manualmente, olhavam apenas uma escala de detalhe por vez ou combinavam informações de maneira rígida que não se adaptava a imagens diferentes. Como resultado, às vezes perdiam detalhes finos, ignoravam direções como “horizontal versus vertical” ou tinham dificuldades quando as imagens estavam ruidosas ou borradas.
Um Complemento de Atenção Mais Inteligente
DMSCA foi projetado como um módulo pequeno e acoplável que pode ser inserido em redes bem conhecidas, como ResNet, sem alterar sua estrutura geral. Internamente, ele coordena seis partes fortemente conectadas que trabalham em conjunto em vez de isoladamente. Uma parte resume a imagem inteira para capturar o que ocorre globalmente, enquanto outra aprende quão importante cada canal interno deve ser, usando uma “temperatura” controlável que pode tornar as decisões mais nítidas ou mais suaves conforme necessário. No lado espacial, DMSCA usa várias larguras de janela simultaneamente para captar tanto texturas minúsculas quanto formas maiores, e presta atenção explícita às direções horizontal e vertical para que arestas longas ou listras não sejam diluídas. Finalmente, em vez de simplesmente somar esses sinais, o módulo aprende, pixel a pixel, quanto confiar nas informações de “o quê” vindas dos canais versus nas informações de “onde” vindas do espaço.
Olhando para Imagens em Múltiplas Escalas e Direções
Para entender onde olhar em uma imagem, o DMSCA primeiro comprime os muitos canais internos em um mapa compacto de duas camadas que destaca tanto tendências de fundo quanto características salientes. Em seguida, passa esse mapa por vários filtros paralelos de tamanhos diferentes. Filtros pequenos captam detalhes finos como pelos ou penas, enquanto filtros maiores capturam formas como cabeças ou corpos inteiros. Em paralelo, uma unidade direcional varre linhas e colunas separadamente, preservando a posição exata de estruturas importantes. Essas visões horizontal e vertical são então permitidas a interagir, de modo que um sinal vertical forte, por exemplo, possa reforçar as localizações horizontais corretas. O resultado é um mapa de atenção rico que informa à rede não apenas que algo é importante, mas onde está e em que escala.
Permitindo que a Rede Decida o que é Mais Relevante
Como diferentes partes de uma imagem podem exigir estratégias distintas, o DMSCA não impõe uma receita fixa para combinar informações de canal e espaciais. Em vez disso, ele constrói uma pequena “porta” que examina ambas e decide—independentemente para cada pixel—quanto peso dar a cada tipo. Em um fundo confuso, o sistema pode confiar mais em quais canais se destacam, enquanto ao redor de bordas nítidas de objetos pode enfatizar pistas espaciais. Uma etapa final de ativação adaptativa então atua como um dimmer aprendido, realçando regiões realmente informativas e atenuando o ruído residual. Esse processo em múltiplas etapas ajuda a direcionar a atenção da rede para regiões coerentes relacionadas a objetos, conforme confirmado por mapas de calor visuais e medidas quantitativas de quão bem as áreas destacadas correspondem aos objetos de referência.
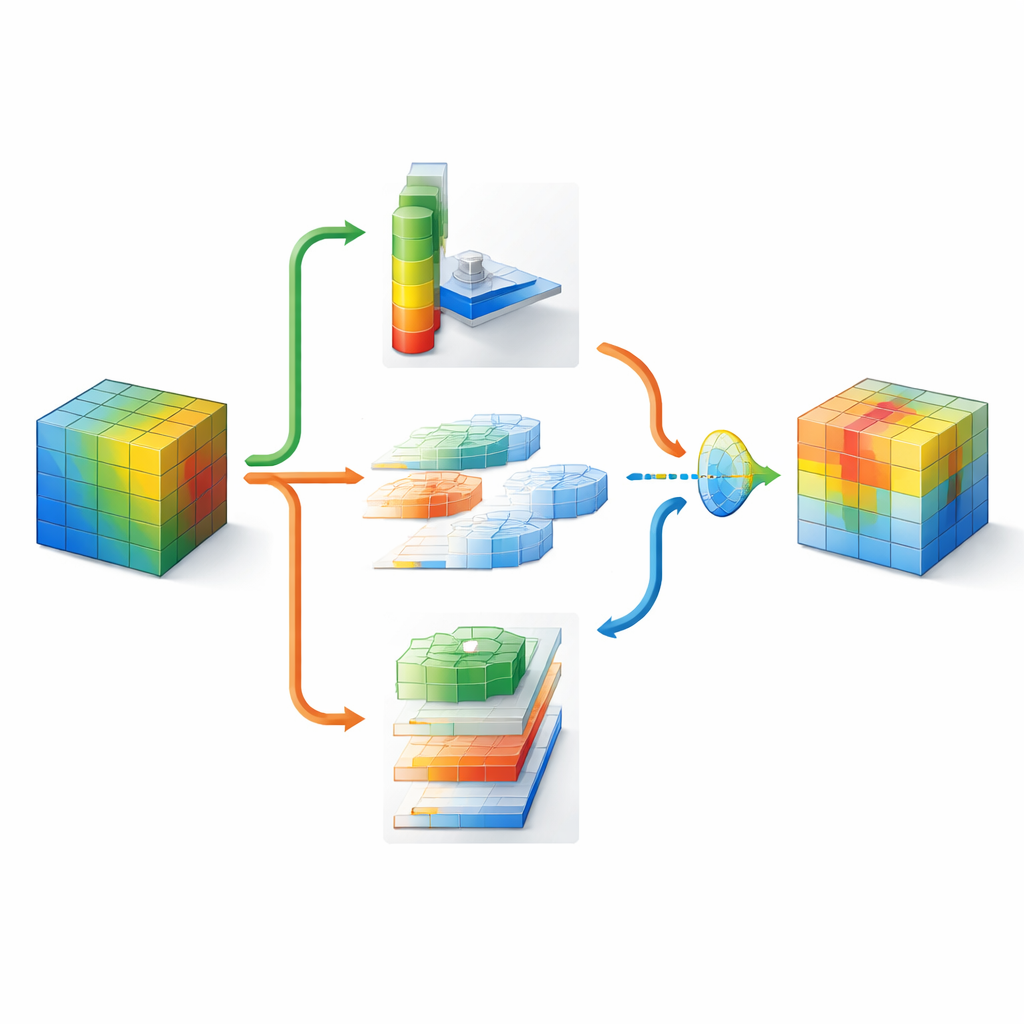
Visão Mais Nítida com Esforço Extra Moderado
Os autores testaram o DMSCA em vários benchmarks padrão, desde coleções pequenas de imagens minúsculas até o conjunto de grande escala ImageNet. Quando adicionada a modelos ResNet populares, o DMSCA melhorou consistentemente a acurácia de classificação—em até cerca de 2 pontos percentuais em conjuntos pequenos e 1,5 ponto percentual no ImageNet—superando uma série de métodos de atenção existentes. Também tornou os modelos mais robustos a degradações comuns de imagem como ruído, desfoque e compactação intensa, e melhorou o desempenho em tarefas relacionadas, como detecção de objetos e rotulagem de cena. Esses ganhos vieram com apenas um aumento modesto em computação e memória. Em termos simples, o DMSCA oferece às redes convolucionais uma forma mais flexível e consciente do contexto para decidir o que olhar e o que ignorar, aproximando a visão de máquina do foco seletivo da visão humana.
Citação: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Palavras-chave: mecanismos de atenção, reconhecimento de imagens, redes neurais convolucionais, representação de recursos, visão computacional robusta