Clear Sky Science · pt
Melhorando a recuperação cross-modal via otimização de gráfico de rótulos e funções de perda híbridas
Buscando com mais inteligência entre imagens e palavras
Cada dia percorremos oceanos de fotos, vídeos e textos. Encontrar exatamente o que queremos — por exemplo, todas as imagens que correspondem a uma legenda curta — depende de quão bem os computadores conseguem conectar imagens à linguagem. Este artigo explora uma nova maneira de tornar essa conexão mais precisa, especialmente em cenas reais e desordenadas onde muitas ideias e objetos aparecem ao mesmo tempo. O resultado são ferramentas de busca mais inteligentes que “entendem” melhor o que queremos, não apenas o que digitamos.
Por que muitos significados em uma única imagem importam
Uma imagem raramente mostra apenas uma coisa. Uma foto de uma baleia saltando no mar pode envolver o oceano, o céu, as ondas, o vento e a vida selvagem ao mesmo tempo. Ao rotular essa imagem, frequentemente atribuímos vários rótulos que se relacionam de maneiras sutis. Sistemas de busca existentes geralmente tratam esses rótulos como se fossem caixas de seleção desconectadas. Essa simplificação descarta pistas úteis: se “baleia” aparece frequentemente com “mar”, então ver um deve aumentar a probabilidade do outro. Este trabalho foca em capturar esses laços ocultos entre rótulos para que uma busca por uma ideia ainda possa encontrar imagens e textos que expressem conceitos intimamente relacionados.

Construindo uma rede de rótulos conectados
Os autores apresentam uma técnica chamada Rede Convolucional em Grafo de Duas Camadas, ou L2-GCN, para modelar como os rótulos se relacionam entre si. Em termos simples, cada rótulo (como “céu” ou “baleia”) é tratado como um ponto em uma rede, e as ligações entre pontos refletem com que frequência esses rótulos aparecem juntos. O método permite repetidamente que cada rótulo “ouça” seus vizinhos, misturando informações de rótulos relacionados enquanto mantém sua própria identidade. Após esse processo, o sistema obtém descrições de rótulos mais ricas que capturam melhor como cenas reais são estruturadas, desde ideias paralelas (“mar” e “praia”) até relações mais hierárquicas (“animal” e “baleia”).
Ensinando imagens e textos a compartilhar um espaço comum
Claro, os rótulos são apenas metade da história; o sistema também precisa aprender a partir das próprias imagens e textos. A estrutura usa ferramentas estabelecidas para transformar pixels brutos e palavras em características numéricas, e então projeta ambos os tipos de dados em um espaço compartilhado onde seus significados podem ser comparados diretamente. Um módulo adversarial — vagamente inspirado na dinâmica de empurrar-puxar de redes adversariais geradoras — desencoraja o modelo a apegar-se a peculiaridades de apenas imagens ou apenas texto. Isso ajuda o espaço comum a focar no conteúdo em vez do formato, de modo que a foto de uma rua movimentada e uma legenda curta que a descreve fiquem próximas nesse mapa comum de significado.
