Clear Sky Science · pt
Uma estrutura de deep learning explicável para detecção de doenças em culturas de arroz e cana-de-açúcar com poucos exemplos usando extração de características baseada em CNN
Por que detectar folhas doentes importa
Arroz e cana-de-açúcar alimentam bilhões de pessoas e sustentam muitas comunidades agrícolas. Quando suas folhas são atacadas por doenças, colheitas inteiras podem encolher, os preços dos alimentos podem subir e os agricultores podem perder seu sustento. No entanto, o diagnóstico precoce é difícil: os problemas frequentemente começam como pequenas manchas ou alterações de cor que agricultores atarefados podem não perceber, e especialistas nem sempre estão por perto. Este estudo apresenta um sistema computacional que pode aprender a partir de apenas um punhado de fotos de folhas, sinalizar doenças automaticamente e até mostrar às pessoas exatamente o que na imagem levou ao diagnóstico, ajudando os agricultores a agir mais cedo e com mais confiança.
Olhos inteligentes para o campo
Os pesquisadores concentram-se em duas culturas básicas: arroz e cana-de-açúcar. Eles utilizam dois conjuntos públicos de imagens de folhas, um capturado em campos reais de cana-de-açúcar usando diversos smartphones e um conjunto menor e mais controlado de fotos de folhas de arroz. Cada imagem mostra uma folha saudável ou com uma doença específica, como manchas marrons, pústulas de cor ferrugem ou estrias amareladas. Ao basear-se nesses conjuntos de dados compartilhados em vez de coleções privadas, a equipe visa métodos que outros grupos possam testar, reutilizar e, eventualmente, incorporar em ferramentas agrícolas reais, desde aplicativos para smartphones até sensores conectados em campos inteligentes.

Ensinando máquinas com pouquíssimos exemplos
A inteligência artificial moderna pode ser notavelmente eficaz em reconhecer doenças de plantas, mas normalmente exige milhares de imagens rotuladas para cada condição — uma exigência difícil na agricultura, especialmente para surtos novos ou raros. Para contornar esse obstáculo, os autores usam aprendizado de poucos exemplares (few-shot), uma família de técnicas projetadas para aprender com apenas um pequeno número de exemplos. Sua estrutura começa com etapas padrão de processamento de imagem: limpeza, redimensionamento e normalização de cada foto para que o computador veja uma visão consistente. Um tipo de modelo de deep learning chamado rede neural convolucional então transforma cada imagem de folha em um conjunto compacto de características numéricas que capturam formas, cores e texturas relevantes para a doença.
Tornando o diagnóstico compreensível
Sobre essas características, a equipe treina dois métodos avançados de few-shot chamados Prototypical Networks e Model-Agnostic Meta-Learning. Um aprende uma espécie de “centro” para cada doença no espaço de características e atribui novas folhas ao centro mais próximo; o outro aprende a se adaptar rapidamente a novas tarefas com apenas alguns passos de treinamento. De forma crucial, os autores combinam esses métodos com ferramentas de IA explicável. Usando técnicas em estilo mapa de calor, o sistema pode destacar quais partes da imagem da folha mais influenciaram sua decisão — um aglomerado de manchas escuras, uma faixa amarela ao longo do nervo central ou a ausência de lesões óbvias em uma planta saudável. Isso torna o raciocínio do modelo visível, permitindo que agrônomos verifiquem se o computador está se concentrando em sinais com significado agronômico em vez de ruídos de fundo.
Como o sistema se sai
Para avaliar se sua abordagem é realmente útil, os pesquisadores a comparam com vários modelos conhecidos de deep learning que já foram usados para detecção de doenças em plantas. Eles dividem cada conjunto de dados em partes de treinamento e teste e medem com que frequência cada método identifica corretamente o tipo de doença. Em folhas de cana-de-açúcar coletadas em campo, a nova estrutura alcança cerca de 92 por cento de classificação correta, superando arquiteturas padrão como VGG, ResNet, Xception e EfficientNet. No conjunto de dados de arroz, o desempenho é ainda melhor, identificando corretamente cerca de 98 por cento das imagens de teste. Ferramentas estatísticas que analisam o equilíbrio entre falsos alarmes e casos perdidos mostram que o novo método se comporta como um excelente triador médico, em vez de um chutador aleatório.