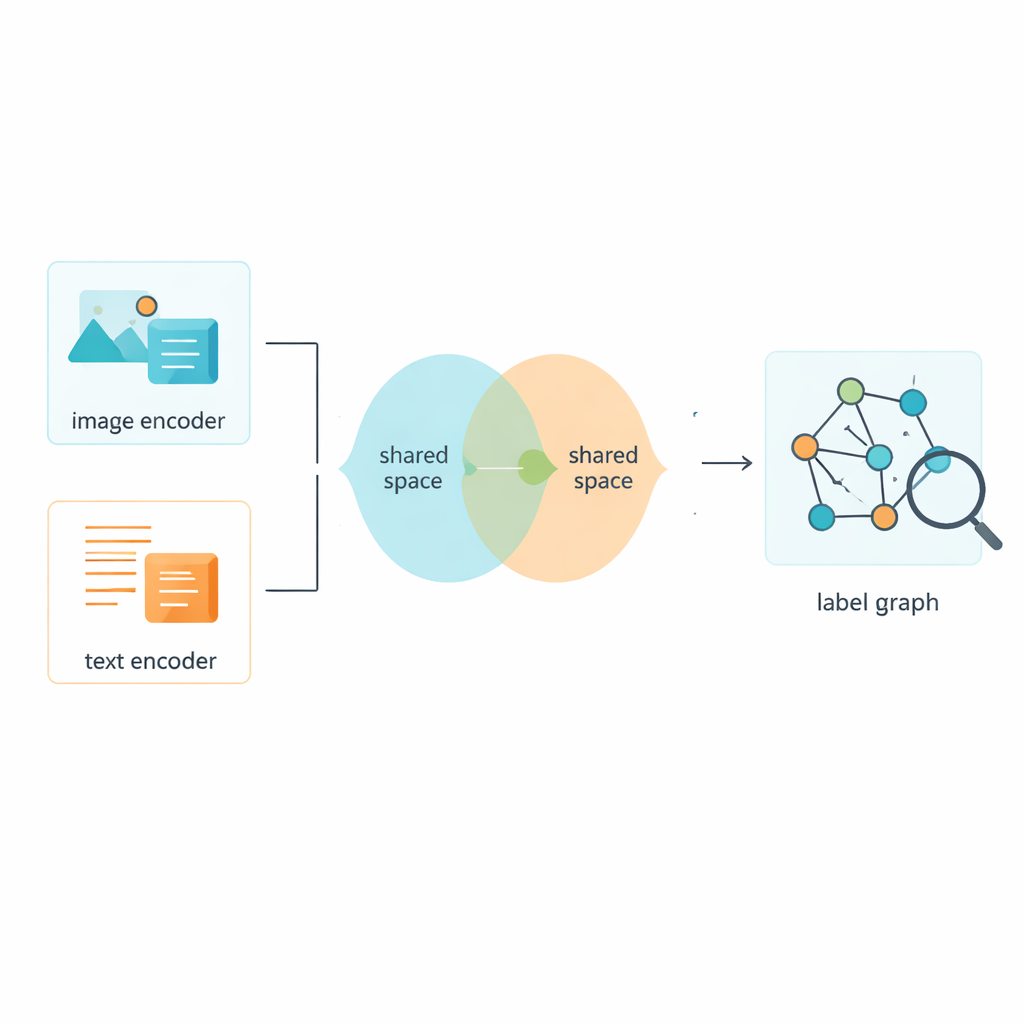
Uma estratégia de treinamento híbrida para distinções mais nítidas
Treinar um sistema assim exige mais de uma regra de aprendizado. Os autores projetam uma função de perda combinada, chamada Circle-Soft, que mistura duas ideias complementares. Uma parte incentiva exemplos da mesma categoria a se agruparem firmemente enquanto afasta categorias diferentes de forma flexível e adaptativa. A outra parte foca em quão bem as imagens e os textos que descrevem a mesma cena se alinham entre os formatos. Um peso ajustável equilibra esses dois objetivos para que o modelo não se ajuste demais nem a limites de categoria muito rígidos nem apenas ao alinhamento cross-modal. Perdas adicionais de classificação e adversariais incentivam ainda mais a consistência entre os rótulos refinados e as características compartilhadas imagem–texto.
Quanto isso melhora a busca?
Para verificar se essas ideias se traduzem em melhor busca, os autores testaram seu método em três coleções populares de pares imagem–texto do mundo real: MIRFlickr, NUS-WIDE e MS-COCO. Esses conjuntos contêm de milhares a centenas de milhares de fotos com tags ou legendas associadas, cobrindo cenas do dia a dia, de ruas da cidade a vida selvagem. Em todos os três benchmarks, a nova abordagem superou consistentemente uma ampla gama de métodos concorrentes, incluindo outros sistemas avançados que já usam modelagem de rótulos baseada em grafos. Os ganhos — cerca de meio ponto percentual a um ponto percentual em uma métrica estrita de recuperação — podem parecer modestos, mas em benchmarks maduros até pequenas melhorias sinalizam uma compreensão mais precisa do conteúdo. Em termos práticos, isso significa que quando um usuário insere uma consulta de texto curta ou envia uma imagem, o sistema tem maior probabilidade de exibir correspondências cross-modal mais relevantes no topo dos resultados.
O que isso significa para os usuários do dia a dia
Para não especialistas, a mensagem principal é que um tratamento mais inteligente dos rótulos e das regras de treinamento pode melhorar visivelmente como máquinas conectam imagens e palavras. Ao tratar rótulos como uma teia interconectada em vez de etiquetas isoladas, e ao moldar cuidadosamente como informação visual e textual se encontram em um espaço compartilhado, essa estrutura torna a busca cross-modal mais confiável em cenas complexas e com múltiplos temas. Ao longo do tempo, técnicas como essa podem alimentar bibliotecas de fotos mais intuitivas, plataformas de mídia e assistentes inteligentes que encontram o que queremos — mesmo quando nossas palavras não coincidem perfeitamente com as imagens que temos em mente.
Citação: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Palavras-chave: recuperação imagem-texto, busca multimodal, redes neurais gráficas, rótulos semânticos, aprendizado de máquina