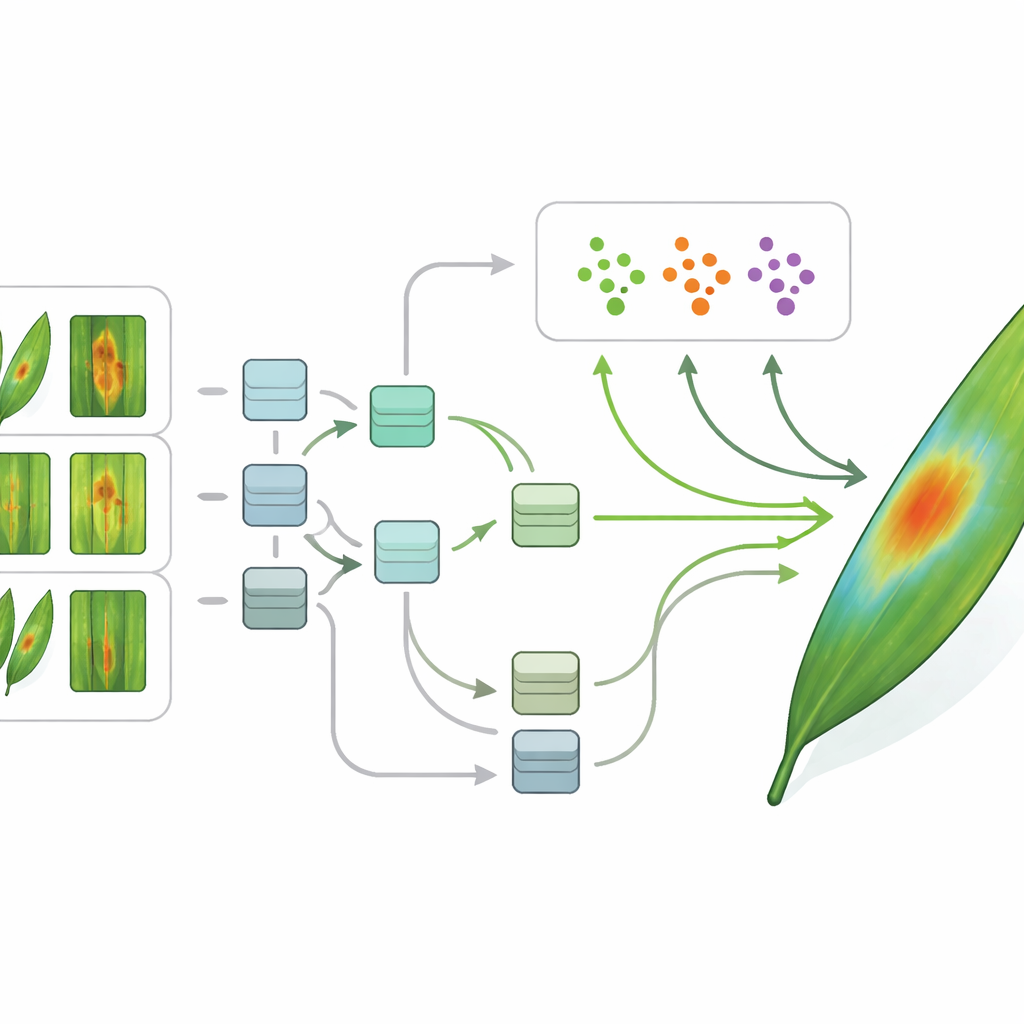
O que isso significa para os agricultores
Em termos simples, o estudo demonstra que um computador pode aprender a detectar várias doenças de arroz e cana-de-açúcar com precisão a partir de apenas um pequeno número de imagens de exemplo, e também pode apontar as manchas e estrias na folha que fundamentaram seu veredicto. Essa combinação de eficiência de dados e transparência é essencial para uso no mundo real: reduz a barreira para construir ferramentas para novas culturas e doenças emergentes e fornece aos agricultores e especialistas evidência visual em que podem confiar. Com testes adicionais em campos reais e interfaces de usuário mais amigáveis, sistemas explicáveis de few-shot poderiam tornar-se parceiros cotidianos na agricultura inteligente, ajudando a proteger colheitas ao mesmo tempo em que reduzem o uso desnecessário de pesticidas.
Citação: El-Behery, H., Attia, AF. & Rezk, N.G. An explainable deep learning framework for few shot crop disease detection in rice and sugarcane using CNN based feature extraction. Sci Rep 16, 8272 (2026). https://doi.org/10.1038/s41598-026-37501-2
Palavras-chave: detecção de doenças em culturas, arroz e cana-de-açúcar, deep learning, IA explicável, agricultura inteligente